 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePR2: Predictive Routing Replay for MoE-Based LLM Reinforcement Learning
May 29, 2026Mixture of Experts (MoE) Large Language Models (LLMs) achieve strong performance at scale. However, reinforcement learning (RL) on MoE-based LLMs often suffers from training instability. A root cause is router drift, i.e., expert activations can change drastically across model updates and differ between disaggregated rollout and training phases, causing large rollout--training mismatch and unstable importance sampling weights in PPO-style RL algorithms. Routing replay mitigates this issue by freezing the replay route within each reasoning trajectory, but it ignores how the router evolves under off-policy updates and thus causes router staleness. To address this limitation, we propose Predictive Routing Replay (PR2), which augments each router with a lightweight evolution predictor that learns to anticipate short-horizon router evolution. During the rollout phase, we use the predictive routing distribution to apply top-$k$ routing, enabling gradients to reach experts that are likely to become active after updates. During the training phase, we replay the resulting predicted route to retain consistency for stable importance estimation. Theoretical analysis and experiments support that PR2 reduces routing-induced mismatch, improves RL stability, and yields stronger performance across various reasoning benchmarks.
ExFusion: Efficient Transformer Training via Multi-Experts Fusion
Mar 30, 2026Mixture-of-Experts (MoE) models substantially improve performance by increasing the capacity of dense architectures. However, directly training MoE models requires considerable computational resources and introduces extra overhead in parameter storage and deployment. Therefore, it is critical to develop an approach that leverages the multi-expert capability of MoE to enhance performance while incurring minimal additional cost. To this end, we propose a novel pre-training approach, termed ExFusion, which improves the efficiency of Transformer training through multi-expert fusion. Specifically, during the initialization phase, ExFusion upcycles the feed-forward network (FFN) of the Transformer into a multi-expert configuration, where each expert is assigned a weight for later parameter fusion. During training, these weights allow multiple experts to be fused into a single unified expert equivalent to the original FFN, which is subsequently used for forward computation. As a result, ExFusion introduces multi-expert characteristics into the training process while incurring only marginal computational cost compared to standard dense training. After training, the learned weights are used to integrate multi-experts into a single unified expert, thereby eliminating additional overhead in storage and deployment. Extensive experiments on a variety of computer vision and natural language processing tasks demonstrate the effectiveness of the proposed method.
LLaMA-MoE v2: Exploring Sparsity of LLaMA from Perspective of Mixture-of-Experts with Post-Training
Nov 24, 2024Recently, inspired by the concept of sparsity, Mixture-of-Experts (MoE) models have gained increasing popularity for scaling model size while keeping the number of activated parameters constant. In this study, we thoroughly investigate the sparsity of the dense LLaMA model by constructing MoE for both the attention (i.e., Attention MoE) and MLP (i.e., MLP MoE) modules in the transformer blocks. Specifically, we investigate different expert construction methods and granularities under the same activation conditions to analyze the impact of sparsifying the model. Additionally, to comprehensively evaluate the model's capabilities across various domains (e.g., conversation, code, math) after sparsification, we apply sparsity to the instructed large language models (LLMs) and construct instructed MoE models. To counteract the performance degradation resulting from increased sparsity, we design a two-stage post-training strategy to enhance model performance. Experiments on the LLaMA3 model demonstrate the potential effectiveness of this approach for future developments of instructed MoE models. The source codes and models are available at: \url{https://github.com/OpenSparseLLMs/LLaMA-MoE-v2}.
LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training
Jun 24, 2024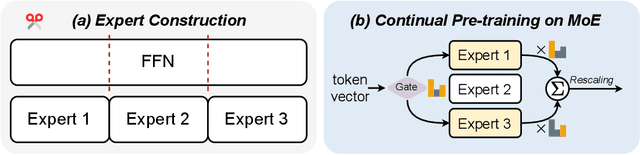


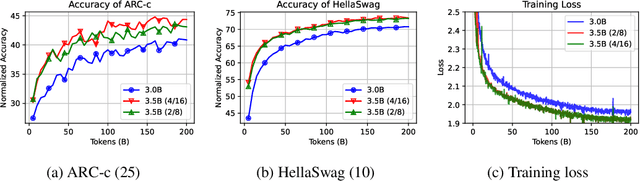
Mixture-of-Experts (MoE) has gained increasing popularity as a promising framework for scaling up large language models (LLMs). However, training MoE from scratch in a large-scale setting still suffers from data-hungry and instability problems. Motivated by this limit, we investigate building MoE models from existing dense large language models. Specifically, based on the well-known LLaMA-2 7B model, we obtain an MoE model by: (1) Expert Construction, which partitions the parameters of original Feed-Forward Networks (FFNs) into multiple experts; (2) Continual Pre-training, which further trains the transformed MoE model and additional gate networks. In this paper, we comprehensively explore different methods for expert construction and various data sampling strategies for continual pre-training. After these stages, our LLaMA-MoE models could maintain language abilities and route the input tokens to specific experts with part of the parameters activated. Empirically, by training 200B tokens, LLaMA-MoE-3.5B models significantly outperform dense models that contain similar activation parameters. The source codes and models are available at https://github.com/pjlab-sys4nlp/llama-moe .
Dynamic Data Mixing Maximizes Instruction Tuning for Mixture-of-Experts
Jun 17, 2024



Mixture-of-Experts (MoE) models have shown remarkable capability in instruction tuning, especially when the number of tasks scales. However, previous methods simply merge all training tasks (e.g. creative writing, coding, and mathematics) and apply fixed sampling weights, without considering the importance of different tasks as the model training state changes. In this way, the most helpful data cannot be effectively distinguished, leading to suboptimal model performance. To reduce the potential redundancies of datasets, we make the first attempt and propose a novel dynamic data mixture for MoE instruction tuning. Specifically, inspired by MoE's token routing preference, we build dataset-level representations and then capture the subtle differences among datasets. Finally, we propose to dynamically adjust the sampling weight of datasets by their inter-redundancies, thus maximizing global performance under a limited training budget. The experimental results on two MoE models demonstrate the effectiveness of our approach on both downstream knowledge \& reasoning tasks and open-ended queries. Code and models are available at https://github.com/Spico197/MoE-SFT .
Demystifying the Compression of Mixture-of-Experts Through a Unified Framework
Jun 04, 2024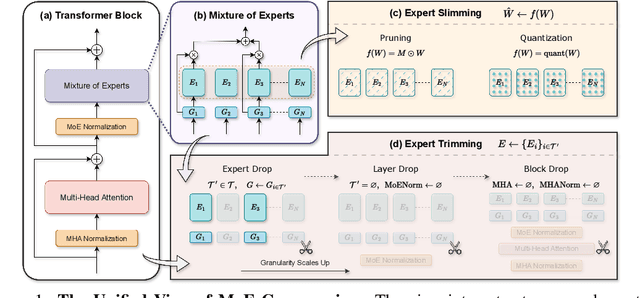

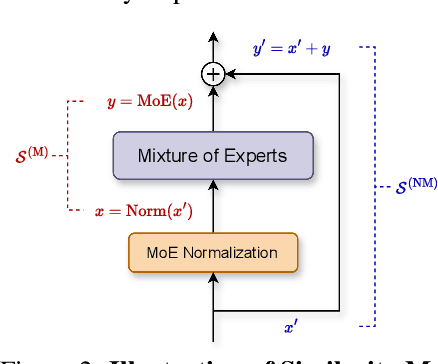
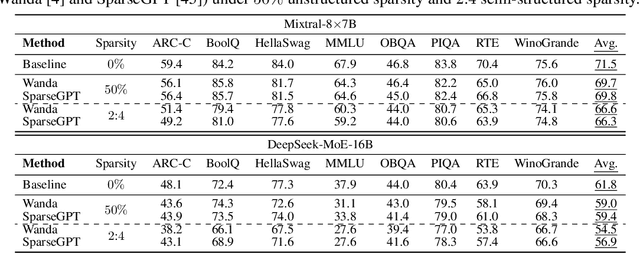
Scaling large language models has revolutionized the performance across diverse domains, yet the continual growth in model size poses significant challenges for real-world deployment. The Mixture of Experts (MoE) approach addresses this by dynamically selecting and activating only a subset of experts, significantly reducing computational costs while maintaining high performance. However, MoE introduces potential redundancy (e.g., parameters) and extra costs (e.g., communication overhead). Despite numerous compression techniques developed for mitigating the redundancy in dense models, the compression of MoE remains under-explored. We first bridge this gap with a cutting-edge unified framework that not only seamlessly integrates mainstream compression methods but also helps systematically understand MoE compression. This framework approaches compression from two perspectives: Expert Slimming which compresses individual experts and Expert Trimming which removes structured modules. Within this framework, we explore the optimization space unexplored by existing methods,and further introduce aggressive Expert Trimming techniques, i.e., Layer Drop and Block Drop, to eliminate redundancy at larger scales. Based on these insights,we present a comprehensive recipe to guide practitioners in compressing MoE effectively. Extensive experimental results demonstrate the effectiveness of the compression methods under our framework and the proposed recipe, achieving a 6.05x speedup and only 20.0GB memory usage while maintaining over 92% of performance on Mixtral-8x7B.
iDAT: inverse Distillation Adapter-Tuning
Mar 23, 2024Adapter-Tuning (AT) method involves freezing a pre-trained model and introducing trainable adapter modules to acquire downstream knowledge, thereby calibrating the model for better adaptation to downstream tasks. This paper proposes a distillation framework for the AT method instead of crafting a carefully designed adapter module, which aims to improve fine-tuning performance. For the first time, we explore the possibility of combining the AT method with knowledge distillation. Via statistical analysis, we observe significant differences in the knowledge acquisition between adapter modules of different models. Leveraging these differences, we propose a simple yet effective framework called inverse Distillation Adapter-Tuning (iDAT). Specifically, we designate the smaller model as the teacher and the larger model as the student. The two are jointly trained, and online knowledge distillation is applied to inject knowledge of different perspective to student model, and significantly enhance the fine-tuning performance on downstream tasks. Extensive experiments on the VTAB-1K benchmark with 19 image classification tasks demonstrate the effectiveness of iDAT. The results show that using existing AT method within our iDAT framework can further yield a 2.66% performance gain, with only an additional 0.07M trainable parameters. Our approach compares favorably with state-of-the-arts without bells and whistles. Our code is available at https://github.com/JCruan519/iDAT.
A Graph is Worth $K$ Words: Euclideanizing Graph using Pure Transformer
Feb 04, 2024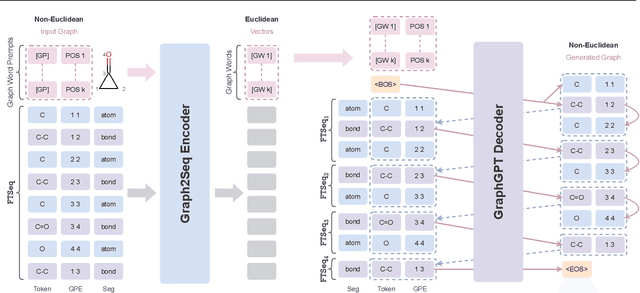
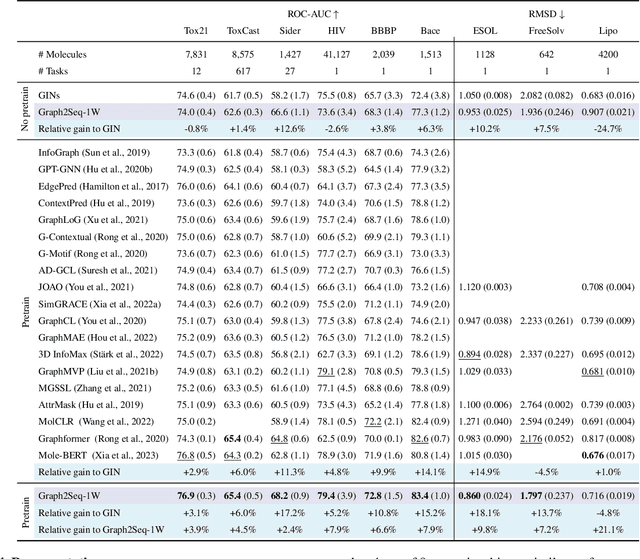
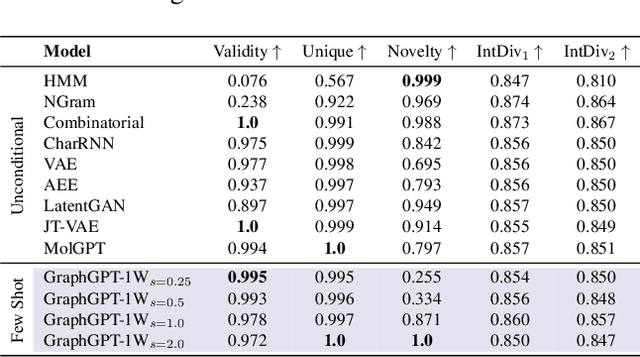

Can we model non-Euclidean graphs as pure language or even Euclidean vectors while retaining their inherent information? The non-Euclidean property have posed a long term challenge in graph modeling. Despite recent GNN and Graphformer efforts encoding graphs as Euclidean vectors, recovering original graph from the vectors remains a challenge. We introduce GraphsGPT, featuring a Graph2Seq encoder that transforms non-Euclidean graphs into learnable graph words in a Euclidean space, along with a GraphGPT decoder that reconstructs the original graph from graph words to ensure information equivalence. We pretrain GraphsGPT on 100M molecules and yield some interesting findings: (1) Pretrained Graph2Seq excels in graph representation learning, achieving state-of-the-art results on 8/9 graph classification and regression tasks. (2) Pretrained GraphGPT serves as a strong graph generator, demonstrated by its ability to perform both unconditional and conditional graph generation. (3) Graph2Seq+GraphGPT enables effective graph mixup in the Euclidean space, overcoming previously known non-Euclidean challenge. (4) Our proposed novel edge-centric GPT pretraining task is effective in graph fields, underscoring its success in both representation and generation.
Cherry Hypothesis: Identifying the Cherry on the Cake for Dynamic Networks
Nov 10, 2022



Dynamic networks have been extensively explored as they can considerably improve the model's representation power with acceptable computational cost. The common practice in implementing dynamic networks is to convert given static layers into fully dynamic ones where all parameters are dynamic and vary with the input. Recent studies empirically show the trend that the more dynamic layers contribute to ever-increasing performance. However, such a fully dynamic setting 1) may cause redundant parameters and high deployment costs, limiting the applicability of dynamic networks to a broader range of tasks and models, and more importantly, 2) contradicts the previous discovery in the human brain that \textit{when human brains process an attention-demanding task, only partial neurons in the task-specific areas are activated by the input, while the rest neurons leave in a baseline state.} Critically, there is no effort to understand and resolve the above contradictory finding, leaving the primal question -- to make the computational parameters fully dynamic or not? -- unanswered. The main contributions of our work are challenging the basic commonsense in dynamic networks, and, proposing and validating the \textsc{cherry hypothesis} -- \textit{A fully dynamic network contains a subset of dynamic parameters that when transforming other dynamic parameters into static ones, can maintain or even exceed the performance of the original network.} Technically, we propose a brain-inspired partially dynamic network, namely PAD-Net, to transform the redundant dynamic parameters into static ones. Also, we further design Iterative Mode Partition to partition the dynamic- and static-subnet, which alleviates the redundancy in traditional fully dynamic networks. Our hypothesis and method are comprehensively supported by large-scale experiments with typical advanced dynamic methods.
SparseAdapter: An Easy Approach for Improving the Parameter-Efficiency of Adapters
Oct 11, 2022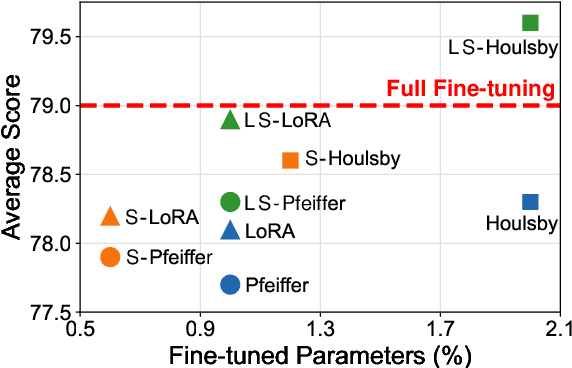

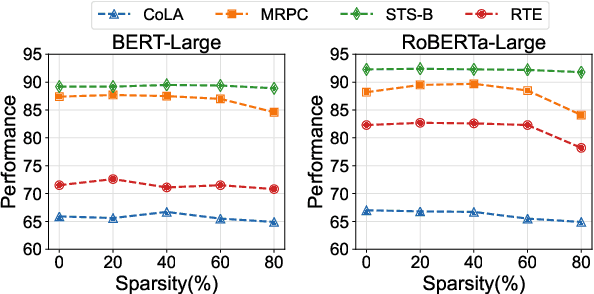
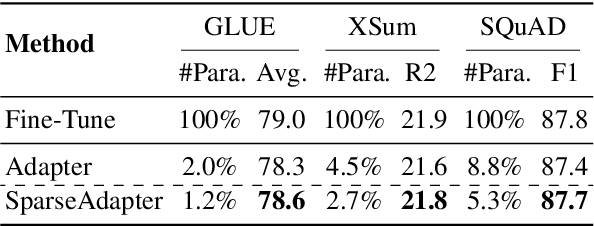
Adapter Tuning, which freezes the pretrained language models (PLMs) and only fine-tunes a few extra modules, becomes an appealing efficient alternative to the full model fine-tuning. Although computationally efficient, the recent Adapters often increase parameters (e.g. bottleneck dimension) for matching the performance of full model fine-tuning, which we argue goes against their original intention. In this work, we re-examine the parameter-efficiency of Adapters through the lens of network pruning (we name such plug-in concept as \texttt{SparseAdapter}) and find that SparseAdapter can achieve comparable or better performance than standard Adapters when the sparse ratio reaches up to 80\%. Based on our findings, we introduce an easy but effective setting ``\textit{Large-Sparse}'' to improve the model capacity of Adapters under the same parameter budget. Experiments on five competitive Adapters upon three advanced PLMs show that with proper sparse method (e.g. SNIP) and ratio (e.g. 40\%) SparseAdapter can consistently outperform their corresponding counterpart. Encouragingly, with the \textit{Large-Sparse} setting, we can obtain further appealing gains, even outperforming the full fine-tuning by a large margin. Our code will be released at: \url{https://github.com/Shwai-He/SparseAdapter}.