 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Compression of Mixture-of-Experts Through a Unified Framework
Paper and Code
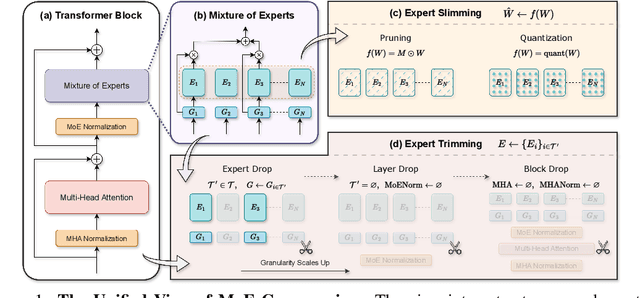

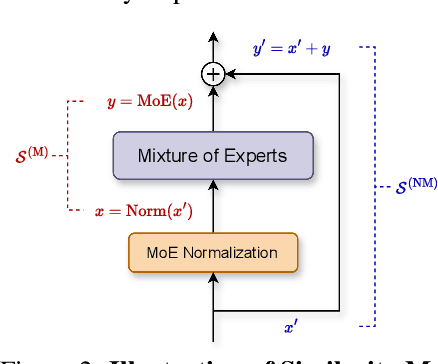
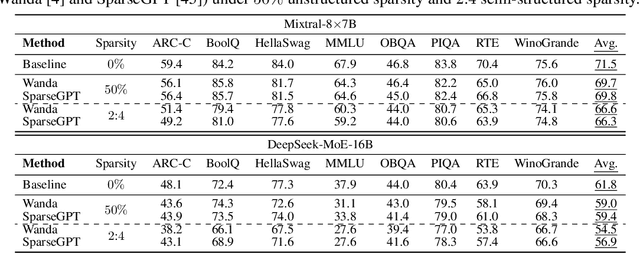
Scaling large language models has revolutionized the performance across diverse domains, yet the continual growth in model size poses significant challenges for real-world deployment. The Mixture of Experts (MoE) approach addresses this by dynamically selecting and activating only a subset of experts, significantly reducing computational costs while maintaining high performance. However, MoE introduces potential redundancy (e.g., parameters) and extra costs (e.g., communication overhead). Despite numerous compression techniques developed for mitigating the redundancy in dense models, the compression of MoE remains under-explored. We first bridge this gap with a cutting-edge unified framework that not only seamlessly integrates mainstream compression methods but also helps systematically understand MoE compression. This framework approaches compression from two perspectives: Expert Slimming which compresses individual experts and Expert Trimming which removes structured modules. Within this framework, we explore the optimization space unexplored by existing methods,and further introduce aggressive Expert Trimming techniques, i.e., Layer Drop and Block Drop, to eliminate redundancy at larger scales. Based on these insights,we present a comprehensive recipe to guide practitioners in compressing MoE effectively. Extensive experimental results demonstrate the effectiveness of the compression methods under our framework and the proposed recipe, achieving a 6.05x speedup and only 20.0GB memory usage while maintaining over 92% of performance on Mixtral-8x7B.