 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseAdapter: An Easy Approach for Improving the Parameter-Efficiency of Adapters
Paper and Code
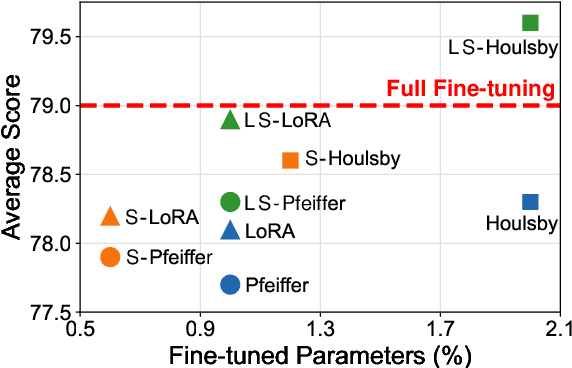

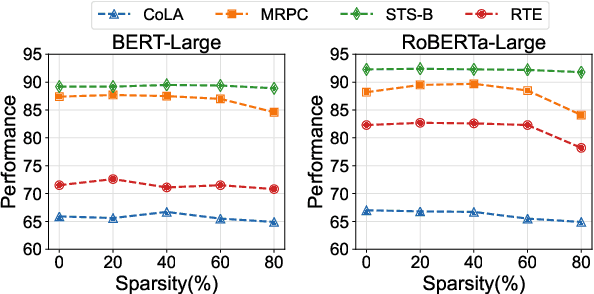
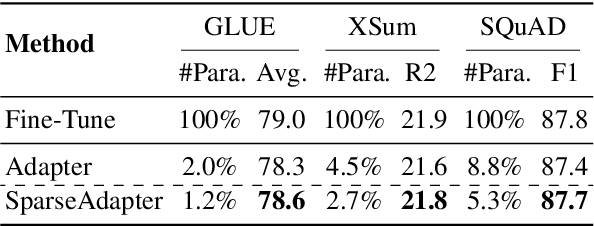
Adapter Tuning, which freezes the pretrained language models (PLMs) and only fine-tunes a few extra modules, becomes an appealing efficient alternative to the full model fine-tuning. Although computationally efficient, the recent Adapters often increase parameters (e.g. bottleneck dimension) for matching the performance of full model fine-tuning, which we argue goes against their original intention. In this work, we re-examine the parameter-efficiency of Adapters through the lens of network pruning (we name such plug-in concept as \texttt{SparseAdapter}) and find that SparseAdapter can achieve comparable or better performance than standard Adapters when the sparse ratio reaches up to 80\%. Based on our findings, we introduce an easy but effective setting ``\textit{Large-Sparse}'' to improve the model capacity of Adapters under the same parameter budget. Experiments on five competitive Adapters upon three advanced PLMs show that with proper sparse method (e.g. SNIP) and ratio (e.g. 40\%) SparseAdapter can consistently outperform their corresponding counterpart. Encouragingly, with the \textit{Large-Sparse} setting, we can obtain further appealing gains, even outperforming the full fine-tuning by a large margin. Our code will be released at: \url{https://github.com/Shwai-He/SparseAdapter}.