 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph of AI Ideas: Leveraging Knowledge Graphs and LLMs for AI Research Idea Generation
Mar 11, 2025Reading relevant scientific papers and analyzing research development trends is a critical step in generating new scientific ideas. However, the rapid increase in the volume of research literature and the complex citation relationships make it difficult for researchers to quickly analyze and derive meaningful research trends. The development of large language models (LLMs) has provided a novel approach for automatically summarizing papers and generating innovative research ideas. However, existing paper-based idea generation methods either simply input papers into LLMs via prompts or form logical chains of creative development based on citation relationships, without fully exploiting the semantic information embedded in these citations. Inspired by knowledge graphs and human cognitive processes, we propose a framework called the Graph of AI Ideas (GoAI) for the AI research field, which is dominated by open-access papers. This framework organizes relevant literature into entities within a knowledge graph and summarizes the semantic information contained in citations into relations within the graph. This organization effectively reflects the relationships between two academic papers and the advancement of the AI research field. Such organization aids LLMs in capturing the current progress of research, thereby enhancing their creativity. Experimental results demonstrate the effectiveness of our approach in generating novel, clear, and effective research ideas.
From Motion Signals to Insights: A Unified Framework for Student Behavior Analysis and Feedback in Physical Education Classes
Mar 09, 2025



Analyzing student behavior in educational scenarios is crucial for enhancing teaching quality and student engagement. Existing AI-based models often rely on classroom video footage to identify and analyze student behavior. While these video-based methods can partially capture and analyze student actions, they struggle to accurately track each student's actions in physical education classes, which take place in outdoor, open spaces with diverse activities, and are challenging to generalize to the specialized technical movements involved in these settings. Furthermore, current methods typically lack the ability to integrate specialized pedagogical knowledge, limiting their ability to provide in-depth insights into student behavior and offer feedback for optimizing instructional design. To address these limitations, we propose a unified end-to-end framework that leverages human activity recognition technologies based on motion signals, combined with advanced large language models, to conduct more detailed analyses and feedback of student behavior in physical education classes. Our framework begins with the teacher's instructional designs and the motion signals from students during physical education sessions, ultimately generating automated reports with teaching insights and suggestions for improving both learning and class instructions. This solution provides a motion signal-based approach for analyzing student behavior and optimizing instructional design tailored to physical education classes. Experimental results demonstrate that our framework can accurately identify student behaviors and produce meaningful pedagogical insights.
Understanding Robustness of Parameter-Efficient Tuning for Image Classification
Oct 13, 2024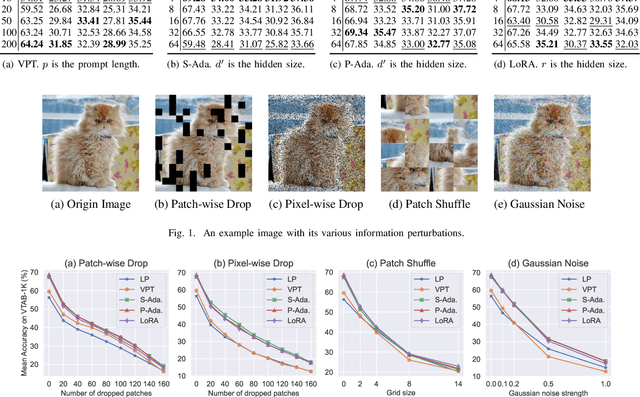

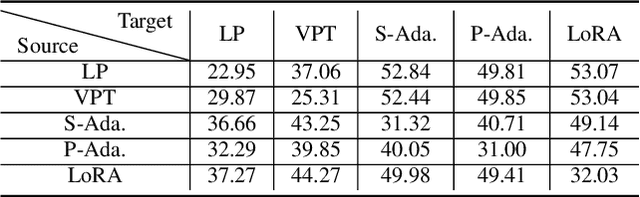

Parameter-efficient tuning (PET) techniques calibrate the model's predictions on downstream tasks by freezing the pre-trained models and introducing a small number of learnable parameters. However, despite the numerous PET methods proposed, their robustness has not been thoroughly investigated. In this paper, we systematically explore the robustness of four classical PET techniques (e.g., VPT, Adapter, AdaptFormer, and LoRA) under both white-box attacks and information perturbations. For white-box attack scenarios, we first analyze the performance of PET techniques using FGSM and PGD attacks. Subsequently, we further explore the transferability of adversarial samples and the impact of learnable parameter quantities on the robustness of PET methods. Under information perturbation attacks, we introduce four distinct perturbation strategies, including Patch-wise Drop, Pixel-wise Drop, Patch Shuffle, and Gaussian Noise, to comprehensively assess the robustness of these PET techniques in the presence of information loss. Via these extensive studies, we enhance the understanding of the robustness of PET methods, providing valuable insights for improving their performance in computer vision applications. The code is available at https://github.com/JCruan519/PETRobustness.
iDAT: inverse Distillation Adapter-Tuning
Mar 23, 2024Adapter-Tuning (AT) method involves freezing a pre-trained model and introducing trainable adapter modules to acquire downstream knowledge, thereby calibrating the model for better adaptation to downstream tasks. This paper proposes a distillation framework for the AT method instead of crafting a carefully designed adapter module, which aims to improve fine-tuning performance. For the first time, we explore the possibility of combining the AT method with knowledge distillation. Via statistical analysis, we observe significant differences in the knowledge acquisition between adapter modules of different models. Leveraging these differences, we propose a simple yet effective framework called inverse Distillation Adapter-Tuning (iDAT). Specifically, we designate the smaller model as the teacher and the larger model as the student. The two are jointly trained, and online knowledge distillation is applied to inject knowledge of different perspective to student model, and significantly enhance the fine-tuning performance on downstream tasks. Extensive experiments on the VTAB-1K benchmark with 19 image classification tasks demonstrate the effectiveness of iDAT. The results show that using existing AT method within our iDAT framework can further yield a 2.66% performance gain, with only an additional 0.07M trainable parameters. Our approach compares favorably with state-of-the-arts without bells and whistles. Our code is available at https://github.com/JCruan519/iDAT.
Learning Multi-axis Representation in Frequency Domain for Medical Image Segmentation
Dec 28, 2023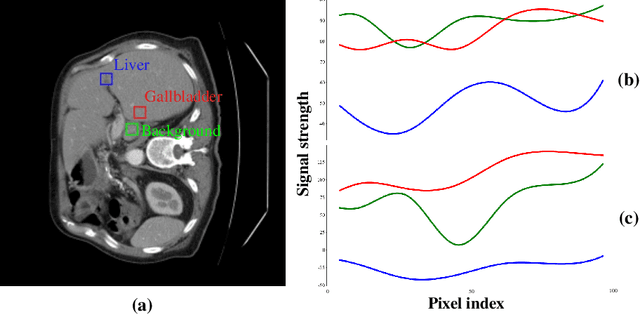
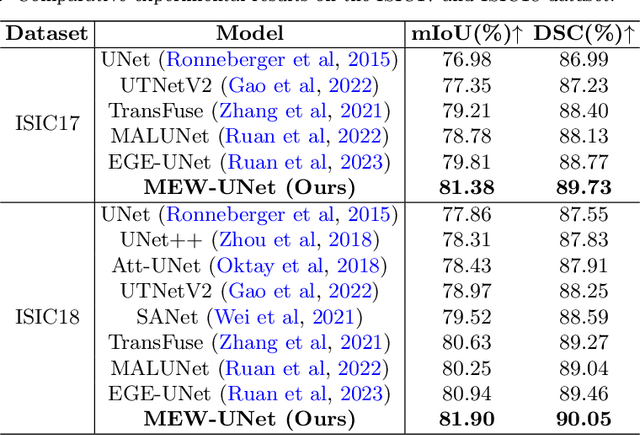
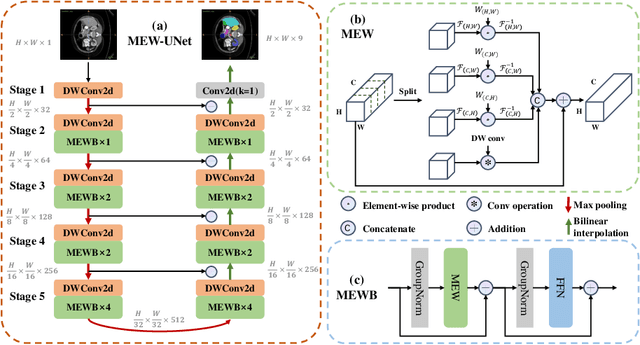
Recently, Visual Transformer (ViT) has been extensively used in medical image segmentation (MIS) due to applying self-attention mechanism in the spatial domain to modeling global knowledge. However, many studies have focused on improving models in the spatial domain while neglecting the importance of frequency domain information. Therefore, we propose Multi-axis External Weights UNet (MEW-UNet) based on the U-shape architecture by replacing self-attention in ViT with our Multi-axis External Weights block. Specifically, our block performs a Fourier transform on the three axes of the input features and assigns the external weight in the frequency domain, which is generated by our External Weights Generator. Then, an inverse Fourier transform is performed to change the features back to the spatial domain. We evaluate our model on four datasets, including Synapse, ACDC, ISIC17 and ISIC18 datasets, and our approach demonstrates competitive performance, owing to its effective utilization of frequency domain information.
LAMM: Label Alignment for Multi-Modal Prompt Learning
Dec 13, 2023



With the success of pre-trained visual-language (VL) models such as CLIP in visual representation tasks, transferring pre-trained models to downstream tasks has become a crucial paradigm. Recently, the prompt tuning paradigm, which draws inspiration from natural language processing (NLP), has made significant progress in VL field. However, preceding methods mainly focus on constructing prompt templates for text and visual inputs, neglecting the gap in class label representations between the VL models and downstream tasks. To address this challenge, we introduce an innovative label alignment method named \textbf{LAMM}, which can dynamically adjust the category embeddings of downstream datasets through end-to-end training. Moreover, to achieve a more appropriate label distribution, we propose a hierarchical loss, encompassing the alignment of the parameter space, feature space, and logits space. We conduct experiments on 11 downstream vision datasets and demonstrate that our method significantly improves the performance of existing multi-modal prompt learning models in few-shot scenarios, exhibiting an average accuracy improvement of 2.31(\%) compared to the state-of-the-art methods on 16 shots. Moreover, our methodology exhibits the preeminence in continual learning compared to other prompt tuning methods. Importantly, our method is synergistic with existing prompt tuning methods and can boost the performance on top of them. Our code and dataset will be publicly available at https://github.com/gaojingsheng/LAMM.
GIST: Improving Parameter Efficient Fine Tuning via Knowledge Interaction
Dec 12, 2023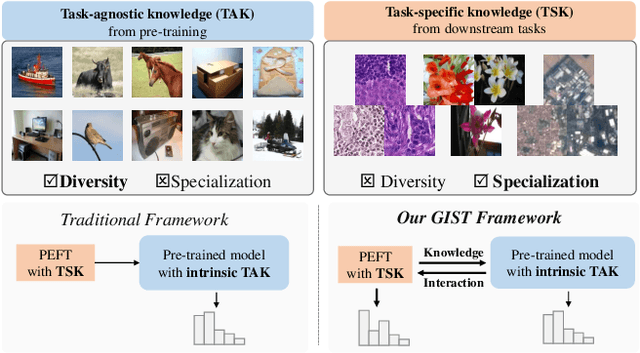
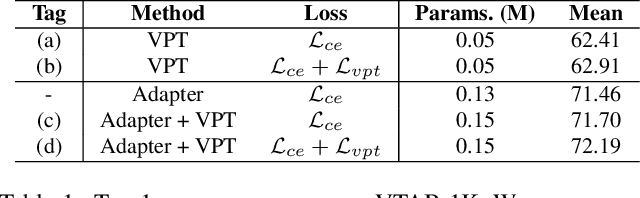
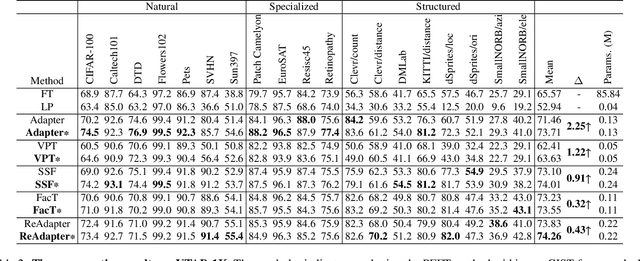
The Parameter-Efficient Fine-Tuning (PEFT) method, which adjusts or introduces fewer trainable parameters to calibrate pre-trained models on downstream tasks, has become a recent research interest. However, existing PEFT methods within the traditional fine-tiuning framework have two main shortcomings: 1) They overlook the explicit association between trainable parameters and downstream task knowledge. 2) They neglect the interaction between the intrinsic task-agnostic knowledge of pre-trained models and the task-specific knowledge in downstream tasks. To address this gap, we propose a novel fine-tuning framework, named GIST, in a plug-and-play manner. Specifically, our framework first introduces a trainable token, called the Gist token, when applying PEFT methods on downstream tasks. This token serves as an aggregator of the task-specific knowledge learned by the PEFT methods and forms an explicit association with downstream knowledge. Furthermore, to facilitate explicit interaction between task-agnostic and task-specific knowledge, we introduce the concept of Knowledge Interaction via a Bidirectional Kullback-Leibler Divergence objective. As a result, PEFT methods within our framework can make the pre-trained model understand downstream tasks more comprehensively by leveraging the knowledge interaction. Extensive experiments demonstrate the universality and scalability of our framework. Notably, on the VTAB-1K benchmark, we employ the Adapter (a prevalent PEFT method) within our GIST framework and achieve a performance boost of 2.25%, with an increase of only 0.8K parameters. The Code will be released.
EGE-UNet: an Efficient Group Enhanced UNet for skin lesion segmentation
Jul 17, 2023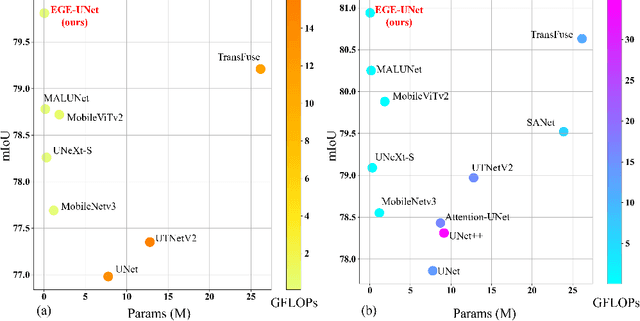
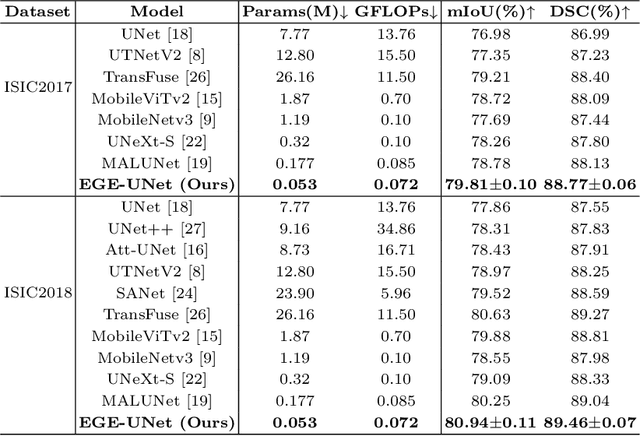
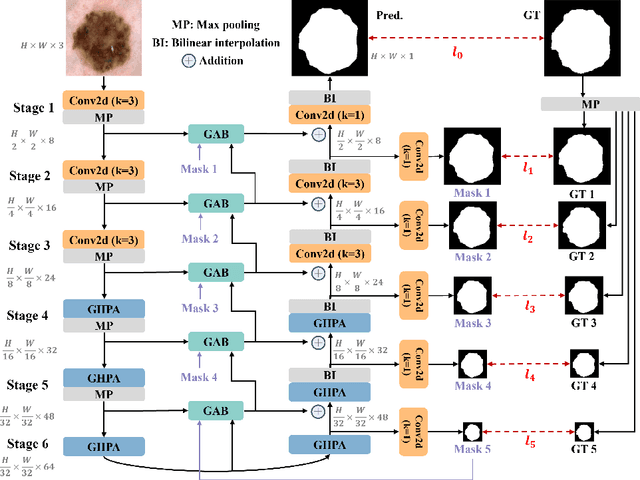
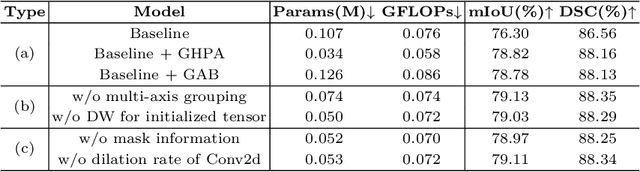
Transformer and its variants have been widely used for medical image segmentation. However, the large number of parameter and computational load of these models make them unsuitable for mobile health applications. To address this issue, we propose a more efficient approach, the Efficient Group Enhanced UNet (EGE-UNet). We incorporate a Group multi-axis Hadamard Product Attention module (GHPA) and a Group Aggregation Bridge module (GAB) in a lightweight manner. The GHPA groups input features and performs Hadamard Product Attention mechanism (HPA) on different axes to extract pathological information from diverse perspectives. The GAB effectively fuses multi-scale information by grouping low-level features, high-level features, and a mask generated by the decoder at each stage. Comprehensive experiments on the ISIC2017 and ISIC2018 datasets demonstrate that EGE-UNet outperforms existing state-of-the-art methods. In short, compared to the TransFuse, our model achieves superior segmentation performance while reducing parameter and computation costs by 494x and 160x, respectively. Moreover, to our best knowledge, this is the first model with a parameter count limited to just 50KB. Our code is available at https://github.com/JCruan519/EGE-UNet.
MALUNet: A Multi-Attention and Light-weight UNet for Skin Lesion Segmentation
Nov 03, 2022Recently, some pioneering works have preferred applying more complex modules to improve segmentation performances. However, it is not friendly for actual clinical environments due to limited computing resources. To address this challenge, we propose a light-weight model to achieve competitive performances for skin lesion segmentation at the lowest cost of parameters and computational complexity so far. Briefly, we propose four modules: (1) DGA consists of dilated convolution and gated attention mechanisms to extract global and local feature information; (2) IEA, which is based on external attention to characterize the overall datasets and enhance the connection between samples; (3) CAB is composed of 1D convolution and fully connected layers to perform a global and local fusion of multi-stage features to generate attention maps at channel axis; (4) SAB, which operates on multi-stage features by a shared 2D convolution to generate attention maps at spatial axis. We combine four modules with our U-shape architecture and obtain a light-weight medical image segmentation model dubbed as MALUNet. Compared with UNet, our model improves the mIoU and DSC metrics by 2.39% and 1.49%, respectively, with a 44x and 166x reduction in the number of parameters and computational complexity. In addition, we conduct comparison experiments on two skin lesion segmentation datasets (ISIC2017 and ISIC2018). Experimental results show that our model achieves state-of-the-art in balancing the number of parameters, computational complexity and segmentation performances. Code is available at https://github.com/JCruan519/MALUNet.
MEW-UNet: Multi-axis representation learning in frequency domain for medical image segmentation
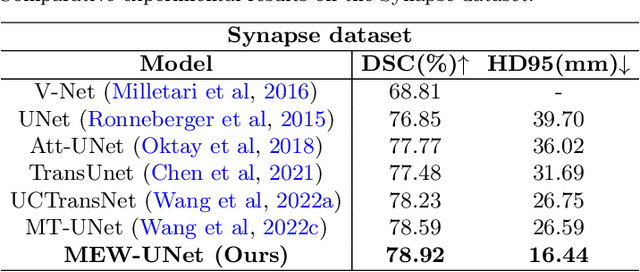
Oct 25, 2022Recently, Visual Transformer (ViT) has been widely used in various fields of computer vision due to applying self-attention mechanism in the spatial domain to modeling global knowledge. Especially in medical image segmentation (MIS), many works are devoted to combining ViT and CNN, and even some works directly utilize pure ViT-based models. However, recent works improved models in the aspect of spatial domain while ignoring the importance of frequency domain information. Therefore, we propose Multi-axis External Weights UNet (MEW-UNet) for MIS based on the U-shape architecture by replacing self-attention in ViT with our Multi-axis External Weights block. Specifically, our block performs a Fourier transform on the three axes of the input feature and assigns the external weight in the frequency domain, which is generated by our Weights Generator. Then, an inverse Fourier transform is performed to change the features back to the spatial domain. We evaluate our model on four datasets and achieve state-of-the-art performances. In particular, on the Synapse dataset, our method outperforms MT-UNet by 10.15mm in terms of HD95. Code is available at https://github.com/JCruan519/MEW-UNet.