 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMM: Label Alignment for Multi-Modal Prompt Learning
Dec 13, 2023



With the success of pre-trained visual-language (VL) models such as CLIP in visual representation tasks, transferring pre-trained models to downstream tasks has become a crucial paradigm. Recently, the prompt tuning paradigm, which draws inspiration from natural language processing (NLP), has made significant progress in VL field. However, preceding methods mainly focus on constructing prompt templates for text and visual inputs, neglecting the gap in class label representations between the VL models and downstream tasks. To address this challenge, we introduce an innovative label alignment method named \textbf{LAMM}, which can dynamically adjust the category embeddings of downstream datasets through end-to-end training. Moreover, to achieve a more appropriate label distribution, we propose a hierarchical loss, encompassing the alignment of the parameter space, feature space, and logits space. We conduct experiments on 11 downstream vision datasets and demonstrate that our method significantly improves the performance of existing multi-modal prompt learning models in few-shot scenarios, exhibiting an average accuracy improvement of 2.31(\%) compared to the state-of-the-art methods on 16 shots. Moreover, our methodology exhibits the preeminence in continual learning compared to other prompt tuning methods. Importantly, our method is synergistic with existing prompt tuning methods and can boost the performance on top of them. Our code and dataset will be publicly available at https://github.com/gaojingsheng/LAMM.
GIST: Improving Parameter Efficient Fine Tuning via Knowledge Interaction
Dec 12, 2023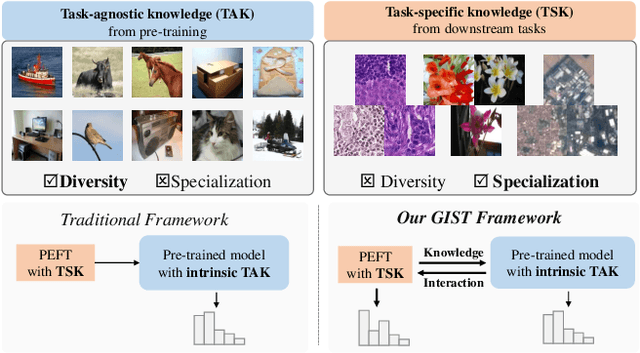
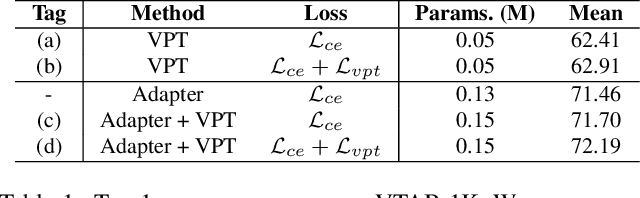
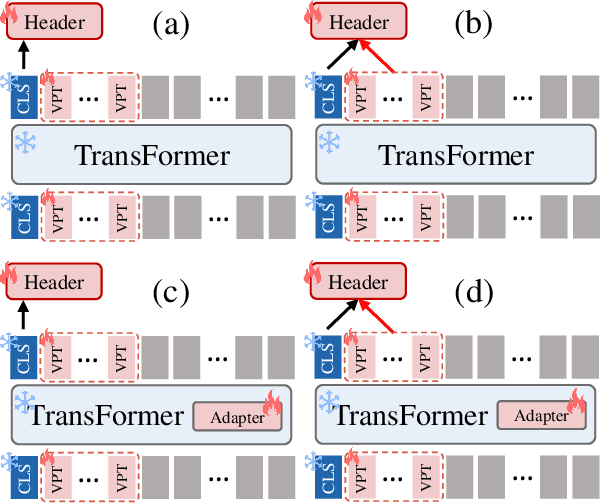
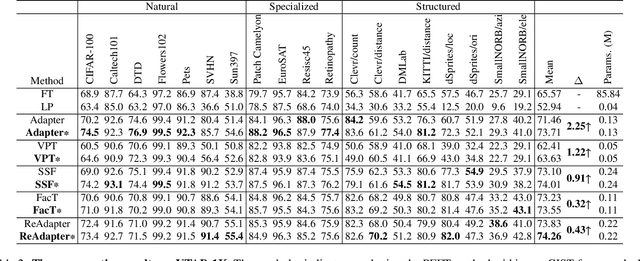
The Parameter-Efficient Fine-Tuning (PEFT) method, which adjusts or introduces fewer trainable parameters to calibrate pre-trained models on downstream tasks, has become a recent research interest. However, existing PEFT methods within the traditional fine-tiuning framework have two main shortcomings: 1) They overlook the explicit association between trainable parameters and downstream task knowledge. 2) They neglect the interaction between the intrinsic task-agnostic knowledge of pre-trained models and the task-specific knowledge in downstream tasks. To address this gap, we propose a novel fine-tuning framework, named GIST, in a plug-and-play manner. Specifically, our framework first introduces a trainable token, called the Gist token, when applying PEFT methods on downstream tasks. This token serves as an aggregator of the task-specific knowledge learned by the PEFT methods and forms an explicit association with downstream knowledge. Furthermore, to facilitate explicit interaction between task-agnostic and task-specific knowledge, we introduce the concept of Knowledge Interaction via a Bidirectional Kullback-Leibler Divergence objective. As a result, PEFT methods within our framework can make the pre-trained model understand downstream tasks more comprehensively by leveraging the knowledge interaction. Extensive experiments demonstrate the universality and scalability of our framework. Notably, on the VTAB-1K benchmark, we employ the Adapter (a prevalent PEFT method) within our GIST framework and achieve a performance boost of 2.25%, with an increase of only 0.8K parameters. The Code will be released.
Colo-SCRL: Self-Supervised Contrastive Representation Learning for Colonoscopic Video Retrieval
Mar 28, 2023



Colonoscopic video retrieval, which is a critical part of polyp treatment, has great clinical significance for the prevention and treatment of colorectal cancer. However, retrieval models trained on action recognition datasets usually produce unsatisfactory retrieval results on colonoscopic datasets due to the large domain gap between them. To seek a solution to this problem, we construct a large-scale colonoscopic dataset named Colo-Pair for medical practice. Based on this dataset, a simple yet effective training method called Colo-SCRL is proposed for more robust representation learning. It aims to refine general knowledge from colonoscopies through masked autoencoder-based reconstruction and momentum contrast to improve retrieval performance. To the best of our knowledge, this is the first attempt to employ the contrastive learning paradigm for medical video retrieval. Empirical results show that our method significantly outperforms current state-of-the-art methods in the colonoscopic video retrieval task.