 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-ColoNet: Spatio-Temporal Colon Segment Recognition via Hybrid Attention and Edge-Guided Feature Learning
May 27, 2026Colo-segment recognition in colonoscopy videos is a key requirement for many downstream tasks, but existing automatic recognition methods only use colonoscopy images without fully exploiting the use of temporal information, leading to poor performance. Additionally, relevant public video-based datasets are in scarcity. To tackle this problem, we curate and release a labeled dataset specifically for the task of colo-segment recognition. In addition, we propose a two-stage deep learning-based framework, Colo-Segment Recognition via SpatioTemporal Network (ST-ColoNet), for the task of colo-segment recognition from colonoscopy videos which includes the Colorlaus module that uses metric learning to optimize edge-mediated spatial feature extraction, as well as the Full-Temp module which combines three self-attention patterns to better approximate full self-attention on long colonoscopy sequences and optimize temporal feature aggregation. Through extensive ablation experiments, we show that our framework is capable of achieving state-of-the-art performance on the task of colo-segment recognition, achieving an accuracy of 81.0% and F1-score of 70.7%, which is a tremendous improvement over state-of-the-art methods.
MedCore: Boundary-Preserving Medical Core Pruning for MedSAM
May 13, 2026Medical segmentation foundation models such as SAM and MedSAM provide strong prompt-driven segmentation, but their image encoders are still too large for many clinical settings. Compression is also risky in medicine because a model can keep high Dice while losing boundary fidelity. We propose MedCore, a structured pruning framework for MedSAM. The main idea is to preserve two kinds of structures: structures that became important during SAM-to-MedSAM adaptation, and structures that have high boundary leverage. We identify the first type by a dual-intervention score that compares zeroing a group with resetting it to its original SAM weight. We identify the second type by boundary-aware Fisher estimation. We also introduce a boundary leverage principle, which shows that compression-induced boundary displacement is controlled by logit perturbation on the boundary divided by the logit spatial gradient. This principle explains why boundary metrics can degrade even when Dice remains high. On polyp segmentation benchmarks, MedCore reduces parameters by 60.0% and FLOPs by 58.4% while achieving Dice 0.9549, Boundary F1 0.6388, and HD95 5.14 after recovery fine-tuning. It also reaches 86.6% parameter reduction and 90.4G FLOPs with strong boundary quality. Our analysis further shows that MedSAM lies in a head-fragile boundary regime: head-pruning steps have 2.887 times larger 95th-percentile boundary leverage than MLP-pruning steps, and this logit-level effect is consistent with BF1 and HD95 degradation. Our code is available at https://github.com/cenweizhang/MedCore.
ExFusion: Efficient Transformer Training via Multi-Experts Fusion
Mar 30, 2026Mixture-of-Experts (MoE) models substantially improve performance by increasing the capacity of dense architectures. However, directly training MoE models requires considerable computational resources and introduces extra overhead in parameter storage and deployment. Therefore, it is critical to develop an approach that leverages the multi-expert capability of MoE to enhance performance while incurring minimal additional cost. To this end, we propose a novel pre-training approach, termed ExFusion, which improves the efficiency of Transformer training through multi-expert fusion. Specifically, during the initialization phase, ExFusion upcycles the feed-forward network (FFN) of the Transformer into a multi-expert configuration, where each expert is assigned a weight for later parameter fusion. During training, these weights allow multiple experts to be fused into a single unified expert equivalent to the original FFN, which is subsequently used for forward computation. As a result, ExFusion introduces multi-expert characteristics into the training process while incurring only marginal computational cost compared to standard dense training. After training, the learned weights are used to integrate multi-experts into a single unified expert, thereby eliminating additional overhead in storage and deployment. Extensive experiments on a variety of computer vision and natural language processing tasks demonstrate the effectiveness of the proposed method.
BMDS-Net: A Bayesian Multi-Modal Deep Supervision Network for Robust Brain Tumor Segmentation
Jan 24, 2026Accurate brain tumor segmentation from multi-modal magnetic resonance imaging (MRI) is a prerequisite for precise radiotherapy planning and surgical navigation. While recent Transformer-based models such as Swin UNETR have achieved impressive benchmark performance, their clinical utility is often compromised by two critical issues: sensitivity to missing modalities (common in clinical practice) and a lack of confidence calibration. Merely chasing higher Dice scores on idealized data fails to meet the safety requirements of real-world medical deployment. In this work, we propose BMDS-Net, a unified framework that prioritizes clinical robustness and trustworthiness over simple metric maximization. Our contribution is three-fold. First, we construct a robust deterministic backbone by integrating a Zero-Init Multimodal Contextual Fusion (MMCF) module and a Residual-Gated Deep Decoder Supervision (DDS) mechanism, enabling stable feature learning and precise boundary delineation with significantly reduced Hausdorff Distance, even under modality corruption. Second, and most importantly, we introduce a memory-efficient Bayesian fine-tuning strategy that transforms the network into a probabilistic predictor, providing voxel-wise uncertainty maps to highlight potential errors for clinicians. Third, comprehensive experiments on the BraTS 2021 dataset demonstrate that BMDS-Net not only maintains competitive accuracy but, more importantly, exhibits superior stability in missing-modality scenarios where baseline models fail. The source code is publicly available at https://github.com/RyanZhou168/BMDS-Net.
PhysSFI-Net: Physics-informed Geometric Learning of Skeletal and Facial Interactions for Orthognathic Surgical Outcome Prediction
Jan 06, 2026Orthognathic surgery repositions jaw bones to restore occlusion and enhance facial aesthetics. Accurate simulation of postoperative facial morphology is essential for preoperative planning. However, traditional biomechanical models are computationally expensive, while geometric deep learning approaches often lack interpretability. In this study, we develop and validate a physics-informed geometric deep learning framework named PhysSFI-Net for precise prediction of soft tissue deformation following orthognathic surgery. PhysSFI-Net consists of three components: a hierarchical graph module with craniofacial and surgical plan encoders combined with attention mechanisms to extract skeletal-facial interaction features; a Long Short-Term Memory (LSTM)-based sequential predictor for incremental soft tissue deformation; and a biomechanics-inspired module for high-resolution facial surface reconstruction. Model performance was assessed using point cloud shape error (Hausdorff distance), surface deviation error, and landmark localization error (Euclidean distances of craniomaxillofacial landmarks) between predicted facial shapes and corresponding ground truths. A total of 135 patients who underwent combined orthodontic and orthognathic treatment were included for model training and validation. Quantitative analysis demonstrated that PhysSFI-Net achieved a point cloud shape error of 1.070 +/- 0.088 mm, a surface deviation error of 1.296 +/- 0.349 mm, and a landmark localization error of 2.445 +/- 1.326 mm. Comparative experiments indicated that PhysSFI-Net outperformed the state-of-the-art method ACMT-Net in prediction accuracy. In conclusion, PhysSFI-Net enables interpretable, high-resolution prediction of postoperative facial morphology with superior accuracy, showing strong potential for clinical application in orthognathic surgical planning and simulation.
GPF-Net: Gated Progressive Fusion Learning for Polyp Re-Identification
Dec 25, 2025Colonoscopic Polyp Re-Identification aims to match the same polyp from a large gallery with images from different views taken using different cameras, which plays an important role in the prevention and treatment of colorectal cancer in computer-aided diagnosis. However, the coarse resolution of high-level features of a specific polyp often leads to inferior results for small objects where detailed information is important. To address this challenge, we propose a novel architecture, named Gated Progressive Fusion network, to selectively fuse features from multiple levels using gates in a fully connected way for polyp ReID. On the basis of it, a gated progressive fusion strategy is introduced to achieve layer-wise refinement of semantic information through multi-level feature interactions. Experiments on standard benchmarks show the benefits of the multimodal setting over state-of-the-art unimodal ReID models, especially when combined with the specialized multimodal fusion strategy.
LDP: Parameter-Efficient Fine-Tuning of Multimodal LLM for Medical Report Generation
Dec 11, 2025Colonoscopic polyp diagnosis is pivotal for early colorectal cancer detection, yet traditional automated reporting suffers from inconsistencies and hallucinations due to the scarcity of high-quality multimodal medical data. To bridge this gap, we propose LDP, a novel framework leveraging multimodal large language models (MLLMs) for professional polyp diagnosis report generation. Specifically, we curate MMEndo, a multimodal endoscopic dataset comprising expert-annotated colonoscopy image-text pairs. We fine-tune the Qwen2-VL-7B backbone using Parameter-Efficient Fine-Tuning (LoRA) and align it with clinical standards via Direct Preference Optimization (DPO). Extensive experiments show that our LDP outperforms existing baselines on both automated metrics and rigorous clinical expert evaluations (achieving a Physician Score of 7.2/10), significantly reducing training computational costs by 833x compared to full fine-tuning. The proposed solution offers a scalable, clinically viable path for primary healthcare, with additional validation on the IU-XRay dataset confirming its robustness.
Leveraging MIMIC Datasets for Better Digital Health: A Review on Open Problems, Progress Highlights, and Future Promises
Jun 15, 2025The Medical Information Mart for Intensive Care (MIMIC) datasets have become the Kernel of Digital Health Research by providing freely accessible, deidentified records from tens of thousands of critical care admissions, enabling a broad spectrum of applications in clinical decision support, outcome prediction, and healthcare analytics. Although numerous studies and surveys have explored the predictive power and clinical utility of MIMIC based models, critical challenges in data integration, representation, and interoperability remain underexplored. This paper presents a comprehensive survey that focuses uniquely on open problems. We identify persistent issues such as data granularity, cardinality limitations, heterogeneous coding schemes, and ethical constraints that hinder the generalizability and real-time implementation of machine learning models. We highlight key progress in dimensionality reduction, temporal modelling, causal inference, and privacy preserving analytics, while also outlining promising directions including hybrid modelling, federated learning, and standardized preprocessing pipelines. By critically examining these structural limitations and their implications, this survey offers actionable insights to guide the next generation of MIMIC powered digital health innovations.
Understanding Robustness of Parameter-Efficient Tuning for Image Classification
Oct 13, 2024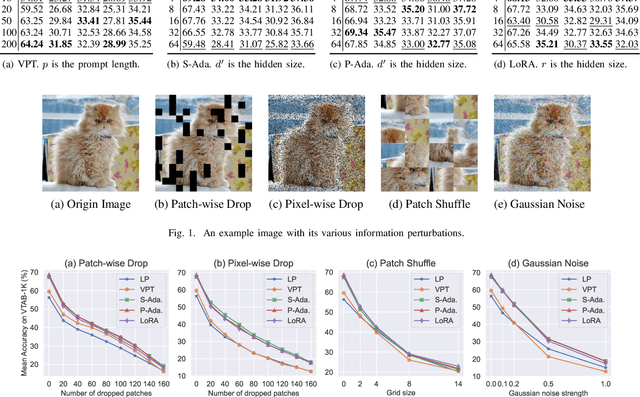

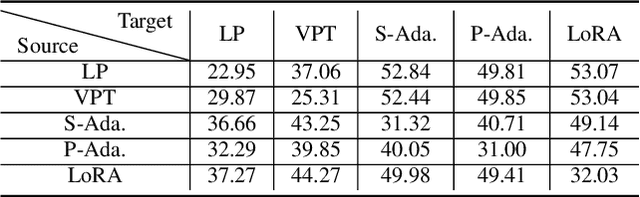

Parameter-efficient tuning (PET) techniques calibrate the model's predictions on downstream tasks by freezing the pre-trained models and introducing a small number of learnable parameters. However, despite the numerous PET methods proposed, their robustness has not been thoroughly investigated. In this paper, we systematically explore the robustness of four classical PET techniques (e.g., VPT, Adapter, AdaptFormer, and LoRA) under both white-box attacks and information perturbations. For white-box attack scenarios, we first analyze the performance of PET techniques using FGSM and PGD attacks. Subsequently, we further explore the transferability of adversarial samples and the impact of learnable parameter quantities on the robustness of PET methods. Under information perturbation attacks, we introduce four distinct perturbation strategies, including Patch-wise Drop, Pixel-wise Drop, Patch Shuffle, and Gaussian Noise, to comprehensively assess the robustness of these PET techniques in the presence of information loss. Via these extensive studies, we enhance the understanding of the robustness of PET methods, providing valuable insights for improving their performance in computer vision applications. The code is available at https://github.com/JCruan519/PETRobustness.
Deep Multimodal Collaborative Learning for Polyp Re-Identification
Aug 12, 2024Colonoscopic Polyp Re-Identification aims to match the same polyp from a large gallery with images from different views taken using different cameras and plays an important role in the prevention and treatment of colorectal cancer in computer-aided diagnosis. However, traditional methods for object ReID directly adopting CNN models trained on the ImageNet dataset usually produce unsatisfactory retrieval performance on colonoscopic datasets due to the large domain gap. Worsely, these solutions typically learn unimodal modal representations on the basis of visual samples, which fails to explore complementary information from different modalities. To address this challenge, we propose a novel Deep Multimodal Collaborative Learning framework named DMCL for polyp re-identification, which can effectively encourage modality collaboration and reinforce generalization capability in medical scenarios. On the basis of it, a dynamic multimodal feature fusion strategy is introduced to leverage the optimized multimodal representations for multimodal fusion via end-to-end training. Experiments on the standard benchmarks show the benefits of the multimodal setting over state-of-the-art unimodal ReID models, especially when combined with the specialized multimodal fusion strategy.