 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Responsible Multimodal Medical Reasoning via Context-Aligned Vision-Language Models
Apr 09, 2026Medical vision-language models (VLMs) show strong performance on radiology tasks but often produce fluent yet weakly grounded conclusions due to over-reliance on a dominant modality. We introduce a context-aligned reasoning framework that enforces agreement across heterogeneous clinical evidence before generating diagnostic conclusions. The proposed approach augments a frozen VLM with structured contextual signals derived from radiomic statistics, explainability activations, and vocabulary-grounded semantic cues. Instead of producing free-form responses, the model generates structured outputs containing supporting evidence, uncertainty estimates, limitations, and safety notes. We observe that auxiliary signals alone provide limited benefit; performance gains emerge only when these signals are integrated through contextual verification. Experiments on chest X-ray datasets demonstrate that context alignment improves discriminative performance (AUC 0.918 to 0.925) while maintaining calibrated uncertainty. The framework also substantially reduces hallucinated keywords (1.14 to 0.25) and produces more concise reasoning explanations (19.4 to 15.3 words) without increasing model confidence (0.70 to 0.68). Cross-dataset evaluation on CheXpert further reveals that modality informativeness significantly influences reasoning behavior. These results suggest that enforcing multi-evidence agreement improves both reliability and trustworthiness in medical multimodal reasoning, while preserving the underlying model architecture.
Beyond Anatomy: Explainable ASD Classification from rs-fMRI via Functional Parcellation and Graph Attention Networks
Mar 03, 2026Anatomical brain parcellations dominate rs-fMRI-based Autism Spectrum Disorder (ASD) classification, yet their rigid boundaries may fail to capture the idiosyncratic connectivity patterns that characterise ASD. We present a graph-based deep learning framework comparing anatomical (AAL, 116 ROIs) and functionally-derived (MSDL, 39 ROIs) parcellation strategies on the ABIDE I dataset. Our FSL preprocessing pipeline handles multi-site heterogeneity across 400 balanced subjects, with site-stratified 70/15/15 splits to prevent data leakage. Gaussian noise augmentation within training folds expands samples from 280 to 1,680. A three phase pipeline progresses from a baseline GCN with AAL (73.3% accuracy, AUC=0.74), to an optimised GCN with MSDL (84.0%, AUC=0.84), to a Graph Attention Network ensemble achieving 95.0% accuracy (AUC=0.98), outperforming all recent GNN-based benchmarks on ABIDE I. The 10.7-point gain from atlas substitution alone demonstrates that functional parcellation is the most impactful modelling decision. Gradient-based saliency and GNNExplainer analyses converge on the Posterior Cingulate Cortex and Precuneus as core Default Mode Network hubs, validating that model decisions reflect ASD neuropathology rather than acquisition artefacts. All code and datasets will be publicly released upon acceptance.
Foundation Models in Biomedical Imaging: Turning Hype into Reality
Dec 17, 2025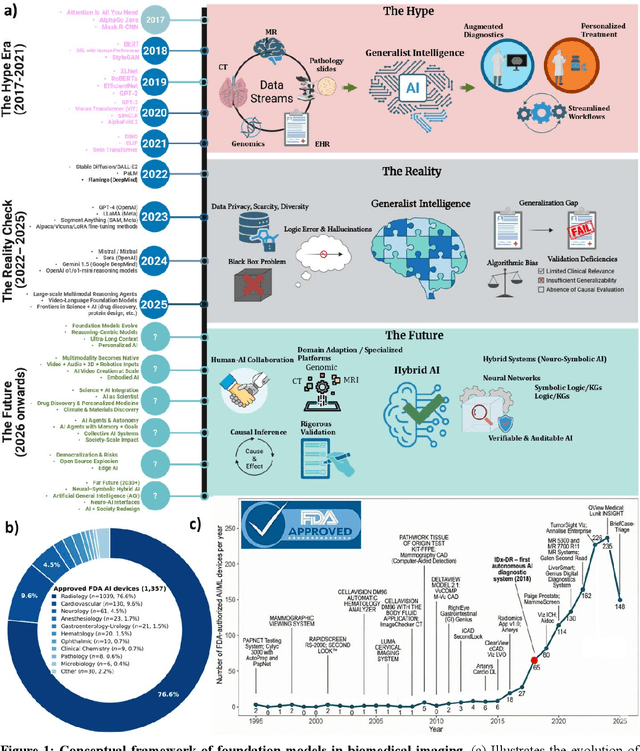

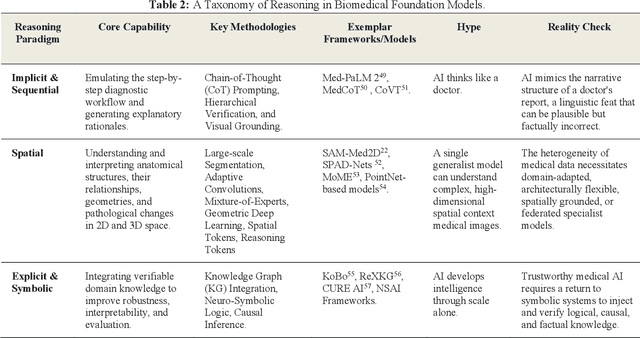
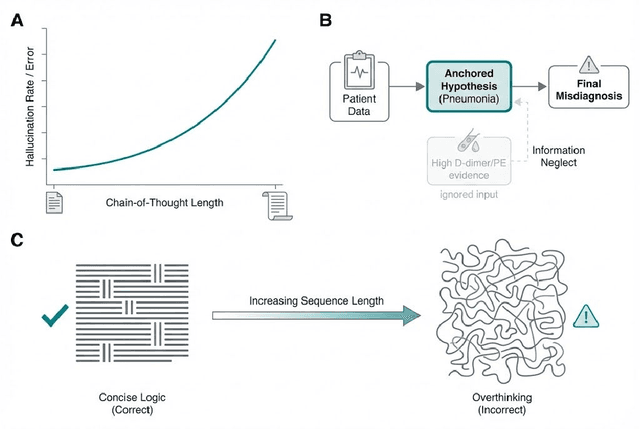
Foundation models (FMs) are driving a prominent shift in artificial intelligence across different domains, including biomedical imaging. These models are designed to move beyond narrow pattern recognition towards emulating sophisticated clinical reasoning, understanding complex spatial relationships, and integrating multimodal data with unprecedented flexibility. However, a critical gap exists between this potential and the current reality, where the clinical evaluation and deployment of FMs are hampered by significant challenges. Herein, we critically assess the current state-of-the-art, analyzing hype by examining the core capabilities and limitations of FMs in the biomedical domain. We also provide a taxonomy of reasoning, ranging from emulated sequential logic and spatial understanding to the integration of explicit symbolic knowledge, to evaluate whether these models exhibit genuine cognition or merely mimic surface-level patterns. We argue that a critical frontier lies beyond statistical correlation, in the pursuit of causal inference, which is essential for building robust models that understand cause and effect. Furthermore, we discuss the paramount issues in deployment stemming from trustworthiness, bias, and safety, dissecting the challenges of algorithmic bias, data bias and privacy, and model hallucinations. We also draw attention to the need for more inclusive, rigorous, and clinically relevant validation frameworks to ensure their safe and ethical application. We conclude that while the vision of autonomous AI-doctors remains distant, the immediate reality is the emergence of powerful technology and assistive tools that would benefit clinical practice. The future of FMs in biomedical imaging hinges not on scale alone, but on developing hybrid, causally aware, and verifiably safe systems that augment, rather than replace, human expertise.
Thinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025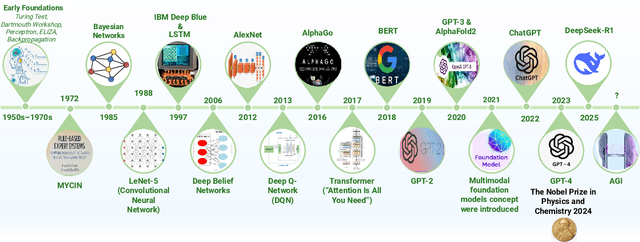
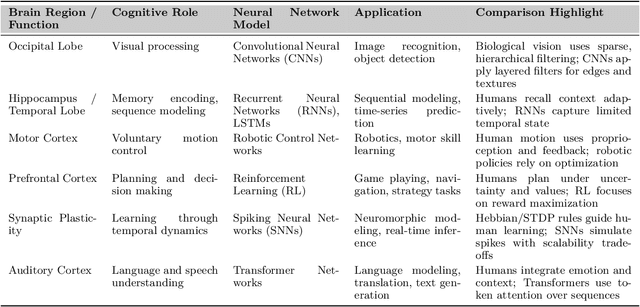
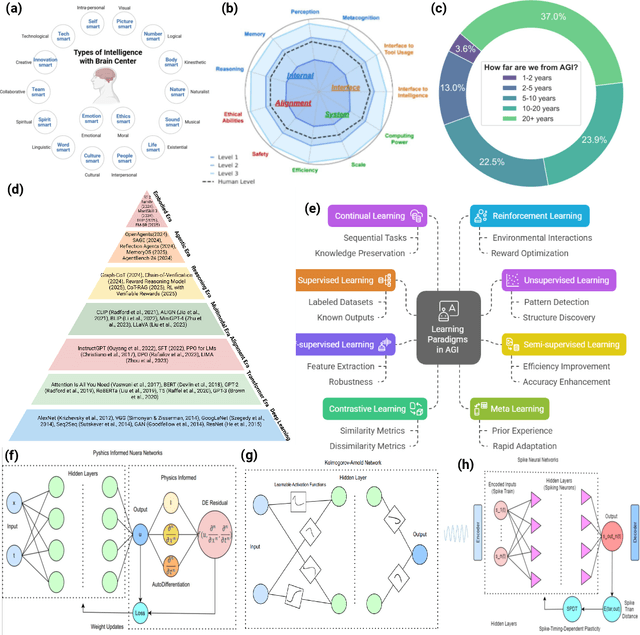
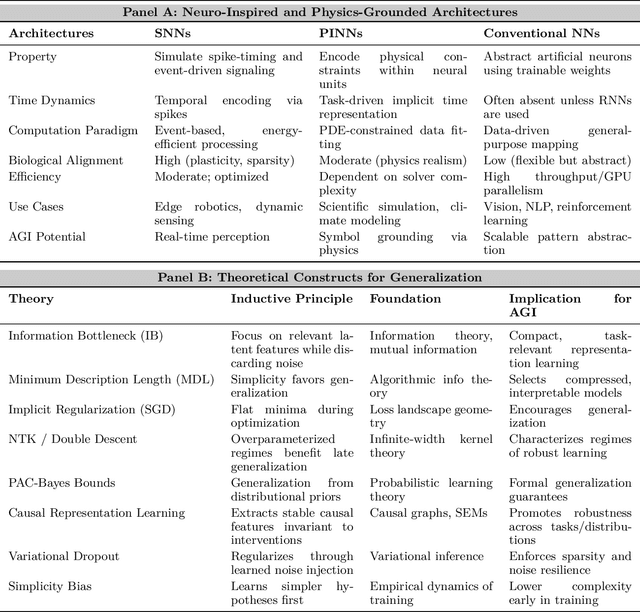
Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
Leveraging MIMIC Datasets for Better Digital Health: A Review on Open Problems, Progress Highlights, and Future Promises
Jun 15, 2025The Medical Information Mart for Intensive Care (MIMIC) datasets have become the Kernel of Digital Health Research by providing freely accessible, deidentified records from tens of thousands of critical care admissions, enabling a broad spectrum of applications in clinical decision support, outcome prediction, and healthcare analytics. Although numerous studies and surveys have explored the predictive power and clinical utility of MIMIC based models, critical challenges in data integration, representation, and interoperability remain underexplored. This paper presents a comprehensive survey that focuses uniquely on open problems. We identify persistent issues such as data granularity, cardinality limitations, heterogeneous coding schemes, and ethical constraints that hinder the generalizability and real-time implementation of machine learning models. We highlight key progress in dimensionality reduction, temporal modelling, causal inference, and privacy preserving analytics, while also outlining promising directions including hybrid modelling, federated learning, and standardized preprocessing pipelines. By critically examining these structural limitations and their implications, this survey offers actionable insights to guide the next generation of MIMIC powered digital health innovations.
A Layered Self-Supervised Knowledge Distillation Framework for Efficient Multimodal Learning on the Edge
Jun 08, 2025We introduce Layered Self-Supervised Knowledge Distillation (LSSKD) framework for training compact deep learning models. Unlike traditional methods that rely on pre-trained teacher networks, our approach appends auxiliary classifiers to intermediate feature maps, generating diverse self-supervised knowledge and enabling one-to-one transfer across different network stages. Our method achieves an average improvement of 4.54\% over the state-of-the-art PS-KD method and a 1.14% gain over SSKD on CIFAR-100, with a 0.32% improvement on ImageNet compared to HASSKD. Experiments on Tiny ImageNet and CIFAR-100 under few-shot learning scenarios also achieve state-of-the-art results. These findings demonstrate the effectiveness of our approach in enhancing model generalization and performance without the need for large over-parameterized teacher networks. Importantly, at the inference stage, all auxiliary classifiers can be removed, yielding no extra computational cost. This makes our model suitable for deploying small language models on affordable low-computing devices. Owing to its lightweight design and adaptability, our framework is particularly suitable for multimodal sensing and cyber-physical environments that require efficient and responsive inference. LSSKD facilitates the development of intelligent agents capable of learning from limited sensory data under weak supervision.
SatelliteFormula: Multi-Modal Symbolic Regression from Remote Sensing Imagery for Physics Discovery
Jun 06, 2025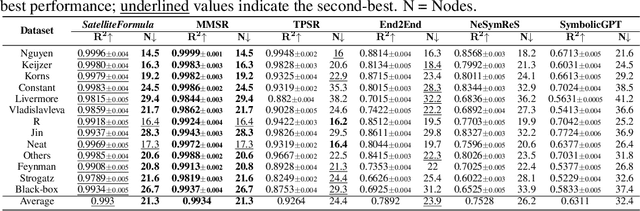
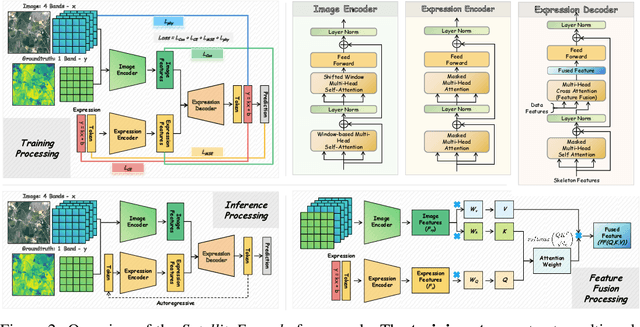
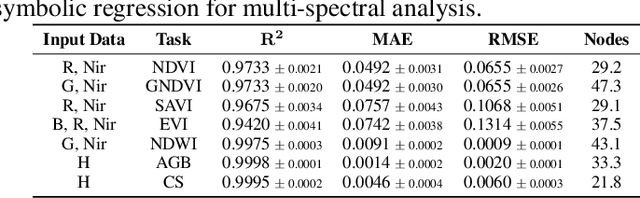
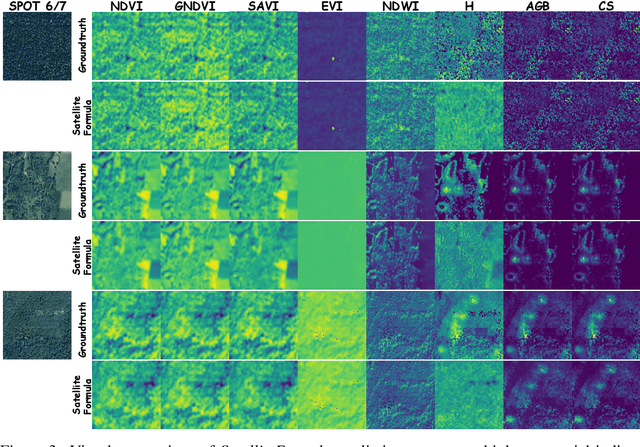
We propose SatelliteFormula, a novel symbolic regression framework that derives physically interpretable expressions directly from multi-spectral remote sensing imagery. Unlike traditional empirical indices or black-box learning models, SatelliteFormula combines a Vision Transformer-based encoder for spatial-spectral feature extraction with physics-guided constraints to ensure consistency and interpretability. Existing symbolic regression methods struggle with the high-dimensional complexity of multi-spectral data; our method addresses this by integrating transformer representations into a symbolic optimizer that balances accuracy and physical plausibility. Extensive experiments on benchmark datasets and remote sensing tasks demonstrate superior performance, stability, and generalization compared to state-of-the-art baselines. SatelliteFormula enables interpretable modeling of complex environmental variables, bridging the gap between data-driven learning and physical understanding.
Just as Humans Need Vaccines, So Do Models: Model Immunization to Combat Falsehoods
May 23, 2025Generative AI models often learn and reproduce false information present in their training corpora. This position paper argues that, analogous to biological immunization, where controlled exposure to a weakened pathogen builds immunity, AI models should be fine tuned on small, quarantined sets of explicitly labeled falsehoods as a "vaccine" against misinformation. These curated false examples are periodically injected during finetuning, strengthening the model ability to recognize and reject misleading claims while preserving accuracy on truthful inputs. An illustrative case study shows that immunized models generate substantially less misinformation than baselines. To our knowledge, this is the first training framework that treats fact checked falsehoods themselves as a supervised vaccine, rather than relying on input perturbations or generic human feedback signals, to harden models against future misinformation. We also outline ethical safeguards and governance controls to ensure the safe use of false data. Model immunization offers a proactive paradigm for aligning AI systems with factuality.
VLDBench: Vision Language Models Disinformation Detection Benchmark
Feb 17, 2025



The rapid rise of AI-generated content has made detecting disinformation increasingly challenging. In particular, multimodal disinformation, i.e., online posts-articles that contain images and texts with fabricated information are specially designed to deceive. While existing AI safety benchmarks primarily address bias and toxicity, multimodal disinformation detection remains largely underexplored. To address this challenge, we present the Vision-Language Disinformation Detection Benchmark VLDBench, the first comprehensive benchmark for detecting disinformation across both unimodal (text-only) and multimodal (text and image) content, comprising 31,000} news article-image pairs, spanning 13 distinct categories, for robust evaluation. VLDBench features a rigorous semi-automated data curation pipeline, with 22 domain experts dedicating 300 plus hours} to annotation, achieving a strong inter-annotator agreement (Cohen kappa = 0.78). We extensively evaluate state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs), demonstrating that integrating textual and visual cues in multimodal news posts improves disinformation detection accuracy by 5 - 35 % compared to unimodal models. Developed in alignment with AI governance frameworks such as the EU AI Act, NIST guidelines, and the MIT AI Risk Repository 2024, VLDBench is expected to become a benchmark for detecting disinformation in online multi-modal contents. Our code and data will be publicly available.
Technical note on calibrating vision-language models under covariate shift
Feb 11, 2025



Despite being a successful example of emerging capability, vision-language foundation models for low-shot vision classification have a limited ability to sufficiently generalize to the target data distribution due to sample poverty, leading to sensitivity to variations in the data. A popular mitigation strategy is finetuning over multiple datasets, but domain generalization is expensive when practiced in this manner. This work examines both covariate shift between pre-training data and the underspecified target data, and \textit{confidence misalignment}, where the model's prediction confidence amplified by the limited data availability. We propose \textit{Confidence-Calibrated Covariate Shift Correction ($C3SC$)}, a unified framework to mitigate both covariate shift and confidence misalignment. $C3SC$ leverages Fisher information penalty for covariate shift correction and confidence misalignment penalty (CMP) to lower confidence on misclassified examples. Experimental results across various vision and covariate shift datasets demonstrates that $C3SC$ significantly improves in calibration (ECE) by $5.82\%$ at maximum. $C3SC$ shows better robustness as well by showing $3.5\%$ improvement in accuracy metric on challenging covariate shift datasets, making $C3SC$ a promising solution for reliable real-world vision-language low-shot applications under distribution shift.