 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Human-Likeness in Reinforcement Learning Agents via Hierarchical Macro Action Quantization
May 29, 2026Human-like agents are a long-standing goal of artificial intelligence. Despite strong performance, most reinforcement learning (RL) agents remain reward-driven and often exhibit behaviors that differ from humans, limiting interpretability and reliability. In this work, we introduce a novel human-like RL framework that predicts action sequences closely aligned with human behaviors while maximizing rewards. Specifically, we encode human demonstrations into macro actions using a hierarchical macro action quantization approach (termed HiMAQ) consisting of two successive levels of vector quantization. The lower quantization level maps input actions to fine-grained subaction clusters, while the higher quantization level aggregates these subaction clusters into action clusters. Extensive evaluations on the D4RL benchmarks show that our hierarchical approach outperforms the non-hierarchical baseline (MAQ), achieving better human-likeness scores while maintaining comparable or better success rates than previous RL agents. The improvements generalize across integrations with various RL algorithms, namely IQL, SAC, and RLPD.
A Hierarchical Spatiotemporal Action Tokenizer for In-Context Imitation Learning in Robotics
Apr 16, 2026We present a novel hierarchical spatiotemporal action tokenizer for in-context imitation learning. We first propose a hierarchical approach, which consists of two successive levels of vector quantization. In particular, the lower level assigns input actions to fine-grained subclusters, while the higher level further maps fine-grained subclusters to clusters. Our hierarchical approach outperforms the non-hierarchical counterpart, while mainly exploiting spatial information by reconstructing input actions. Furthermore, we extend our approach by utilizing both spatial and temporal cues, forming a hierarchical spatiotemporal action tokenizer, namely HiST-AT. Specifically, our hierarchical spatiotemporal approach conducts multi-level clustering, while simultaneously recovering input actions and their associated timestamps. Finally, extensive evaluations on multiple simulation and real robotic manipulation benchmarks show that our approach establishes a new state-of-the-art performance in in-context imitation learning.
Learning by Aligning 2D Skeleton Sequences in Time
May 31, 2023



This paper presents a novel self-supervised temporal video alignment framework which is useful for several fine-grained human activity understanding applications. In contrast with the state-of-the-art method of CASA, where sequences of 3D skeleton coordinates are taken directly as input, our key idea is to use sequences of 2D skeleton heatmaps as input. Given 2D skeleton heatmaps, we utilize a video transformer which performs self-attention in the spatial and temporal domains for extracting effective spatiotemporal and contextual features. In addition, we introduce simple heatmap augmentation techniques based on 2D skeletons for self-supervised learning. Despite the lack of 3D information, our approach achieves not only higher accuracy but also better robustness against missing and noisy keypoints than CASA. Extensive evaluations on three public datasets, i.e., Penn Action, IKEA ASM, and H2O, demonstrate that our approach outperforms previous methods in different fine-grained human activity understanding tasks, i.e., phase classification, phase progression, video alignment, and fine-grained frame retrieval.
Guiding Attention using Partial-Order Relationships for Image Captioning
Apr 15, 2022
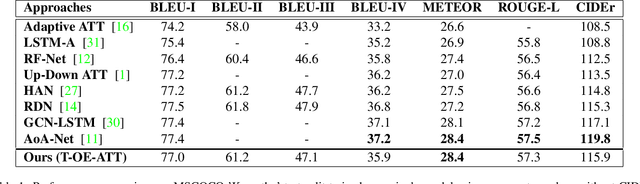
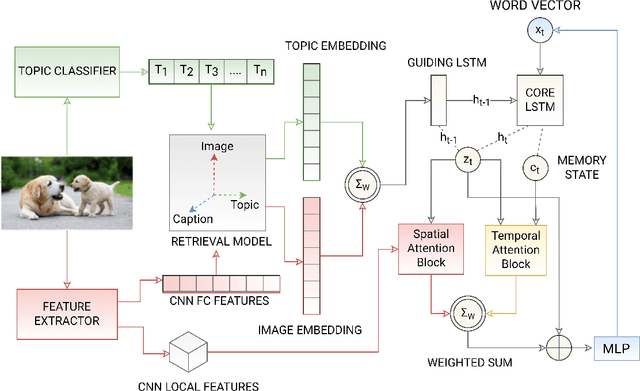
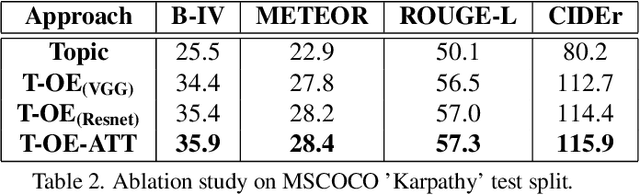
The use of attention models for automated image captioning has enabled many systems to produce accurate and meaningful descriptions for images. Over the years, many novel approaches have been proposed to enhance the attention process using different feature representations. In this paper, we extend this approach by creating a guided attention network mechanism, that exploits the relationship between the visual scene and text-descriptions using spatial features from the image, high-level information from the topics, and temporal context from caption generation, which are embedded together in an ordered embedding space. A pairwise ranking objective is used for training this embedding space which allows similar images, topics and captions in the shared semantic space to maintain a partial order in the visual-semantic hierarchy and hence, helps the model to produce more visually accurate captions. The experimental results based on MSCOCO dataset shows the competitiveness of our approach, with many state-of-the-art models on various evaluation metrics.