 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Self-Supervised Video Alignment and Action Segmentation
Mar 21, 2025We introduce a novel approach for simultaneous self-supervised video alignment and action segmentation based on a unified optimal transport framework. In particular, we first tackle self-supervised video alignment by developing a fused Gromov-Wasserstein optimal transport formulation with a structural prior, which trains efficiently on GPUs and needs only a few iterations for solving the optimal transport problem. Our single-task method achieves the state-of-the-art performance on multiple video alignment benchmarks and outperforms VAVA, which relies on a traditional Kantorovich optimal transport formulation with an optimality prior. Furthermore, we extend our approach by proposing a unified optimal transport framework for joint self-supervised video alignment and action segmentation, which requires training and storing a single model and saves both time and memory consumption as compared to two different single-task models. Extensive evaluations on several video alignment and action segmentation datasets demonstrate that our multi-task method achieves comparable video alignment yet superior action segmentation results over previous methods in video alignment and action segmentation respectively. Finally, to the best of our knowledge, this is the first work to unify video alignment and action segmentation into a single model.
Video LLMs for Temporal Reasoning in Long Videos
Dec 04, 2024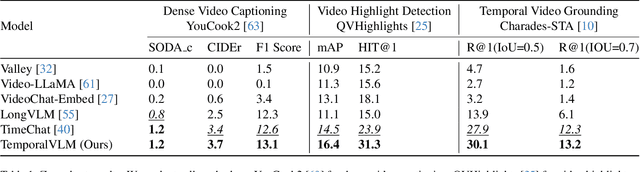
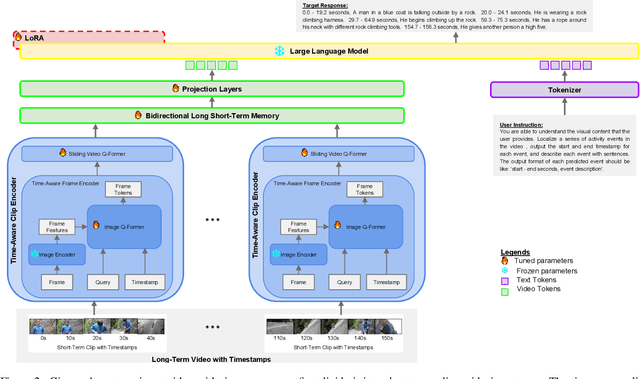


This paper introduces TemporalVLM, a video large language model capable of effective temporal reasoning and fine-grained understanding in long videos. At the core, our approach includes a visual encoder for mapping a long-term input video into features which are time-aware and contain both local and global cues. In particular, it first divides the input video into short-term clips, which are jointly encoded with their timestamps into time-sensitive local features. Next, the local features are passed through a bidirectional long short-term memory module for global feature aggregation. The extracted time-aware and multi-level features are important for accurate temporal reasoning and fine-grained understanding in long videos. Moreover, to facilitate the evaluation of TemporalVLM, we present a large-scale long video dataset of industry assembly processes, namely IndustryASM, which consists of videos recorded on factory floors with actions and timestamps annotated by industrial engineers for time and motion studies and temporal action segmentation evaluation. Finally, extensive experiments on datasets of long videos, including TimeIT and IndustryASM, show that TemporalVLM achieves superior performance than previous methods across temporal reasoning and fine-grained understanding tasks, namely dense video captioning, temporal video grounding, video highlight detection, and temporal action segmentation.
Action Segmentation Using 2D Skeleton Heatmaps
Sep 19, 2023



This paper presents a 2D skeleton-based action segmentation method with applications in fine-grained human activity recognition. In contrast with state-of-the-art methods which directly take sequences of 3D skeleton coordinates as inputs and apply Graph Convolutional Networks (GCNs) for spatiotemporal feature learning, our main idea is to use sequences of 2D skeleton heatmaps as inputs and employ Temporal Convolutional Networks (TCNs) to extract spatiotemporal features. Despite lacking 3D information, our approach yields comparable/superior performances and better robustness against missing keypoints than previous methods on action segmentation datasets. Moreover, we improve the performances further by using both 2D skeleton heatmaps and RGB videos as inputs. To our best knowledge, this is the first work to utilize 2D skeleton heatmap inputs and the first work to explore 2D skeleton+RGB fusion for action segmentation.
Learning by Aligning 2D Skeleton Sequences in Time
May 31, 2023



This paper presents a novel self-supervised temporal video alignment framework which is useful for several fine-grained human activity understanding applications. In contrast with the state-of-the-art method of CASA, where sequences of 3D skeleton coordinates are taken directly as input, our key idea is to use sequences of 2D skeleton heatmaps as input. Given 2D skeleton heatmaps, we utilize a video transformer which performs self-attention in the spatial and temporal domains for extracting effective spatiotemporal and contextual features. In addition, we introduce simple heatmap augmentation techniques based on 2D skeletons for self-supervised learning. Despite the lack of 3D information, our approach achieves not only higher accuracy but also better robustness against missing and noisy keypoints than CASA. Extensive evaluations on three public datasets, i.e., Penn Action, IKEA ASM, and H2O, demonstrate that our approach outperforms previous methods in different fine-grained human activity understanding tasks, i.e., phase classification, phase progression, video alignment, and fine-grained frame retrieval.
Permutation-Aware Action Segmentation via Unsupervised Frame-to-Segment Alignment
May 31, 2023This paper presents a novel transformer-based framework for unsupervised activity segmentation which leverages not only frame-level cues but also segment-level cues. This is in contrast with previous methods which often rely on frame-level information only. Our approach begins with a frame-level prediction module which estimates framewise action classes via a transformer encoder. The frame-level prediction module is trained in an unsupervised manner via temporal optimal transport. To exploit segment-level information, we introduce a segment-level prediction module and a frame-to-segment alignment module. The former includes a transformer decoder for estimating video transcripts, while the latter matches frame-level features with segment-level features, yielding permutation-aware segmentation results. Moreover, inspired by temporal optimal transport, we develop simple-yet-effective pseudo labels for unsupervised training of the above modules. Our experiments on four public datasets, i.e., 50 Salads, YouTube Instructions, Breakfast, and Desktop Assembly show that our approach achieves comparable or better performance than previous methods in unsupervised activity segmentation.
Timestamp-Supervised Action Segmentation with Graph Convolutional Networks
Jun 30, 2022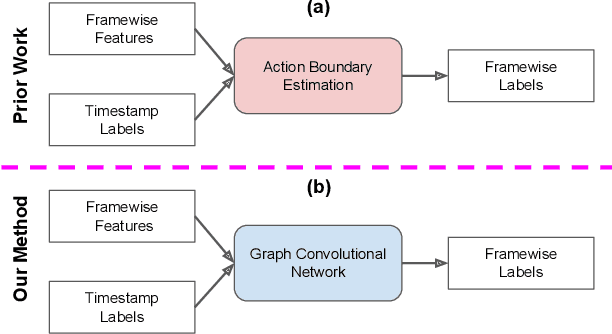
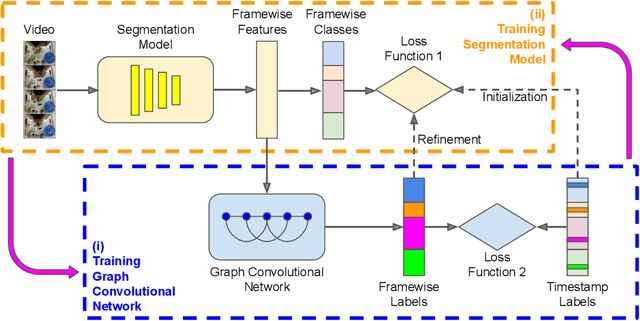

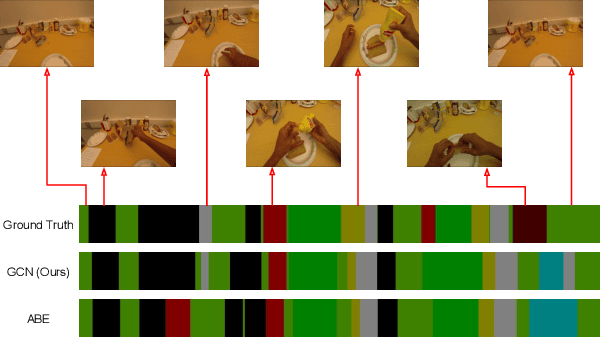
We introduce a novel approach for temporal activity segmentation with timestamp supervision. Our main contribution is a graph convolutional network, which is learned in an end-to-end manner to exploit both frame features and connections between neighboring frames to generate dense framewise labels from sparse timestamp labels. The generated dense framewise labels can then be used to train the segmentation model. In addition, we propose a framework for alternating learning of both the segmentation model and the graph convolutional model, which first initializes and then iteratively refines the learned models. Detailed experiments on four public datasets, including 50 Salads, GTEA, Breakfast, and Desktop Assembly, show that our method is superior to the multi-layer perceptron baseline, while performing on par with or better than the state of the art in temporal activity segmentation with timestamp supervision.
Unsupervised Activity Segmentation by Joint Representation Learning and Online Clustering
May 28, 2021
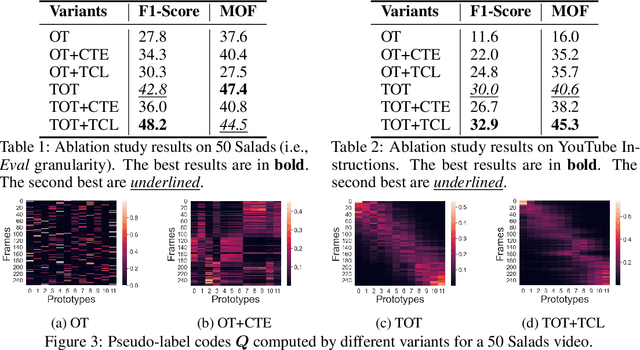
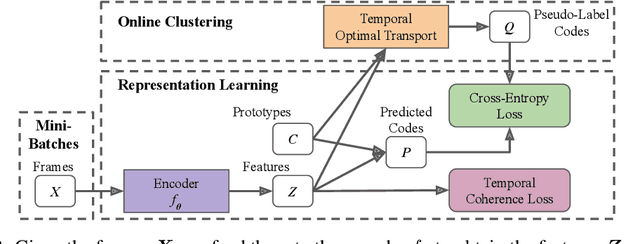
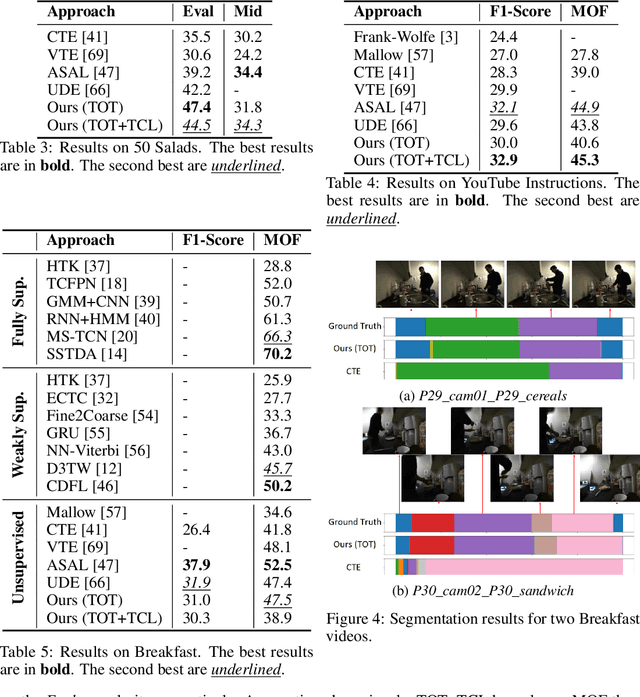
We present a novel approach for unsupervised activity segmentation, which uses video frame clustering as a pretext task and simultaneously performs representation learning and online clustering. This is in contrast with prior works where representation learning and clustering are often performed sequentially. We leverage temporal information in videos by employing temporal optimal transport and temporal coherence loss. In particular, we incorporate a temporal regularization term into the standard optimal transport module, which preserves the temporal order of the activity, yielding the temporal optimal transport module for computing pseudo-label cluster assignments. Next, the temporal coherence loss encourages neighboring video frames to be mapped to nearby points while distant video frames are mapped to farther away points in the embedding space. The combination of these two components results in effective representations for unsupervised activity segmentation. Furthermore, previous methods require storing learned features for the entire dataset before clustering them in an offline manner, whereas our approach processes one mini-batch at a time in an online manner. Extensive evaluations on three public datasets, i.e. 50-Salads, YouTube Instructions, and Breakfast, and our dataset, i.e., Desktop Assembly, show that our approach performs on par or better than previous methods for unsupervised activity segmentation, despite having significantly less memory constraints.
Towards Anomaly Detection in Dashcam Videos
May 12, 2020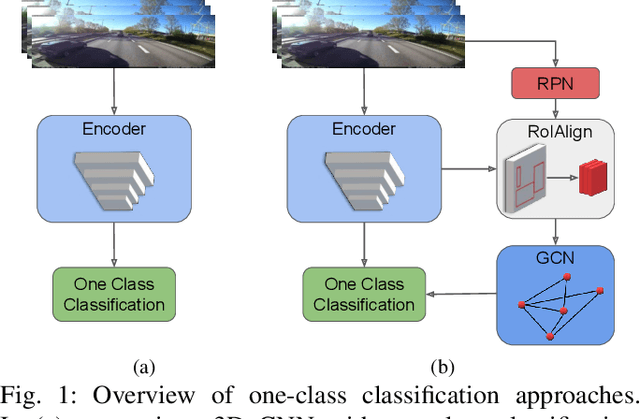
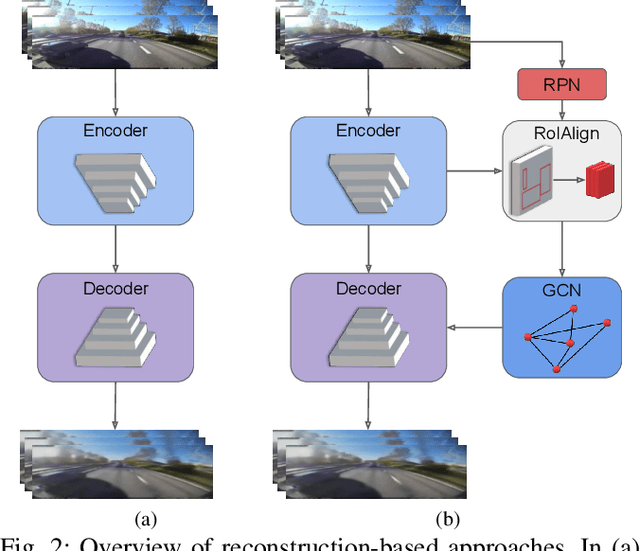


Inexpensive sensing and computation, as well as insurance innovations, have made smart dashboard cameras ubiquitous. Increasingly, simple model-driven computer vision algorithms focused on lane departures or safe following distances are finding their way into these devices. Unfortunately, the long-tailed distribution of road hazards means that these hand-crafted pipelines are inadequate for driver safety systems. We propose to apply data-driven anomaly detection ideas from deep learning to dashcam videos, which hold the promise of bridging this gap. Unfortunately, there exists almost no literature applying anomaly understanding to moving cameras, and correspondingly there is also a lack of relevant datasets. To counter this issue, we present a large and diverse dataset of truck dashcam videos, namely RetroTrucks, that includes normal and anomalous driving scenes. We apply: (i) one-class classification loss and (ii) reconstruction-based loss, for anomaly detection on RetroTrucks as well as on existing static-camera datasets. We introduce formulations for modeling object interactions in this context as priors. Our experiments indicate that our dataset is indeed more challenging than standard anomaly detection datasets, and previous anomaly detection methods do not perform well here out-of-the-box. In addition, we share insights into the behavior of these two important families of anomaly detection approaches on dashcam data.
Hierarchical Metric Learning and Matching for 2D and 3D Geometric Correspondences
Aug 02, 2018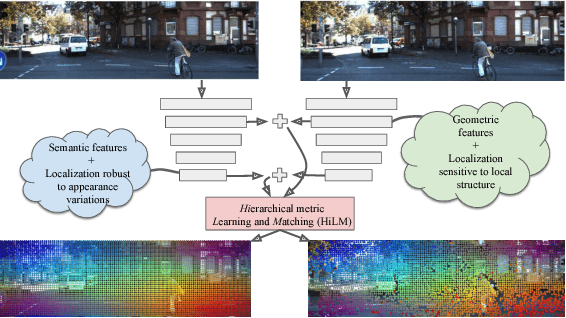
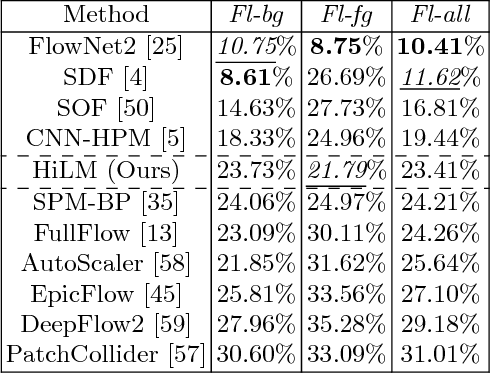
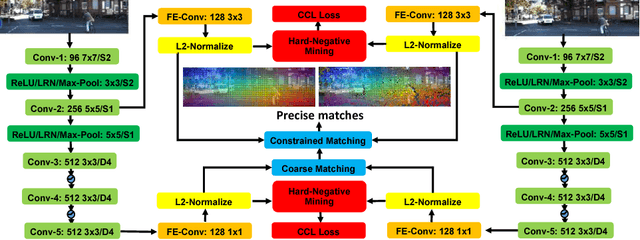
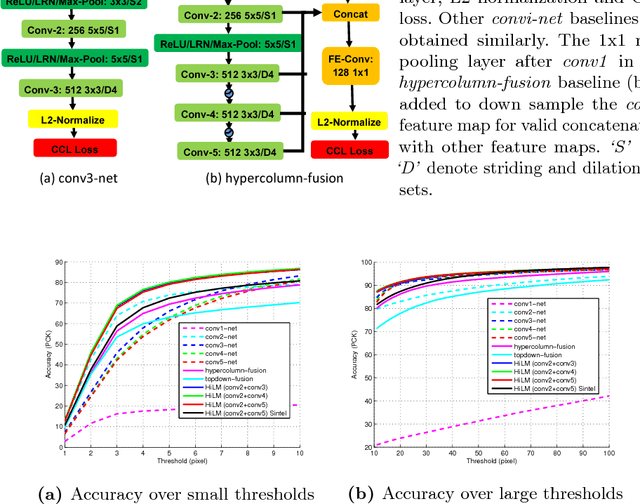
Interest point descriptors have fueled progress on almost every problem in computer vision. Recent advances in deep neural networks have enabled task-specific learned descriptors that outperform hand-crafted descriptors on many problems. We demonstrate that commonly used metric learning approaches do not optimally leverage the feature hierarchies learned in a Convolutional Neural Network (CNN), especially when applied to the task of geometric feature matching. While a metric loss applied to the deepest layer of a CNN, is often expected to yield ideal features irrespective of the task, in fact the growing receptive field as well as striding effects cause shallower features to be better at high precision matching tasks. We leverage this insight together with explicit supervision at multiple levels of the feature hierarchy for better regularization, to learn more effective descriptors in the context of geometric matching tasks. Further, we propose to use activation maps at different layers of a CNN, as an effective and principled replacement for the multi-resolution image pyramids often used for matching tasks. We propose concrete CNN architectures employing these ideas, and evaluate them on multiple datasets for 2D and 3D geometric matching as well as optical flow, demonstrating state-of-the-art results and generalization across datasets.
Deep Supervision with Intermediate Concepts
Jul 20, 2018



Recent data-driven approaches to scene interpretation predominantly pose inference as an end-to-end black-box mapping, commonly performed by a Convolutional Neural Network (CNN). However, decades of work on perceptual organization in both human and machine vision suggests that there are often intermediate representations that are intrinsic to an inference task, and which provide essential structure to improve generalization. In this work, we explore an approach for injecting prior domain structure into neural network training by supervising hidden layers of a CNN with intermediate concepts that normally are not observed in practice. We formulate a probabilistic framework which formalizes these notions and predicts improved generalization via this deep supervision method. One advantage of this approach is that we are able to train only from synthetic CAD renderings of cluttered scenes, where concept values can be extracted, but apply the results to real images. Our implementation achieves the state-of-the-art performance of 2D/3D keypoint localization and image classification on real image benchmarks, including KITTI, PASCAL VOC, PASCAL3D+, IKEA, and CIFAR100. We provide additional evidence that our approach outperforms alternative forms of supervision, such as multi-task networks.