 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo LLMs for Temporal Reasoning in Long Videos
Dec 04, 2024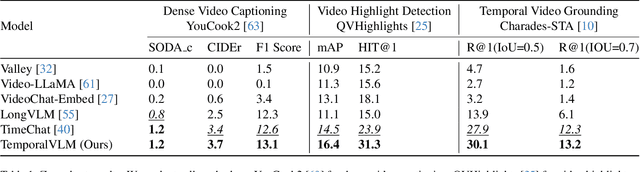
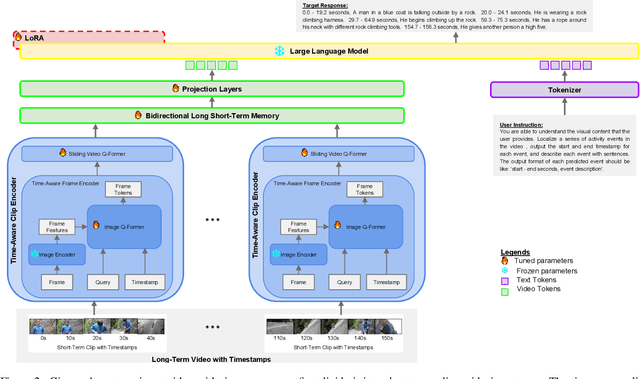


This paper introduces TemporalVLM, a video large language model capable of effective temporal reasoning and fine-grained understanding in long videos. At the core, our approach includes a visual encoder for mapping a long-term input video into features which are time-aware and contain both local and global cues. In particular, it first divides the input video into short-term clips, which are jointly encoded with their timestamps into time-sensitive local features. Next, the local features are passed through a bidirectional long short-term memory module for global feature aggregation. The extracted time-aware and multi-level features are important for accurate temporal reasoning and fine-grained understanding in long videos. Moreover, to facilitate the evaluation of TemporalVLM, we present a large-scale long video dataset of industry assembly processes, namely IndustryASM, which consists of videos recorded on factory floors with actions and timestamps annotated by industrial engineers for time and motion studies and temporal action segmentation evaluation. Finally, extensive experiments on datasets of long videos, including TimeIT and IndustryASM, show that TemporalVLM achieves superior performance than previous methods across temporal reasoning and fine-grained understanding tasks, namely dense video captioning, temporal video grounding, video highlight detection, and temporal action segmentation.
Action Segmentation Using 2D Skeleton Heatmaps
Sep 19, 2023



This paper presents a 2D skeleton-based action segmentation method with applications in fine-grained human activity recognition. In contrast with state-of-the-art methods which directly take sequences of 3D skeleton coordinates as inputs and apply Graph Convolutional Networks (GCNs) for spatiotemporal feature learning, our main idea is to use sequences of 2D skeleton heatmaps as inputs and employ Temporal Convolutional Networks (TCNs) to extract spatiotemporal features. Despite lacking 3D information, our approach yields comparable/superior performances and better robustness against missing keypoints than previous methods on action segmentation datasets. Moreover, we improve the performances further by using both 2D skeleton heatmaps and RGB videos as inputs. To our best knowledge, this is the first work to utilize 2D skeleton heatmap inputs and the first work to explore 2D skeleton+RGB fusion for action segmentation.