 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDT: Teaching Detectors to Track without Fully Annotated Videos
May 11, 2022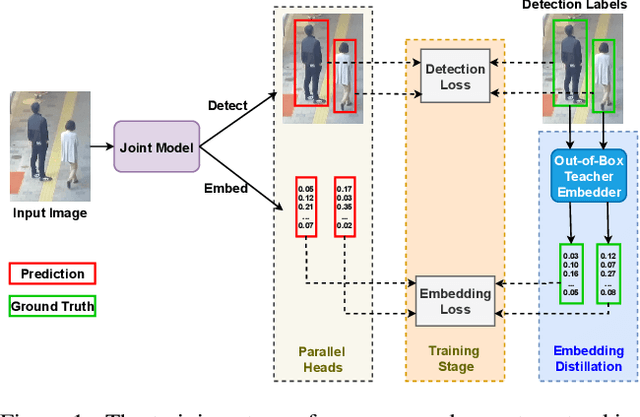

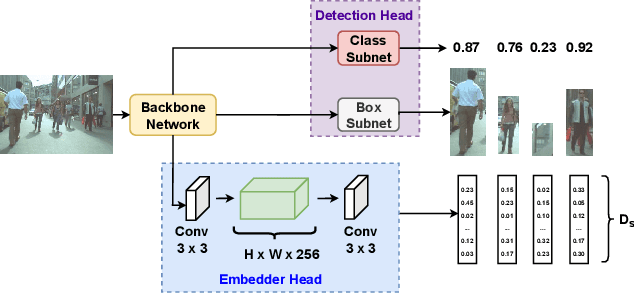
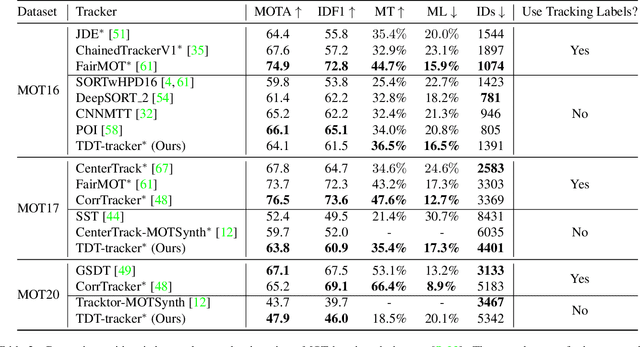
Recently, one-stage trackers that use a joint model to predict both detections and appearance embeddings in one forward pass received much attention and achieved state-of-the-art results on the Multi-Object Tracking (MOT) benchmarks. However, their success depends on the availability of videos that are fully annotated with tracking data, which is expensive and hard to obtain. This can limit the model generalization. In comparison, the two-stage approach, which performs detection and embedding separately, is slower but easier to train as their data are easier to annotate. We propose to combine the best of the two worlds through a data distillation approach. Specifically, we use a teacher embedder, trained on Re-ID datasets, to generate pseudo appearance embedding labels for the detection datasets. Then, we use the augmented dataset to train a detector that is also capable of regressing these pseudo-embeddings in a fully-convolutional fashion. Our proposed one-stage solution matches the two-stage counterpart in quality but is 3 times faster. Even though the teacher embedder has not seen any tracking data during training, our proposed tracker achieves competitive performance with some popular trackers (e.g. JDE) trained with fully labeled tracking data.
Hierarchical Metric Learning and Matching for 2D and 3D Geometric Correspondences
Aug 02, 2018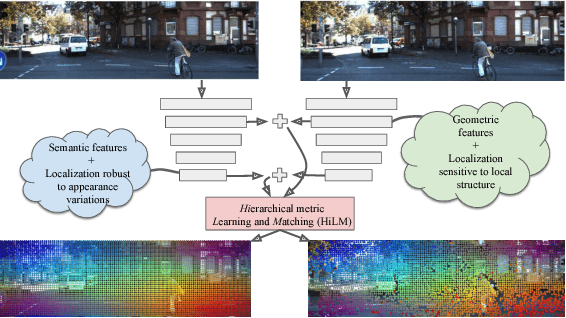
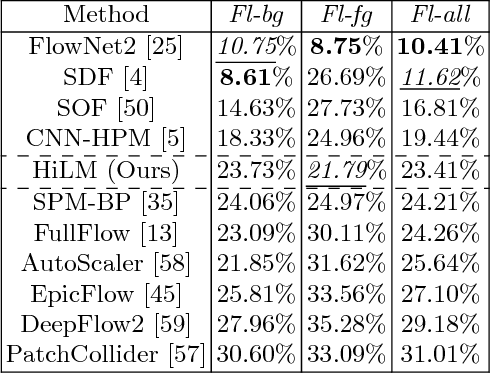
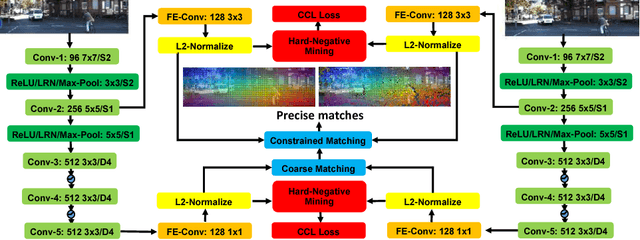
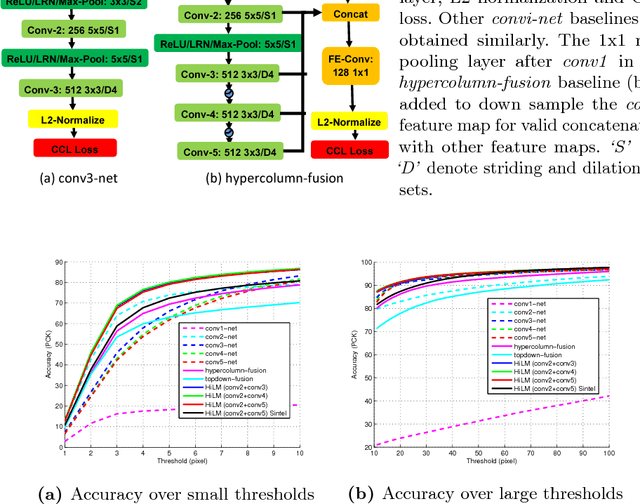
Interest point descriptors have fueled progress on almost every problem in computer vision. Recent advances in deep neural networks have enabled task-specific learned descriptors that outperform hand-crafted descriptors on many problems. We demonstrate that commonly used metric learning approaches do not optimally leverage the feature hierarchies learned in a Convolutional Neural Network (CNN), especially when applied to the task of geometric feature matching. While a metric loss applied to the deepest layer of a CNN, is often expected to yield ideal features irrespective of the task, in fact the growing receptive field as well as striding effects cause shallower features to be better at high precision matching tasks. We leverage this insight together with explicit supervision at multiple levels of the feature hierarchy for better regularization, to learn more effective descriptors in the context of geometric matching tasks. Further, we propose to use activation maps at different layers of a CNN, as an effective and principled replacement for the multi-resolution image pyramids often used for matching tasks. We propose concrete CNN architectures employing these ideas, and evaluate them on multiple datasets for 2D and 3D geometric matching as well as optical flow, demonstrating state-of-the-art results and generalization across datasets.
Fundamental Matrix Estimation: A Study of Error Criteria
Jun 24, 2017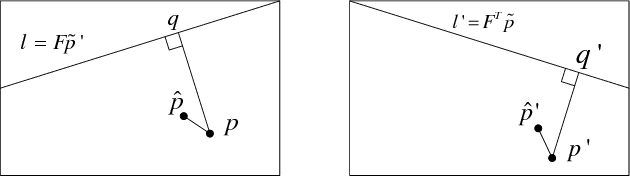
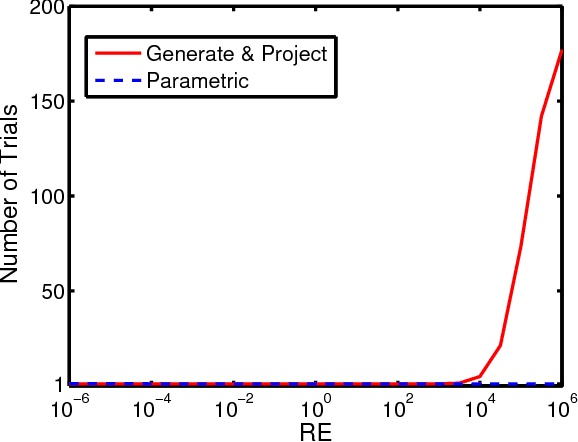

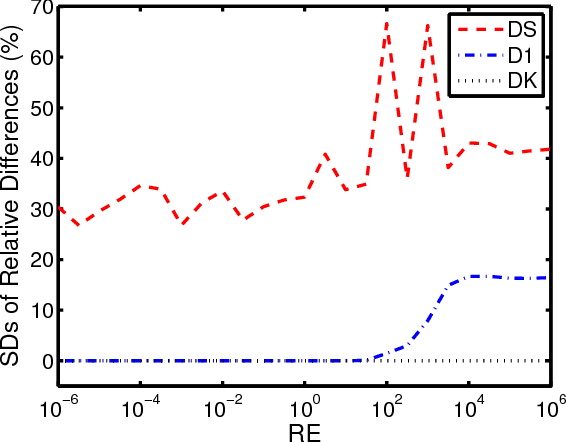
The fundamental matrix (FM) describes the geometric relations that exist between two images of the same scene. Different error criteria are used for estimating FMs from an input set of correspondences. In this paper, the accuracy and efficiency aspects of the different error criteria were studied. We mathematically and experimentally proved that the most popular error criterion, the symmetric epipolar distance, is biased. It was also shown that despite the similarity between the algebraic expressions of the symmetric epipolar distance and Sampson distance, they have different accuracy properties. In addition, a new error criterion, Kanatani distance, was proposed and was proved to be the most effective for use during the outlier removal phase from accuracy and efficiency perspectives. To thoroughly test the accuracy of the different error criteria, we proposed a randomized algorithm for Reprojection Error-based Correspondence Generation (RE-CG). As input, RE-CG takes an FM and a desired reprojection error value $d$. As output, RE-CG generates a random correspondence having that error value. Mathematical analysis of this algorithm revealed that the success probability for any given trial is 1 - (2/3)^2 at best and is 1 - (6/7)^2 at worst while experiments demonstrated that the algorithm often succeeds after only one trial.