 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParGANDA: Making Synthetic Pedestrians A Reality For Object Detection
Jul 21, 2023



Object detection is the key technique to a number of Computer Vision applications, but it often requires large amounts of annotated data to achieve decent results. Moreover, for pedestrian detection specifically, the collected data might contain some personally identifiable information (PII), which is highly restricted in many countries. This label intensive and privacy concerning task has recently led to an increasing interest in training the detection models using synthetically generated pedestrian datasets collected with a photo-realistic video game engine. The engine is able to generate unlimited amounts of data with precise and consistent annotations, which gives potential for significant gains in the real-world applications. However, the use of synthetic data for training introduces a synthetic-to-real domain shift aggravating the final performance. To close the gap between the real and synthetic data, we propose to use a Generative Adversarial Network (GAN), which performsparameterized unpaired image-to-image translation to generate more realistic images. The key benefit of using the GAN is its intrinsic preference of low-level changes to geometric ones, which means annotations of a given synthetic image remain accurate even after domain translation is performed thus eliminating the need for labeling real data. We extensively experimented with the proposed method using MOTSynth dataset to train and MOT17 and MOT20 detection datasets to test, with experimental results demonstrating the effectiveness of this method. Our approach not only produces visually plausible samples but also does not require any labels of the real domain thus making it applicable to the variety of downstream tasks.
TDT: Teaching Detectors to Track without Fully Annotated Videos
May 11, 2022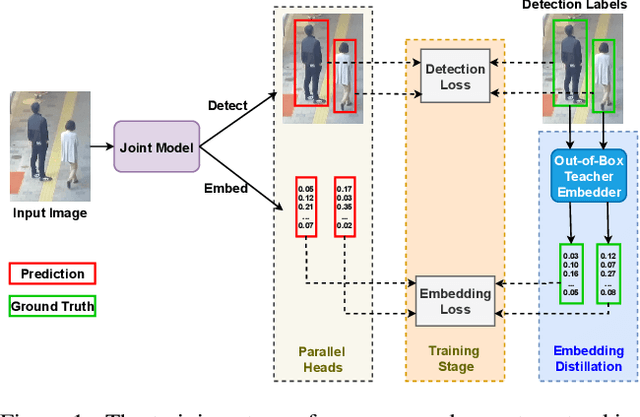

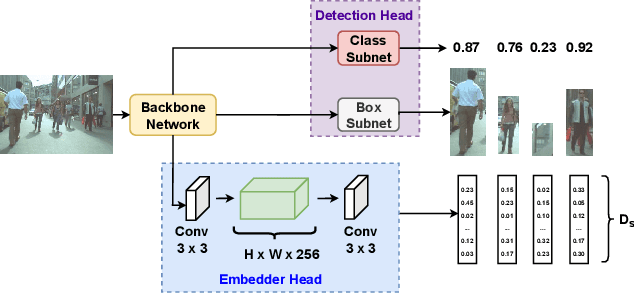
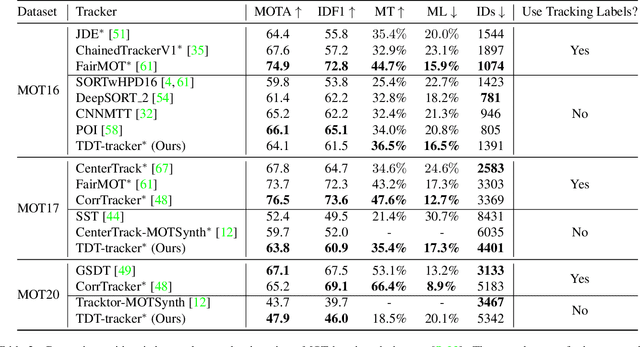
Recently, one-stage trackers that use a joint model to predict both detections and appearance embeddings in one forward pass received much attention and achieved state-of-the-art results on the Multi-Object Tracking (MOT) benchmarks. However, their success depends on the availability of videos that are fully annotated with tracking data, which is expensive and hard to obtain. This can limit the model generalization. In comparison, the two-stage approach, which performs detection and embedding separately, is slower but easier to train as their data are easier to annotate. We propose to combine the best of the two worlds through a data distillation approach. Specifically, we use a teacher embedder, trained on Re-ID datasets, to generate pseudo appearance embedding labels for the detection datasets. Then, we use the augmented dataset to train a detector that is also capable of regressing these pseudo-embeddings in a fully-convolutional fashion. Our proposed one-stage solution matches the two-stage counterpart in quality but is 3 times faster. Even though the teacher embedder has not seen any tracking data during training, our proposed tracker achieves competitive performance with some popular trackers (e.g. JDE) trained with fully labeled tracking data.
Towards a Semantic Perceptual Image Metric
Aug 01, 2018
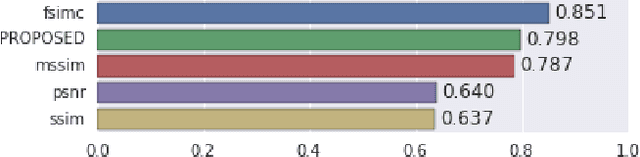
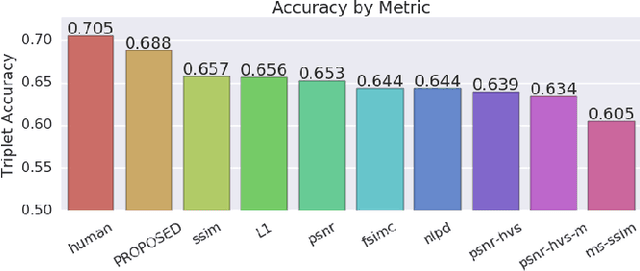

We present a full reference, perceptual image metric based on VGG-16, an artificial neural network trained on object classification. We fit the metric to a new database based on 140k unique images annotated with ground truth by human raters who received minimal instruction. The resulting metric shows competitive performance on TID 2013, a database widely used to assess image quality assessments methods. More interestingly, it shows strong responses to objects potentially carrying semantic relevance such as faces and text, which we demonstrate using a visualization technique and ablation experiments. In effect, the metric appears to model a higher influence of semantic context on judgments, which we observe particularly in untrained raters. As the vast majority of users of image processing systems are unfamiliar with Image Quality Assessment (IQA) tasks, these findings may have significant impact on real-world applications of perceptual metrics.
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Apr 30, 2018


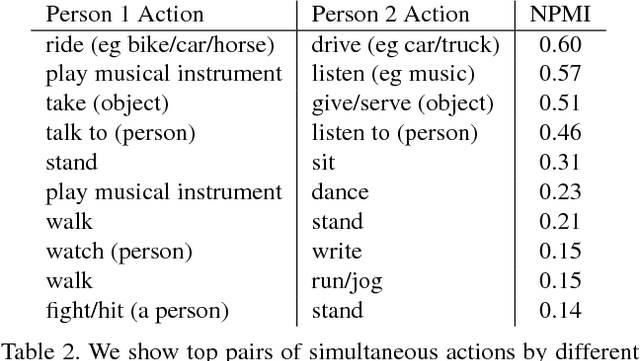
This paper introduces a video dataset of spatio-temporally localized Atomic Visual Actions (AVA). The AVA dataset densely annotates 80 atomic visual actions in 430 15-minute video clips, where actions are localized in space and time, resulting in 1.58M action labels with multiple labels per person occurring frequently. The key characteristics of our dataset are: (1) the definition of atomic visual actions, rather than composite actions; (2) precise spatio-temporal annotations with possibly multiple annotations for each person; (3) exhaustive annotation of these atomic actions over 15-minute video clips; (4) people temporally linked across consecutive segments; and (5) using movies to gather a varied set of action representations. This departs from existing datasets for spatio-temporal action recognition, which typically provide sparse annotations for composite actions in short video clips. We will release the dataset publicly. AVA, with its realistic scene and action complexity, exposes the intrinsic difficulty of action recognition. To benchmark this, we present a novel approach for action localization that builds upon the current state-of-the-art methods, and demonstrates better performance on JHMDB and UCF101-24 categories. While setting a new state of the art on existing datasets, the overall results on AVA are low at 15.6% mAP, underscoring the need for developing new approaches for video understanding.
End-to-End Interpretation of the French Street Name Signs Dataset
Feb 13, 2017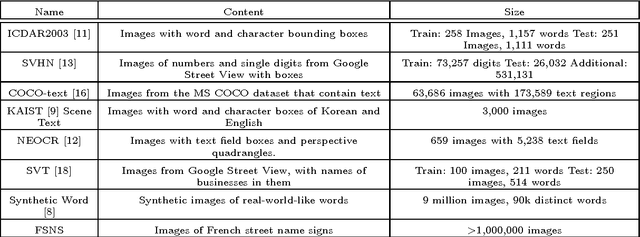


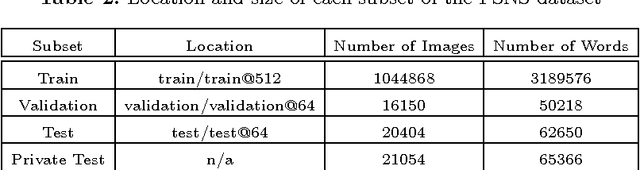
We introduce the French Street Name Signs (FSNS) Dataset consisting of more than a million images of street name signs cropped from Google Street View images of France. Each image contains several views of the same street name sign. Every image has normalized, title case folded ground-truth text as it would appear on a map. We believe that the FSNS dataset is large and complex enough to train a deep network of significant complexity to solve the street name extraction problem "end-to-end" or to explore the design trade-offs between a single complex engineered network and multiple sub-networks designed and trained to solve sub-problems. We present such an "end-to-end" network/graph for Tensor Flow and its results on the FSNS dataset.
* Presented at the IWRR workshop at ECCV 2016