 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeInversion: Learning to Detect Images from Unseen Text-to-Image Models by Inverting Stable Diffusion
Jun 12, 2024Due to the high potential for abuse of GenAI systems, the task of detecting synthetic images has recently become of great interest to the research community. Unfortunately, existing image-space detectors quickly become obsolete as new high-fidelity text-to-image models are developed at blinding speed. In this work, we propose a new synthetic image detector that uses features obtained by inverting an open-source pre-trained Stable Diffusion model. We show that these inversion features enable our detector to generalize well to unseen generators of high visual fidelity (e.g., DALL-E 3) even when the detector is trained only on lower fidelity fake images generated via Stable Diffusion. This detector achieves new state-of-the-art across multiple training and evaluation setups. Moreover, we introduce a new challenging evaluation protocol that uses reverse image search to mitigate stylistic and thematic biases in the detector evaluation. We show that the resulting evaluation scores align well with detectors' in-the-wild performance, and release these datasets as public benchmarks for future research.
* Project page: https://fake-inversion.github.io
Directed Diffusion: Direct Control of Object Placement through Attention Guidance
Feb 25, 2023Text-guided diffusion models such as DALLE-2, IMAGEN, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are very high quality as well. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. Unfortunately, this capability to ``direct'' the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work we take a particularly straightforward approach to providing the needed direction, by injecting ``activation'' at desired positions in the cross-attention maps corresponding to the objects under control, while attenuating the remainder of the map. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. To the best of our knowledge, our Directed Diffusion method is the first diffusion technique that provides positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
NewsStories: Illustrating articles with visual summaries
Aug 14, 2022
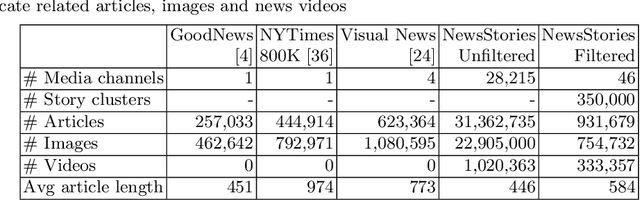
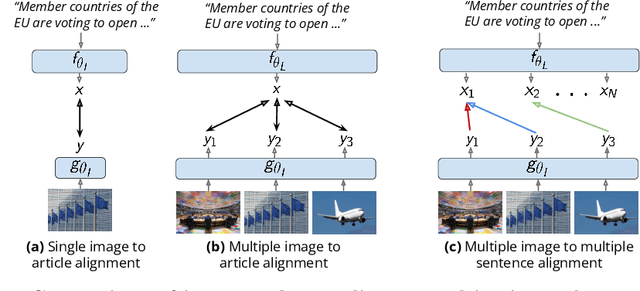
Recent self-supervised approaches have used large-scale image-text datasets to learn powerful representations that transfer to many tasks without finetuning. These methods often assume that there is one-to-one correspondence between its images and their (short) captions. However, many tasks require reasoning about multiple images and long text narratives, such as describing news articles with visual summaries. Thus, we explore a novel setting where the goal is to learn a self-supervised visual-language representation that is robust to varying text length and the number of images. In addition, unlike prior work which assumed captions have a literal relation to the image, we assume images only contain loose illustrative correspondence with the text. To explore this problem, we introduce a large-scale multimodal dataset containing over 31M articles, 22M images and 1M videos. We show that state-of-the-art image-text alignment methods are not robust to longer narratives with multiple images. Finally, we introduce an intuitive baseline that outperforms these methods on zero-shot image-set retrieval by 10% on the GoodNews dataset.
Geo-Aware Networks for Fine Grained Recognition
Jun 04, 2019
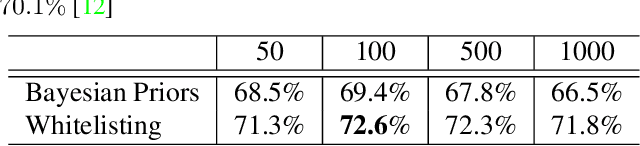
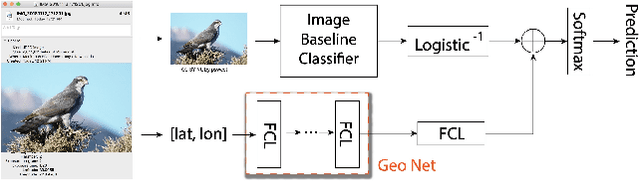
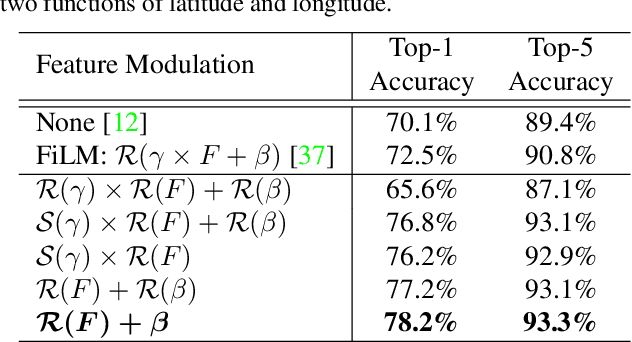
Fine grained recognition distinguishes among categories with subtle visual differences. To help identify fine grained categories, other information besides images has been used. However, there has been little effort on using geolocation information to improve fine grained classification accuracy. Our contributions to this field are twofold. First, to the best of our knowledge, this is the first paper which systematically examined various ways of incorporating geolocation information to fine grained images classification - from geolocation priors, to post-processing, to feature modulation. Secondly, to overcome the situation where no fine grained dataset has complete geolocation information, we introduce, and will make public, two fine grained datasets with geolocation by providing complementary information to existing popular datasets - iNaturalist and YFCC100M. Results on these datasets show that, the best geo-aware network can achieve 8.9% top-1 accuracy increase on iNaturalist and 5.9% increase on YFCC100M, compared with image only models' results. In addition, for small image baseline models like Mobilenet V2, the best geo-aware network gives 12.6% higher top-1 accuracy than image only model, achieving even higher performance than Inception V3 models without geolocation. Our work gives incentives to use geolocation information to improve fine grained recognition for both server and on-device models.
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
Aug 13, 2018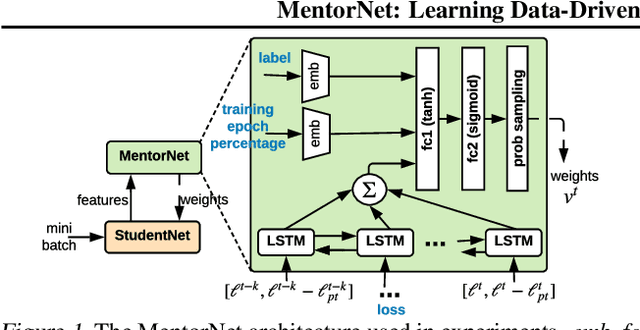
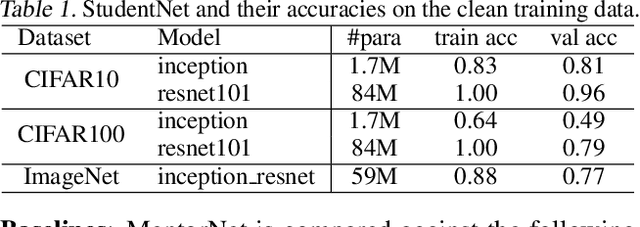

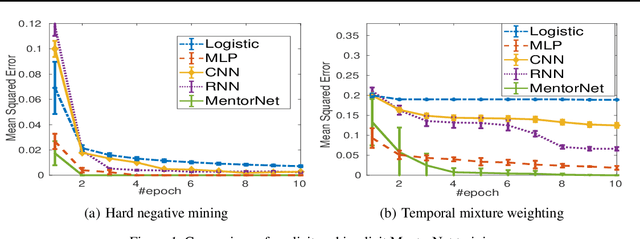
Recent deep networks are capable of memorizing the entire data even when the labels are completely random. To overcome the overfitting on corrupted labels, we propose a novel technique of learning another neural network, called MentorNet, to supervise the training of the base deep networks, namely, StudentNet. During training, MentorNet provides a curriculum (sample weighting scheme) for StudentNet to focus on the sample the label of which is probably correct. Unlike the existing curriculum that is usually predefined by human experts, MentorNet learns a data-driven curriculum dynamically with StudentNet. Experimental results demonstrate that our approach can significantly improve the generalization performance of deep networks trained on corrupted training data. Notably, to the best of our knowledge, we achieve the best-published result on WebVision, a large benchmark containing 2.2 million images of real-world noisy labels. The code are at https://github.com/google/mentornet
Towards a Semantic Perceptual Image Metric
Aug 01, 2018
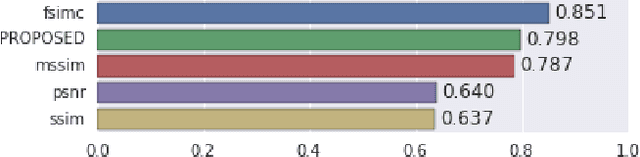
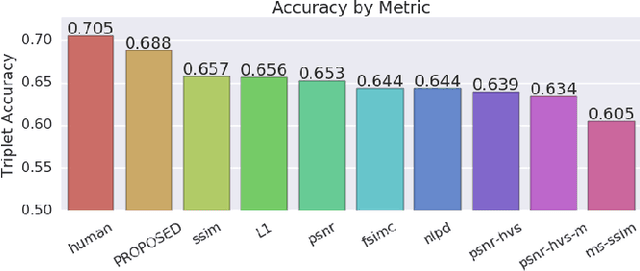

We present a full reference, perceptual image metric based on VGG-16, an artificial neural network trained on object classification. We fit the metric to a new database based on 140k unique images annotated with ground truth by human raters who received minimal instruction. The resulting metric shows competitive performance on TID 2013, a database widely used to assess image quality assessments methods. More interestingly, it shows strong responses to objects potentially carrying semantic relevance such as faces and text, which we demonstrate using a visualization technique and ablation experiments. In effect, the metric appears to model a higher influence of semantic context on judgments, which we observe particularly in untrained raters. As the vast majority of users of image processing systems are unfamiliar with Image Quality Assessment (IQA) tasks, these findings may have significant impact on real-world applications of perceptual metrics.
Improving the Robustness of Deep Neural Networks via Stability Training
Apr 15, 2016

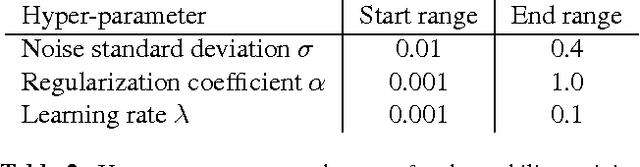

In this paper we address the issue of output instability of deep neural networks: small perturbations in the visual input can significantly distort the feature embeddings and output of a neural network. Such instability affects many deep architectures with state-of-the-art performance on a wide range of computer vision tasks. We present a general stability training method to stabilize deep networks against small input distortions that result from various types of common image processing, such as compression, rescaling, and cropping. We validate our method by stabilizing the state-of-the-art Inception architecture against these types of distortions. In addition, we demonstrate that our stabilized model gives robust state-of-the-art performance on large-scale near-duplicate detection, similar-image ranking, and classification on noisy datasets.
Pose Embeddings: A Deep Architecture for Learning to Match Human Poses
Jul 01, 2015


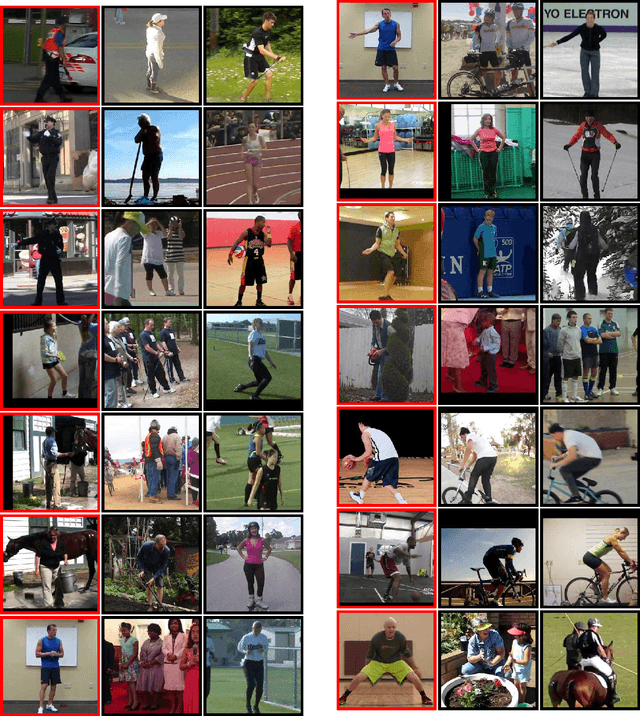
We present a method for learning an embedding that places images of humans in similar poses nearby. This embedding can be used as a direct method of comparing images based on human pose, avoiding potential challenges of estimating body joint positions. Pose embedding learning is formulated under a triplet-based distance criterion. A deep architecture is used to allow learning of a representation capable of making distinctions between different poses. Experiments on human pose matching and retrieval from video data demonstrate the potential of the method.
Learning Fine-grained Image Similarity with Deep Ranking
Apr 17, 2014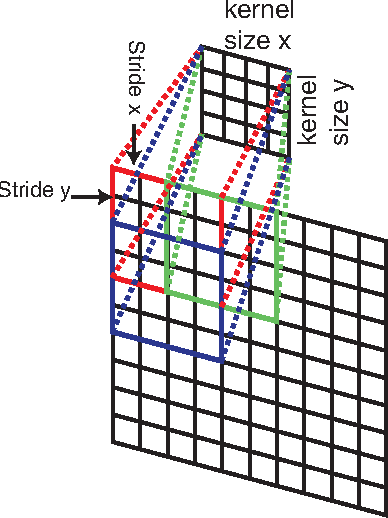
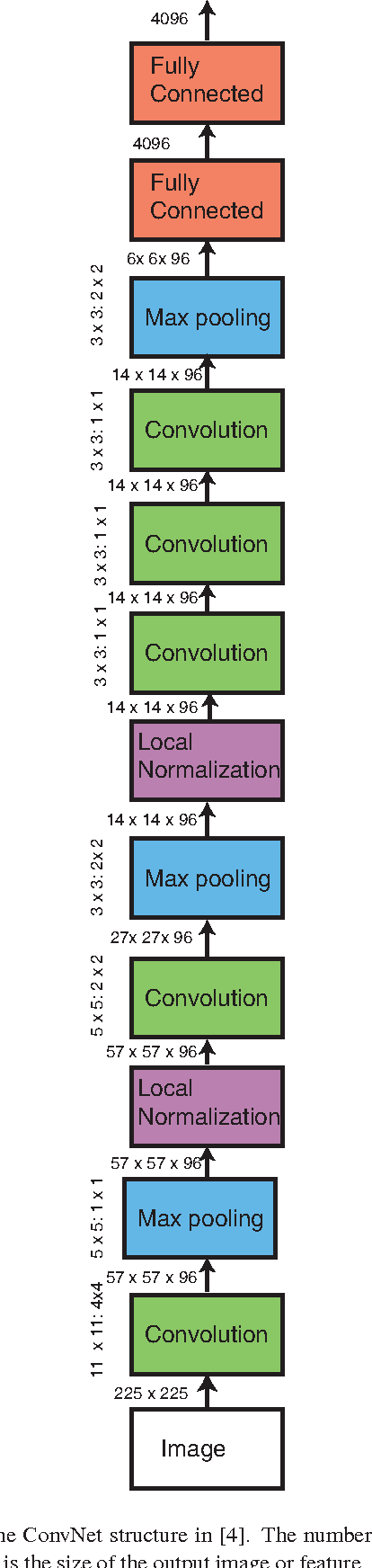

Learning fine-grained image similarity is a challenging task. It needs to capture between-class and within-class image differences. This paper proposes a deep ranking model that employs deep learning techniques to learn similarity metric directly from images.It has higher learning capability than models based on hand-crafted features. A novel multiscale network structure has been developed to describe the images effectively. An efficient triplet sampling algorithm is proposed to learn the model with distributed asynchronized stochastic gradient. Extensive experiments show that the proposed algorithm outperforms models based on hand-crafted visual features and deep classification models.
Deep Convolutional Ranking for Multilabel Image Annotation
Apr 14, 2014


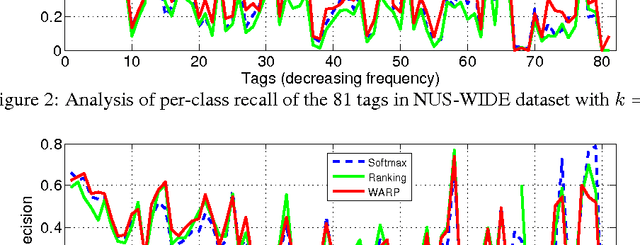
Multilabel image annotation is one of the most important challenges in computer vision with many real-world applications. While existing work usually use conventional visual features for multilabel annotation, features based on Deep Neural Networks have shown potential to significantly boost performance. In this work, we propose to leverage the advantage of such features and analyze key components that lead to better performances. Specifically, we show that a significant performance gain could be obtained by combining convolutional architectures with approximate top-$k$ ranking objectives, as thye naturally fit the multilabel tagging problem. Our experiments on the NUS-WIDE dataset outperforms the conventional visual features by about 10%, obtaining the best reported performance in the literature.