 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewsStories: Illustrating articles with visual summaries
Aug 14, 2022
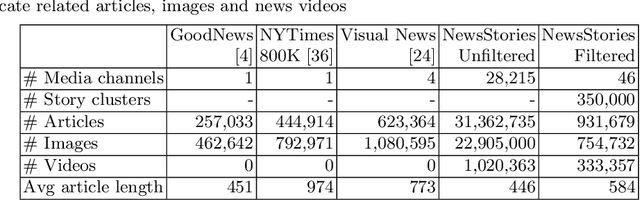
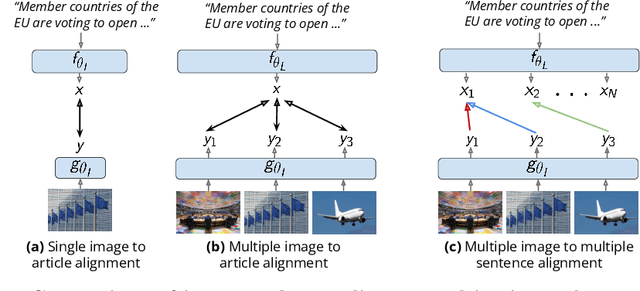
Recent self-supervised approaches have used large-scale image-text datasets to learn powerful representations that transfer to many tasks without finetuning. These methods often assume that there is one-to-one correspondence between its images and their (short) captions. However, many tasks require reasoning about multiple images and long text narratives, such as describing news articles with visual summaries. Thus, we explore a novel setting where the goal is to learn a self-supervised visual-language representation that is robust to varying text length and the number of images. In addition, unlike prior work which assumed captions have a literal relation to the image, we assume images only contain loose illustrative correspondence with the text. To explore this problem, we introduce a large-scale multimodal dataset containing over 31M articles, 22M images and 1M videos. We show that state-of-the-art image-text alignment methods are not robust to longer narratives with multiple images. Finally, we introduce an intuitive baseline that outperforms these methods on zero-shot image-set retrieval by 10% on the GoodNews dataset.
NASA: Neural Articulated Shape Approximation
Dec 06, 2019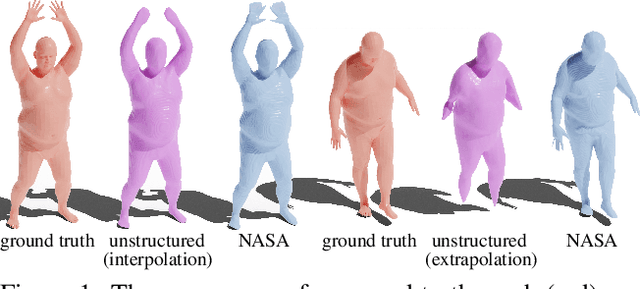
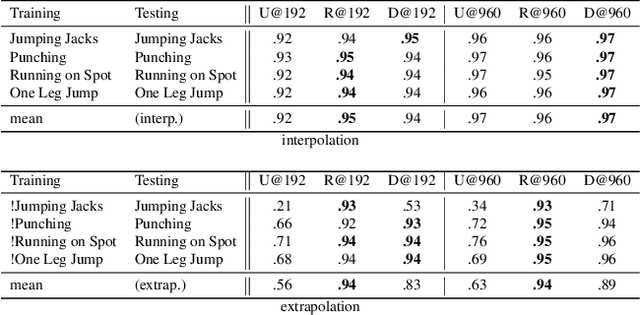


Efficient representation of articulated objects such as human bodies is an important problem in computer vision and graphics. To efficiently simulate deformation, existing approaches represent objects as meshes and deform them using skinning techniques. This paper introduces neural articulated shape approximation (NASA), a framework that enables efficient representation of articulated deformable objects using neural indicator functions parameterized by pose. In contrast to classic approaches, NASA avoids the need to convert between different representations. For occupancy testing, NASA circumvents the complexity of meshes and mitigates the issue of water-tightness. In comparison with regular grids and octrees, our approach provides high resolution without high memory use.
The Shattered Gradients Problem: If resnets are the answer, then what is the question?
Jun 06, 2018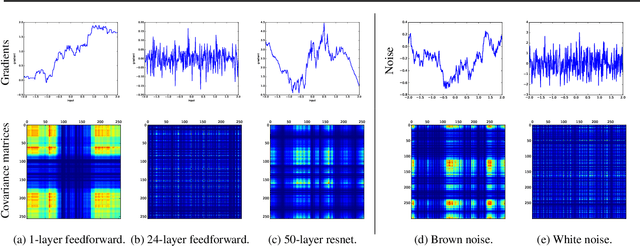

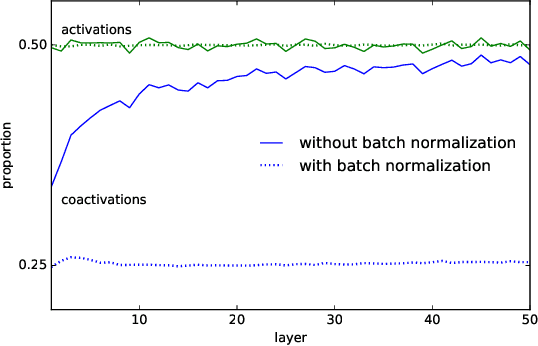
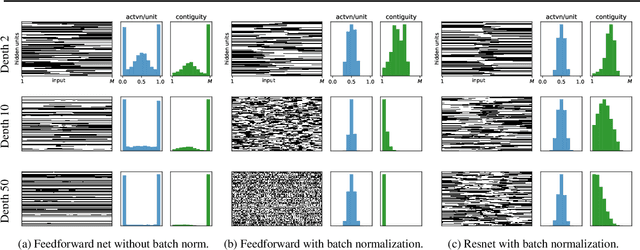
A long-standing obstacle to progress in deep learning is the problem of vanishing and exploding gradients. Although, the problem has largely been overcome via carefully constructed initializations and batch normalization, architectures incorporating skip-connections such as highway and resnets perform much better than standard feedforward architectures despite well-chosen initialization and batch normalization. In this paper, we identify the shattered gradients problem. Specifically, we show that the correlation between gradients in standard feedforward networks decays exponentially with depth resulting in gradients that resemble white noise whereas, in contrast, the gradients in architectures with skip-connections are far more resistant to shattering, decaying sublinearly. Detailed empirical evidence is presented in support of the analysis, on both fully-connected networks and convnets. Finally, we present a new "looks linear" (LL) initialization that prevents shattering, with preliminary experiments showing the new initialization allows to train very deep networks without the addition of skip-connections.
* ICML 2017, final version
Negentropic Planar Symmetry Detector
Mar 11, 2017
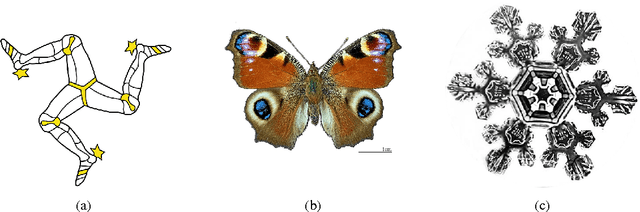
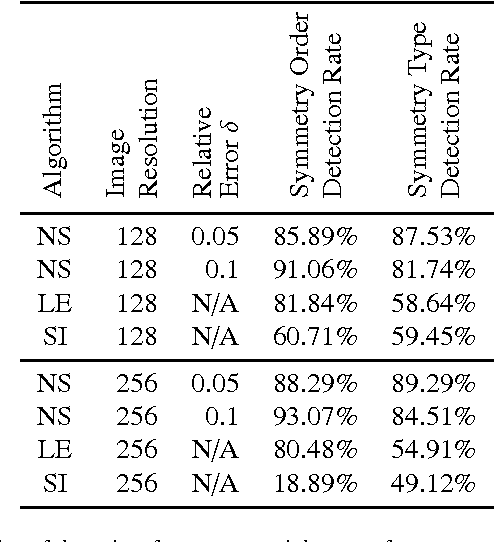
In this paper we observe that information theoretical concepts are valuable tools for extracting information from images and, in particular, information on image symmetries. It is shown that the problem of detecting reflectional and rotational symmetries in a two-dimensional image can be reduced to the problem of detecting point-symmetry and periodicity in one-dimensional negentropy functions. Based on these findings a detector of reflectional and rotational global symmetries in greyscale images is constructed. We discuss the importance of high precision in symmetry detection in applications arising from quality control and illustrate how the proposed method satisfies this requirement. Finally, a superior performance of our method to other existing methods, demonstrated by the results of a rigorous experimental verification, is an indication that our approach rooted in information theory is a promising direction in a development of a robust and widely applicable symmetry detector.