 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Managing AI Risks in an Era of Rapid Progress
Oct 26, 2023In this short consensus paper, we outline risks from upcoming, advanced AI systems. We examine large-scale social harms and malicious uses, as well as an irreversible loss of human control over autonomous AI systems. In light of rapid and continuing AI progress, we propose priorities for AI R&D and governance.
The Forward-Forward Algorithm: Some Preliminary Investigations
Dec 27, 2022
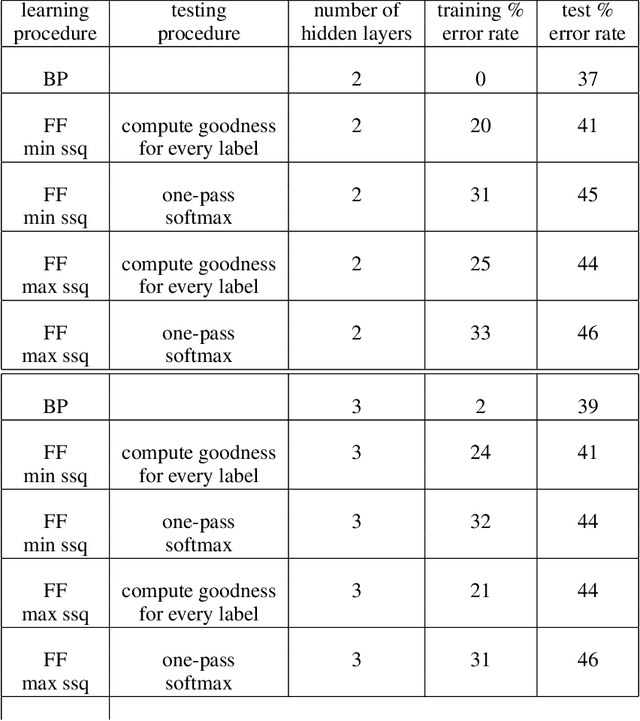

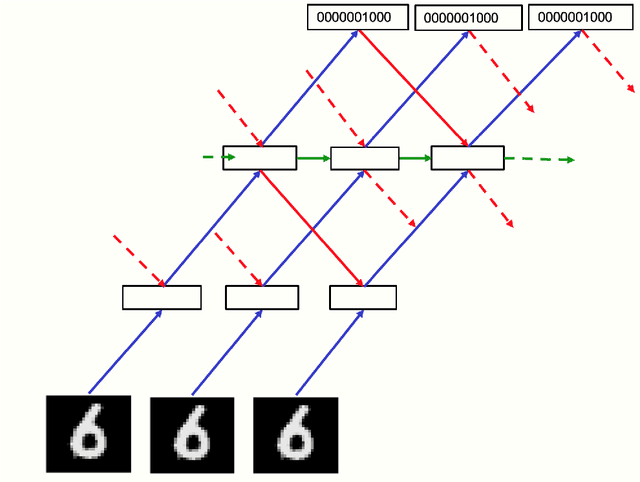
The aim of this paper is to introduce a new learning procedure for neural networks and to demonstrate that it works well enough on a few small problems to be worth further investigation. The Forward-Forward algorithm replaces the forward and backward passes of backpropagation by two forward passes, one with positive (i.e. real) data and the other with negative data which could be generated by the network itself. Each layer has its own objective function which is simply to have high goodness for positive data and low goodness for negative data. The sum of the squared activities in a layer can be used as the goodness but there are many other possibilities, including minus the sum of the squared activities. If the positive and negative passes could be separated in time, the negative passes could be done offline, which would make the learning much simpler in the positive pass and allow video to be pipelined through the network without ever storing activities or stopping to propagate derivatives.
Meta-Learning Fast Weight Language Models
Dec 05, 2022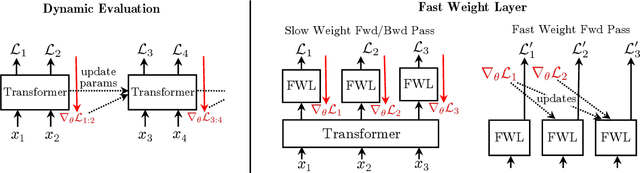
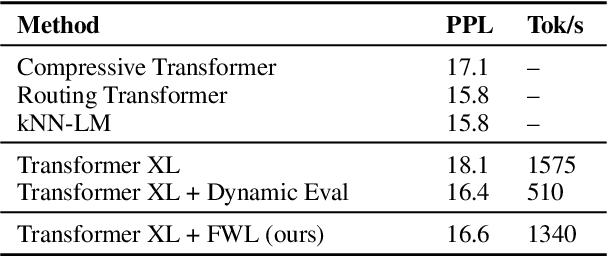
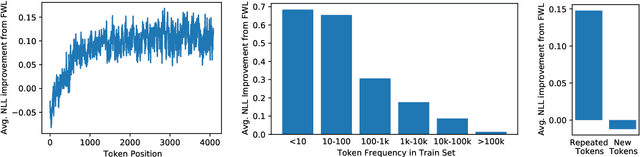
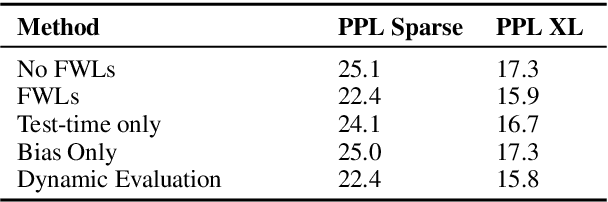
Dynamic evaluation of language models (LMs) adapts model parameters at test time using gradient information from previous tokens and substantially improves LM performance. However, it requires over 3x more compute than standard inference. We present Fast Weight Layers (FWLs), a neural component that provides the benefits of dynamic evaluation much more efficiently by expressing gradient updates as linear attention. A key improvement over dynamic evaluation is that FWLs can also be applied at training time so the model learns to make good use of gradient updates. FWLs can easily be added on top of existing transformer models, require relatively little extra compute or memory to run, and significantly improve language modeling perplexity.
Gaussian-Bernoulli RBMs Without Tears
Oct 19, 2022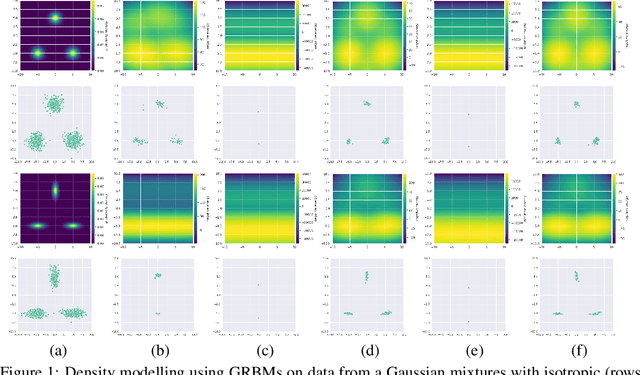

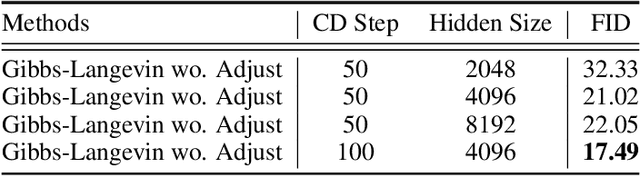
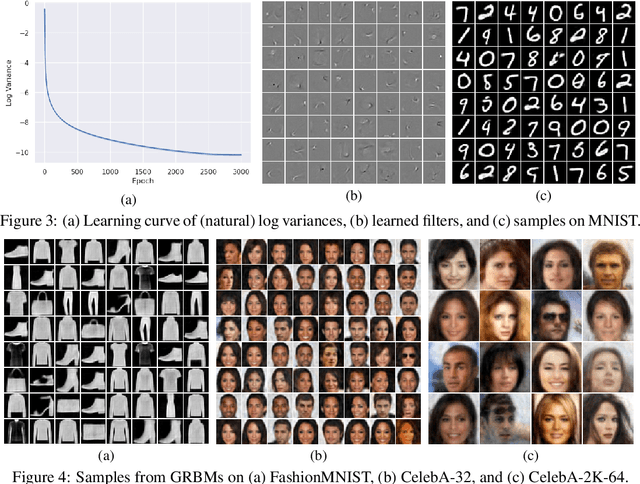
We revisit the challenging problem of training Gaussian-Bernoulli restricted Boltzmann machines (GRBMs), introducing two innovations. We propose a novel Gibbs-Langevin sampling algorithm that outperforms existing methods like Gibbs sampling. We propose a modified contrastive divergence (CD) algorithm so that one can generate images with GRBMs starting from noise. This enables direct comparison of GRBMs with deep generative models, improving evaluation protocols in the RBM literature. Moreover, we show that modified CD and gradient clipping are enough to robustly train GRBMs with large learning rates, thus removing the necessity of various tricks in the literature. Experiments on Gaussian Mixtures, MNIST, FashionMNIST, and CelebA show GRBMs can generate good samples, despite their single-hidden-layer architecture. Our code is released at: \url{https://github.com/lrjconan/GRBM}.
A Generalist Framework for Panoptic Segmentation of Images and Videos
Oct 12, 2022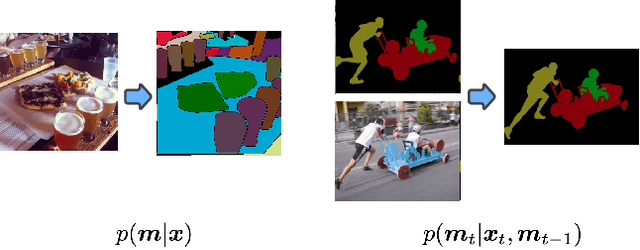
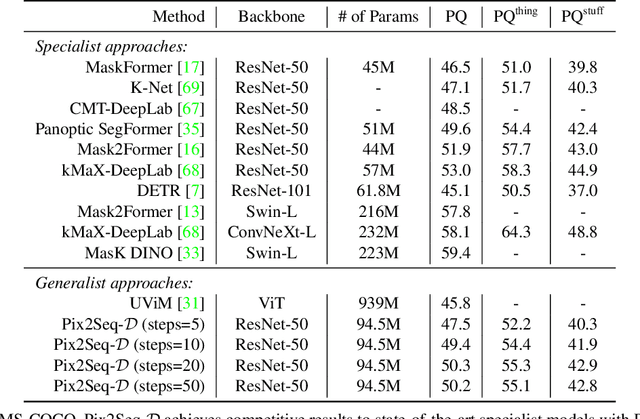
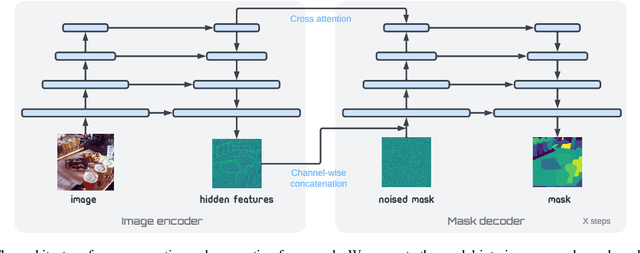
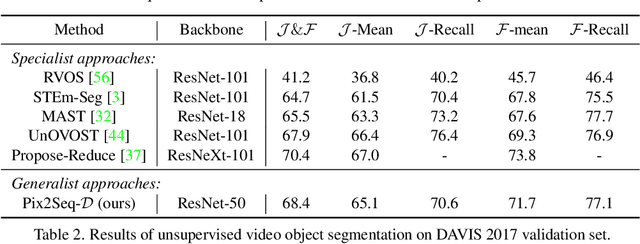
Panoptic segmentation assigns semantic and instance ID labels to every pixel of an image. As permutations of instance IDs are also valid solutions, the task requires learning of high-dimensional one-to-many mapping. As a result, state-of-the-art approaches use customized architectures and task-specific loss functions. We formulate panoptic segmentation as a discrete data generation problem, without relying on inductive bias of the task. A diffusion model based on analog bits is used to model panoptic masks, with a simple, generic architecture and loss function. By simply adding past predictions as a conditioning signal, our method is capable of modeling video (in a streaming setting) and thereby learns to track object instances automatically. With extensive experiments, we demonstrate that our generalist approach can perform competitively to state-of-the-art specialist methods in similar settings.
Scaling Forward Gradient With Local Losses
Oct 07, 2022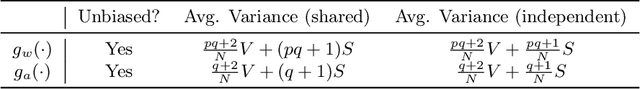

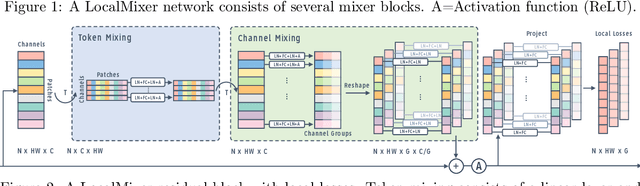
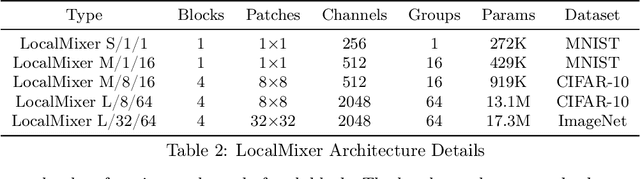
Forward gradient learning computes a noisy directional gradient and is a biologically plausible alternative to backprop for learning deep neural networks. However, the standard forward gradient algorithm, when applied naively, suffers from high variance when the number of parameters to be learned is large. In this paper, we propose a series of architectural and algorithmic modifications that together make forward gradient learning practical for standard deep learning benchmark tasks. We show that it is possible to substantially reduce the variance of the forward gradient estimator by applying perturbations to activations rather than weights. We further improve the scalability of forward gradient by introducing a large number of local greedy loss functions, each of which involves only a small number of learnable parameters, and a new MLPMixer-inspired architecture, LocalMixer, that is more suitable for local learning. Our approach matches backprop on MNIST and CIFAR-10 and significantly outperforms previously proposed backprop-free algorithms on ImageNet.
Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning
Aug 08, 2022
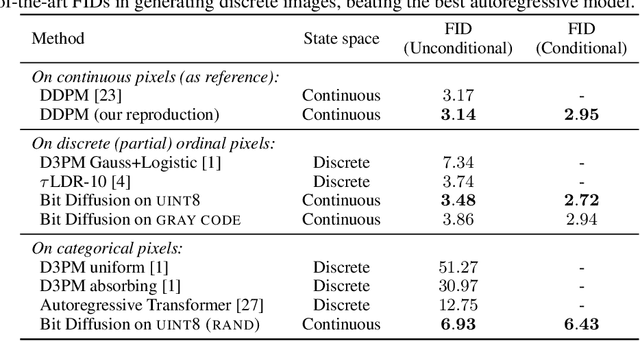


We present Bit Diffusion: a simple and generic approach for generating discrete data with continuous diffusion models. The main idea behind our approach is to first represent the discrete data as binary bits, and then train a continuous diffusion model to model these bits as real numbers which we call analog bits. To generate samples, the model first generates the analog bits, which are then thresholded to obtain the bits that represent the discrete variables. We further propose two simple techniques, namely Self-Conditioning and Asymmetric Time Intervals, which lead to a significant improvement in sample quality. Despite its simplicity, the proposed approach can achieve strong performance in both discrete image generation and image captioning tasks. For discrete image generation, we significantly improve previous state-of-the-art on both CIFAR-10 (which has 3K discrete 8-bit tokens) and ImageNet-64x64 (which has 12K discrete 8-bit tokens), outperforming the best autoregressive model in both sample quality (measured by FID) and efficiency. For image captioning on MS-COCO dataset, our approach achieves competitive results compared to autoregressive models.
A Unified Sequence Interface for Vision Tasks
Jun 15, 2022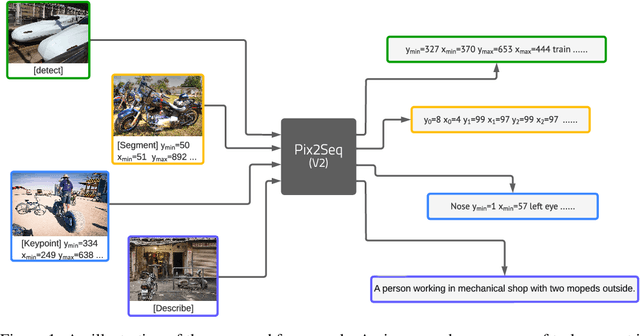
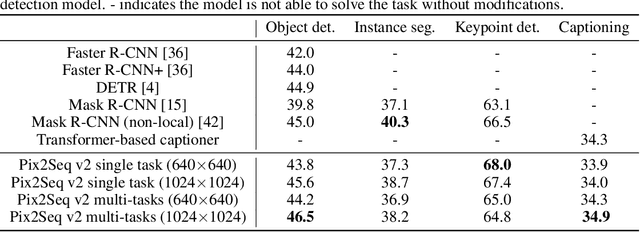
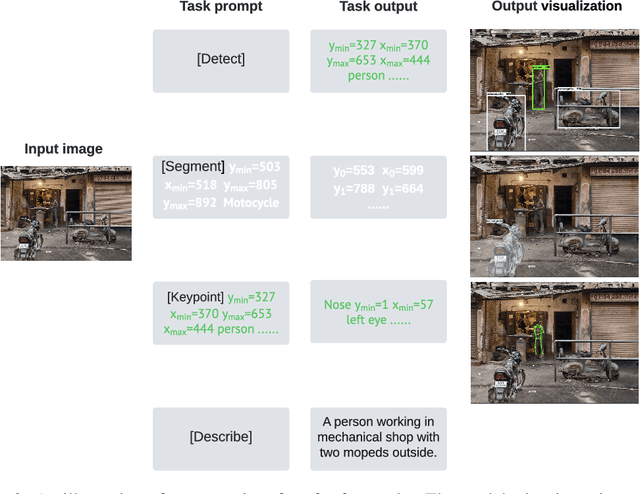

While language tasks are naturally expressed in a single, unified, modeling framework, i.e., generating sequences of tokens, this has not been the case in computer vision. As a result, there is a proliferation of distinct architectures and loss functions for different vision tasks. In this work we show that a diverse set of "core" computer vision tasks can also be unified if formulated in terms of a shared pixel-to-sequence interface. We focus on four tasks, namely, object detection, instance segmentation, keypoint detection, and image captioning, all with diverse types of outputs, e.g., bounding boxes or dense masks. Despite that, by formulating the output of each task as a sequence of discrete tokens with a unified interface, we show that one can train a neural network with a single model architecture and loss function on all these tasks, with no task-specific customization. To solve a specific task, we use a short prompt as task description, and the sequence output adapts to the prompt so it can produce task-specific output. We show that such a model can achieve competitive performance compared to well-established task-specific models.
Robust and Efficient Medical Imaging with Self-Supervision
May 19, 2022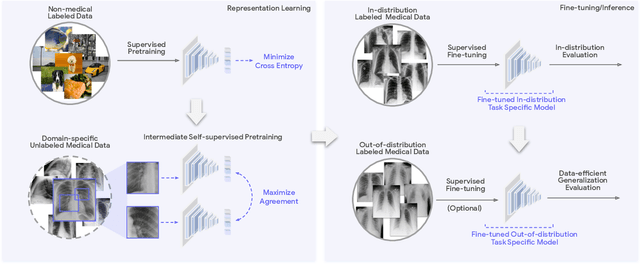
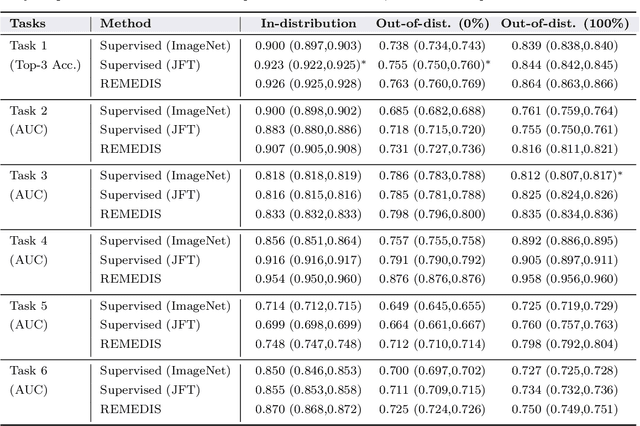
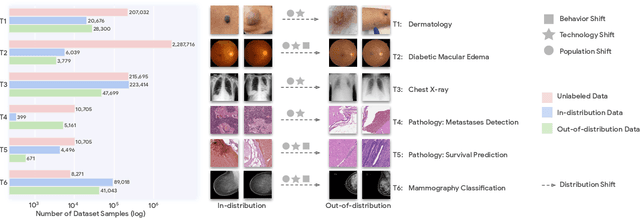

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.