 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo generative video models learn physical principles from watching videos?
Jan 14, 2025



AI video generation is undergoing a revolution, with quality and realism advancing rapidly. These advances have led to a passionate scientific debate: Do video models learn ``world models'' that discover laws of physics -- or, alternatively, are they merely sophisticated pixel predictors that achieve visual realism without understanding the physical principles of reality? We address this question by developing Physics-IQ, a comprehensive benchmark dataset that can only be solved by acquiring a deep understanding of various physical principles, like fluid dynamics, optics, solid mechanics, magnetism and thermodynamics. We find that across a range of current models (Sora, Runway, Pika, Lumiere, Stable Video Diffusion, and VideoPoet), physical understanding is severely limited, and unrelated to visual realism. At the same time, some test cases can already be successfully solved. This indicates that acquiring certain physical principles from observation alone may be possible, but significant challenges remain. While we expect rapid advances ahead, our work demonstrates that visual realism does not imply physical understanding. Our project page is at https://physics-iq.github.io; code at https://github.com/google-deepmind/physics-IQ-benchmark.
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Dec 22, 2023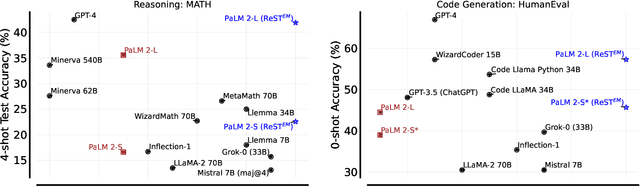
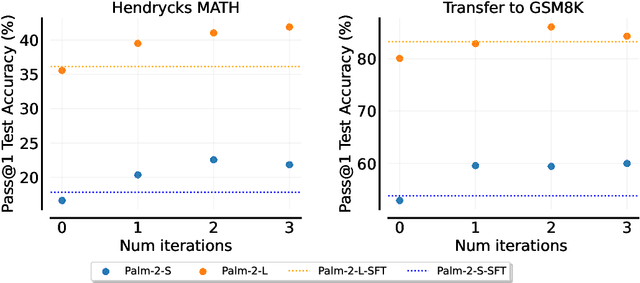
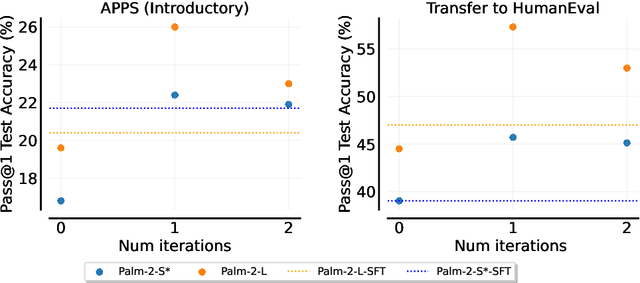
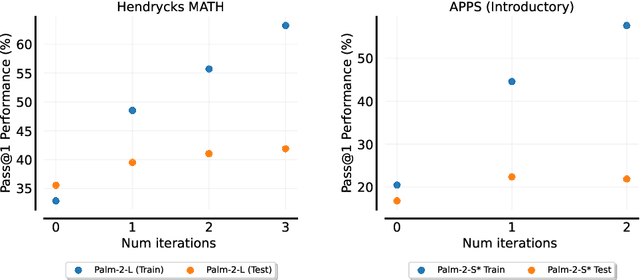
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Frontier Language Models are not Robust to Adversarial Arithmetic, or "What do I need to say so you agree 2+2=5?
Nov 15, 2023



We introduce and study the problem of adversarial arithmetic, which provides a simple yet challenging testbed for language model alignment. This problem is comprised of arithmetic questions posed in natural language, with an arbitrary adversarial string inserted before the question is complete. Even in the simple setting of 1-digit addition problems, it is easy to find adversarial prompts that make all tested models (including PaLM2, GPT4, Claude2) misbehave, and even to steer models to a particular wrong answer. We additionally provide a simple algorithm for finding successful attacks by querying those same models, which we name "prompt inversion rejection sampling" (PIRS). We finally show that models can be partially hardened against these attacks via reinforcement learning and via agentic constitutional loops. However, we were not able to make a language model fully robust against adversarial arithmetic attacks.
Testing GLOM's ability to infer wholes from ambiguous parts
Nov 29, 2022



The GLOM architecture proposed by Hinton [2021] is a recurrent neural network for parsing an image into a hierarchy of wholes and parts. When a part is ambiguous, GLOM assumes that the ambiguity can be resolved by allowing the part to make multi-modal predictions for the pose and identity of the whole to which it belongs and then using attention to similar predictions coming from other possibly ambiguous parts to settle on a common mode that is predicted by several different parts. In this study, we describe a highly simplified version of GLOM that allows us to assess the effectiveness of this way of dealing with ambiguity. Our results show that, with supervised training, GLOM is able to successfully form islands of very similar embedding vectors for all of the locations occupied by the same object and it is also robust to strong noise injections in the input and to out-of-distribution input transformations.
Robust and Efficient Medical Imaging with Self-Supervision
May 19, 2022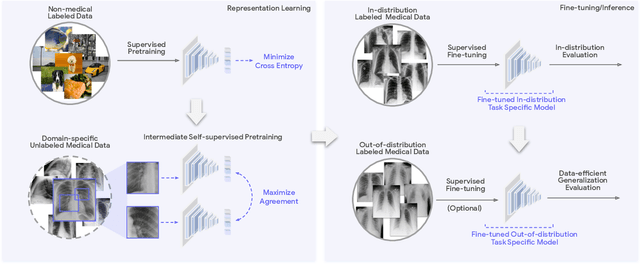
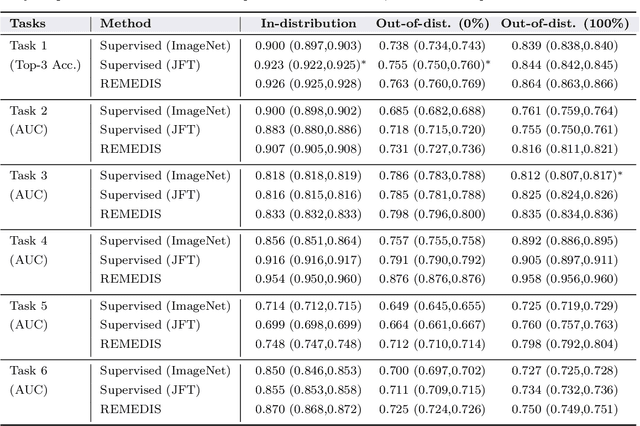
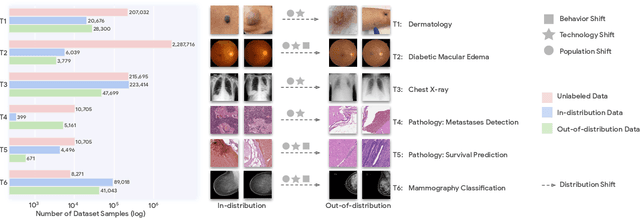

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.