 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting GLOM's ability to infer wholes from ambiguous parts
Nov 29, 2022



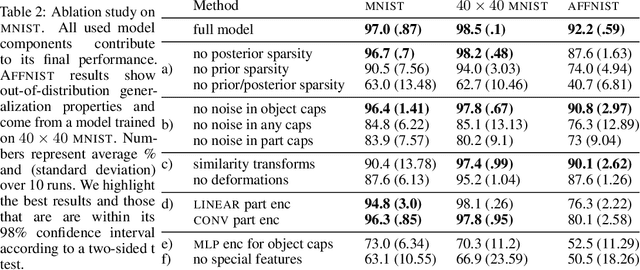
The GLOM architecture proposed by Hinton [2021] is a recurrent neural network for parsing an image into a hierarchy of wholes and parts. When a part is ambiguous, GLOM assumes that the ambiguity can be resolved by allowing the part to make multi-modal predictions for the pose and identity of the whole to which it belongs and then using attention to similar predictions coming from other possibly ambiguous parts to settle on a common mode that is predicted by several different parts. In this study, we describe a highly simplified version of GLOM that allows us to assess the effectiveness of this way of dealing with ambiguity. Our results show that, with supervised training, GLOM is able to successfully form islands of very similar embedding vectors for all of the locations occupied by the same object and it is also robust to strong noise injections in the input and to out-of-distribution input transformations.
Unsupervised part representation by Flow Capsules
Nov 27, 2020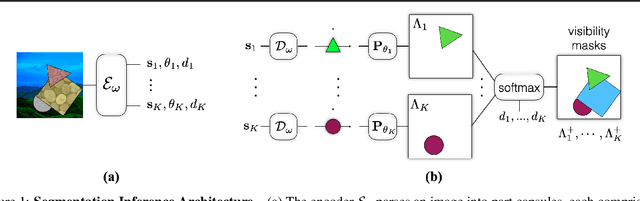
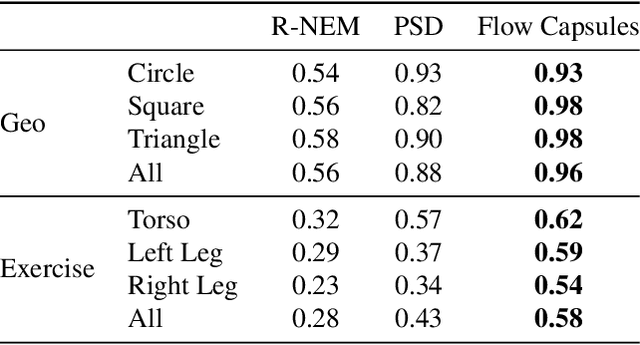
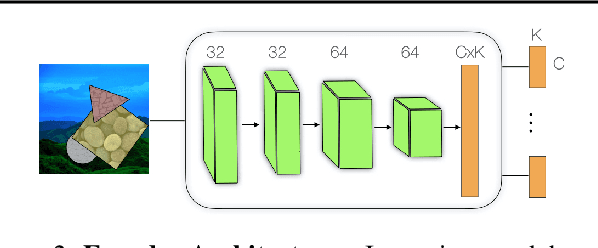

Capsule networks are designed to parse an image into a hierarchy of objects, parts and relations. While promising, they remain limited by an inability to learn effective low level part descriptions. To address this issue we propose a novel self-supervised method for learning part descriptors of an image. During training, we exploit motion as a powerful perceptual cue for part definition, using an expressive decoder for part generation and layered image formation with occlusion. Experiments demonstrate robust part discovery in the presence of multiple objects, cluttered backgrounds, and significant occlusion. The resulting part descriptors, a.k.a. part capsules, are decoded into shape masks, filling in occluded pixels, along with relative depth on single images. We also report unsupervised object classification using our capsule parts in a stacked capsule autoencoder.
Neural Additive Models: Interpretable Machine Learning with Neural Nets
Apr 29, 2020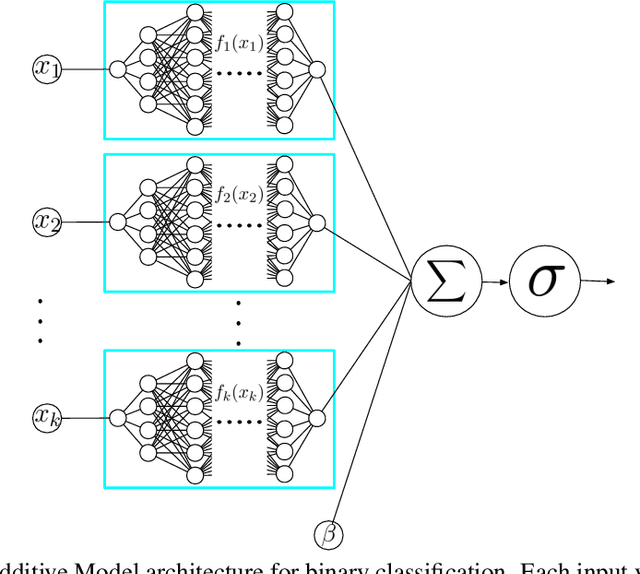
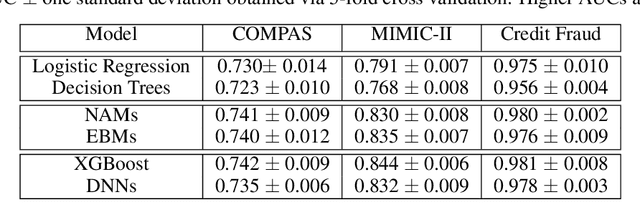
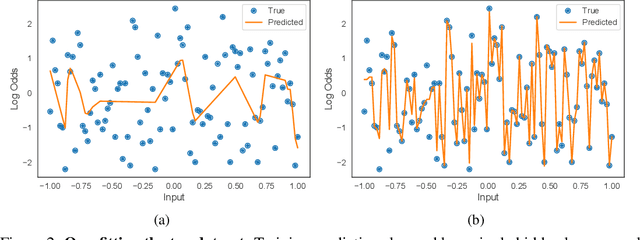
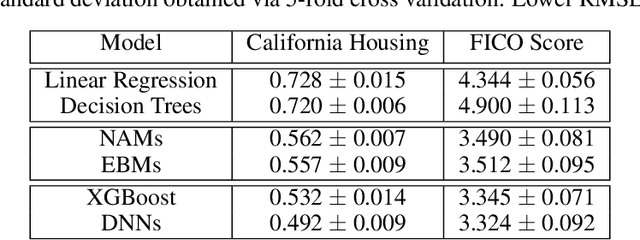
Deep neural networks (DNNs) are powerful black-box predictors that have achieved impressive performance on a wide variety of tasks. However, their accuracy comes at the cost of intelligibility: it is usually unclear how they make their decisions. This hinders their applicability to high stakes decision-making domains such as healthcare. We propose Neural Additive Models (NAMs) which combine some of the expressivity of DNNs with the inherent intelligibility of generalized additive models. NAMs learn a linear combination of neural networks that each attend to a single input feature. These networks are trained jointly and can learn arbitrarily complex relationships between their input feature and the output. Our experiments on regression and classification datasets show that NAMs are more accurate than widely used intelligible models such as logistic regression and shallow decision trees. They perform similarly to existing state-of-the-art generalized additive models in accuracy, but can be more easily applied to real-world problems.
Stacked Capsule Autoencoders
Jun 17, 2019
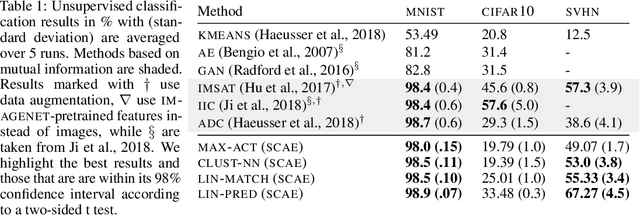

An object can be seen as a geometrically organized set of interrelated parts. A system that makes explicit use of these geometric relationships to recognize objects should be naturally robust to changes in viewpoint, because the intrinsic geometric relationships are viewpoint-invariant. We describe an unsupervised version of capsule networks, in which a neural encoder, which looks at all of the parts, is used to infer the presence and poses of object capsules. The encoder is trained by backpropagating through a decoder, which predicts the pose of each already discovered part using a mixture of pose predictions. The parts are discovered directly from an image, in a similar manner, by using a neural encoder, which infers parts and their affine transformations. The corresponding decoder models each image pixel as a mixture of predictions made by affine-transformed parts. We learn object- and their part-capsules on unlabeled data, and then cluster the vectors of presences of object capsules. When told the names of these clusters, we achieve state-of-the-art results for unsupervised classification on SVHN (55%) and near state-of-the-art on MNIST (98.5%).
Learning Sparse Networks Using Targeted Dropout
Jun 05, 2019
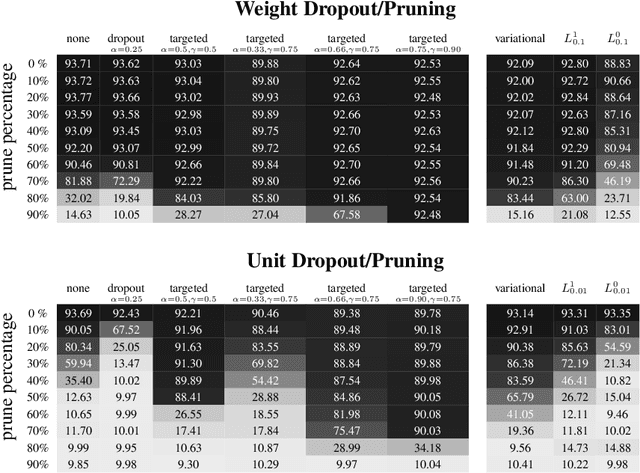
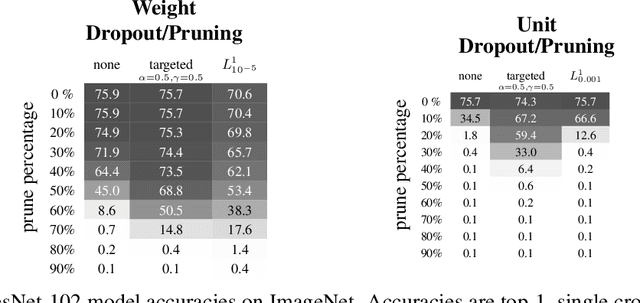
Neural networks are easier to optimise when they have many more weights than are required for modelling the mapping from inputs to outputs. This suggests a two-stage learning procedure that first learns a large net and then prunes away connections or hidden units. But standard training does not necessarily encourage nets to be amenable to pruning. We introduce targeted dropout, a method for training a neural network so that it is robust to subsequent pruning. Before computing the gradients for each weight update, targeted dropout stochastically selects a set of units or weights to be dropped using a simple self-reinforcing sparsity criterion and then computes the gradients for the remaining weights. The resulting network is robust to post hoc pruning of weights or units that frequently occur in the dropped sets. The method improves upon more complicated sparsifying regularisers while being simple to implement and easy to tune.
Assessing the Scalability of Biologically-Motivated Deep Learning Algorithms and Architectures
Jul 12, 2018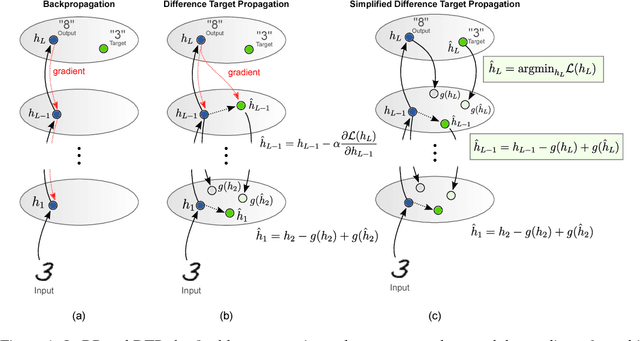
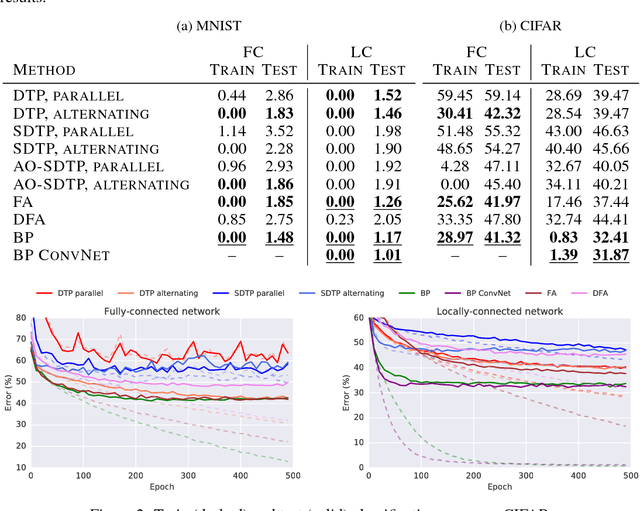
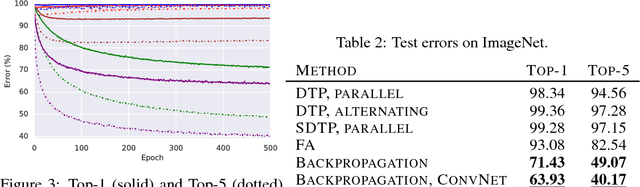

The backpropagation of error algorithm (BP) is often said to be impossible to implement in a real brain. The recent success of deep networks in machine learning and AI, however, has inspired proposals for understanding how the brain might learn across multiple layers, and hence how it might implement or approximate BP. As of yet, none of these proposals have been rigorously evaluated on tasks where BP-guided deep learning has proved critical, or in architectures more structured than simple fully-connected networks. Here we present the first results on scaling up biologically motivated models of deep learning on datasets which need deep networks with appropriate architectures to achieve good performance. We present results on the MNIST, CIFAR-10, and ImageNet datasets and explore variants of target-propagation (TP) and feedback alignment (FA) algorithms, and explore performance in both fully- and locally-connected architectures. We also introduce weight-transport-free variants of difference target propagation (DTP) modified to remove backpropagation from the penultimate layer. Many of these algorithms perform well for MNIST, but for CIFAR and ImageNet we find that TP and FA variants perform significantly worse than BP, especially for networks composed of locally connected units, opening questions about whether new architectures and algorithms are required to scale these approaches. Our results and implementation details help establish baselines for biologically motivated deep learning schemes going forward.
Large scale distributed neural network training through online distillation
Apr 09, 2018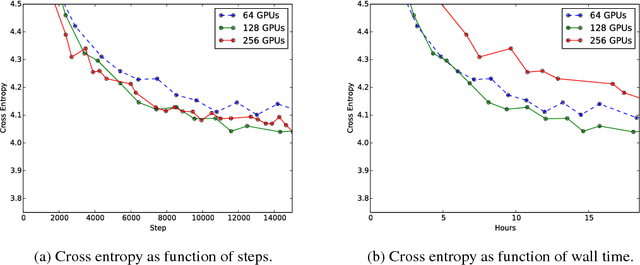

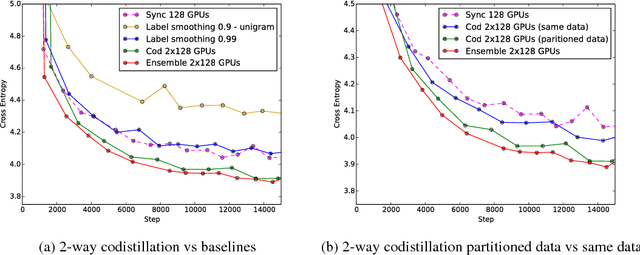
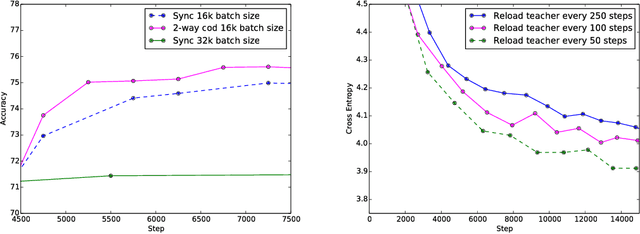
Techniques such as ensembling and distillation promise model quality improvements when paired with almost any base model. However, due to increased test-time cost (for ensembles) and increased complexity of the training pipeline (for distillation), these techniques are challenging to use in industrial settings. In this paper we explore a variant of distillation which is relatively straightforward to use as it does not require a complicated multi-stage setup or many new hyperparameters. Our first claim is that online distillation enables us to use extra parallelism to fit very large datasets about twice as fast. Crucially, we can still speed up training even after we have already reached the point at which additional parallelism provides no benefit for synchronous or asynchronous stochastic gradient descent. Two neural networks trained on disjoint subsets of the data can share knowledge by encouraging each model to agree with the predictions the other model would have made. These predictions can come from a stale version of the other model so they can be safely computed using weights that only rarely get transmitted. Our second claim is that online distillation is a cost-effective way to make the exact predictions of a model dramatically more reproducible. We support our claims using experiments on the Criteo Display Ad Challenge dataset, ImageNet, and the largest to-date dataset used for neural language modeling, containing $6\times 10^{11}$ tokens and based on the Common Crawl repository of web data.
Who Said What: Modeling Individual Labelers Improves Classification
Jan 04, 2018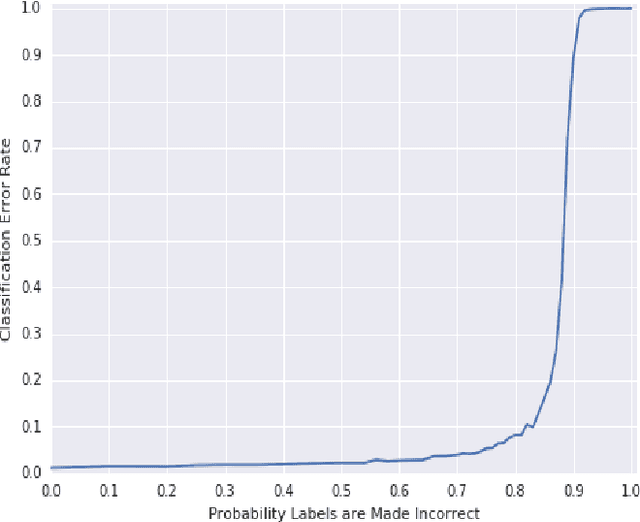
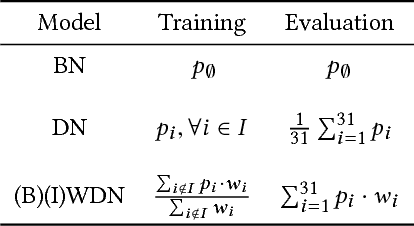
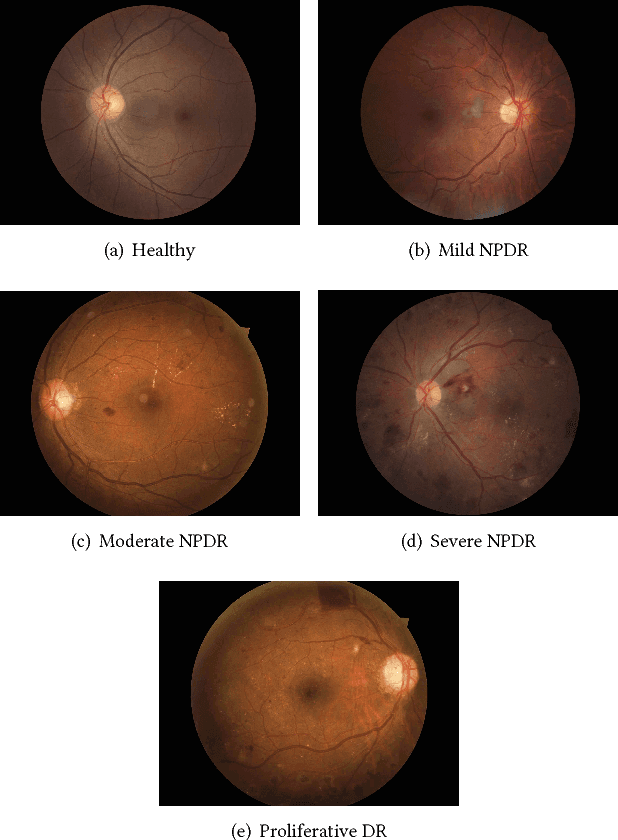
Data are often labeled by many different experts with each expert only labeling a small fraction of the data and each data point being labeled by several experts. This reduces the workload on individual experts and also gives a better estimate of the unobserved ground truth. When experts disagree, the standard approaches are to treat the majority opinion as the correct label or to model the correct label as a distribution. These approaches, however, do not make any use of potentially valuable information about which expert produced which label. To make use of this extra information, we propose modeling the experts individually and then learning averaging weights for combining them, possibly in sample-specific ways. This allows us to give more weight to more reliable experts and take advantage of the unique strengths of individual experts at classifying certain types of data. Here we show that our approach leads to improvements in computer-aided diagnosis of diabetic retinopathy. We also show that our method performs better than competing algorithms by Welinder and Perona (2010), and by Mnih and Hinton (2012). Our work offers an innovative approach for dealing with the myriad real-world settings that use expert opinions to define labels for training.
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models
Aug 12, 2016


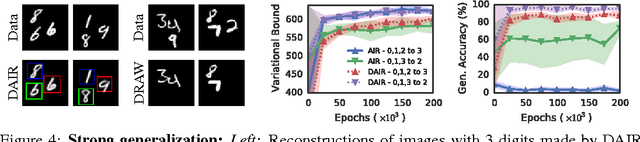
We present a framework for efficient inference in structured image models that explicitly reason about objects. We achieve this by performing probabilistic inference using a recurrent neural network that attends to scene elements and processes them one at a time. Crucially, the model itself learns to choose the appropriate number of inference steps. We use this scheme to learn to perform inference in partially specified 2D models (variable-sized variational auto-encoders) and fully specified 3D models (probabilistic renderers). We show that such models learn to identify multiple objects - counting, locating and classifying the elements of a scene - without any supervision, e.g., decomposing 3D images with various numbers of objects in a single forward pass of a neural network. We further show that the networks produce accurate inferences when compared to supervised counterparts, and that their structure leads to improved generalization.
Layer Normalization
Jul 21, 2016
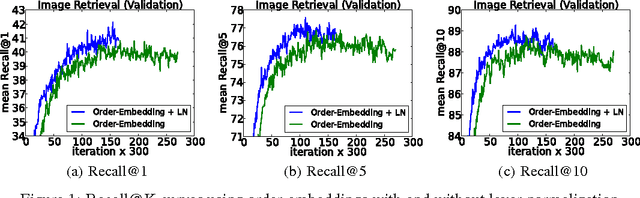
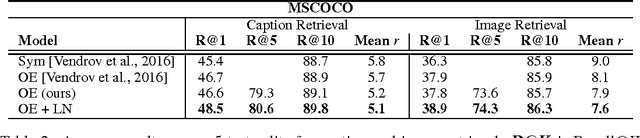

Training state-of-the-art, deep neural networks is computationally expensive. One way to reduce the training time is to normalize the activities of the neurons. A recently introduced technique called batch normalization uses the distribution of the summed input to a neuron over a mini-batch of training cases to compute a mean and variance which are then used to normalize the summed input to that neuron on each training case. This significantly reduces the training time in feed-forward neural networks. However, the effect of batch normalization is dependent on the mini-batch size and it is not obvious how to apply it to recurrent neural networks. In this paper, we transpose batch normalization into layer normalization by computing the mean and variance used for normalization from all of the summed inputs to the neurons in a layer on a single training case. Like batch normalization, we also give each neuron its own adaptive bias and gain which are applied after the normalization but before the non-linearity. Unlike batch normalization, layer normalization performs exactly the same computation at training and test times. It is also straightforward to apply to recurrent neural networks by computing the normalization statistics separately at each time step. Layer normalization is very effective at stabilizing the hidden state dynamics in recurrent networks. Empirically, we show that layer normalization can substantially reduce the training time compared with previously published techniques.