 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Normalization
Jul 21, 2016
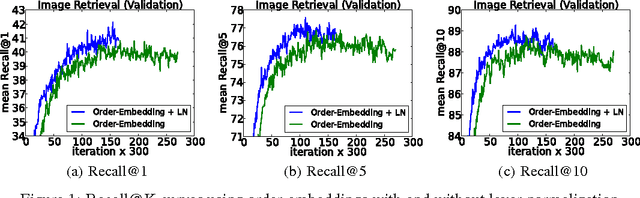

Training state-of-the-art, deep neural networks is computationally expensive. One way to reduce the training time is to normalize the activities of the neurons. A recently introduced technique called batch normalization uses the distribution of the summed input to a neuron over a mini-batch of training cases to compute a mean and variance which are then used to normalize the summed input to that neuron on each training case. This significantly reduces the training time in feed-forward neural networks. However, the effect of batch normalization is dependent on the mini-batch size and it is not obvious how to apply it to recurrent neural networks. In this paper, we transpose batch normalization into layer normalization by computing the mean and variance used for normalization from all of the summed inputs to the neurons in a layer on a single training case. Like batch normalization, we also give each neuron its own adaptive bias and gain which are applied after the normalization but before the non-linearity. Unlike batch normalization, layer normalization performs exactly the same computation at training and test times. It is also straightforward to apply to recurrent neural networks by computing the normalization statistics separately at each time step. Layer normalization is very effective at stabilizing the hidden state dynamics in recurrent networks. Empirically, we show that layer normalization can substantially reduce the training time compared with previously published techniques.
Generating Images from Captions with Attention
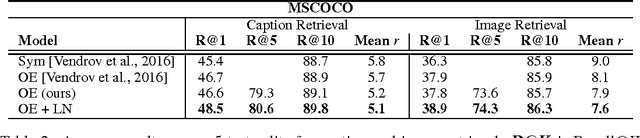
Feb 29, 2016Motivated by the recent progress in generative models, we introduce a model that generates images from natural language descriptions. The proposed model iteratively draws patches on a canvas, while attending to the relevant words in the description. After training on Microsoft COCO, we compare our model with several baseline generative models on image generation and retrieval tasks. We demonstrate that our model produces higher quality samples than other approaches and generates images with novel scene compositions corresponding to previously unseen captions in the dataset.
Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
Feb 22, 2016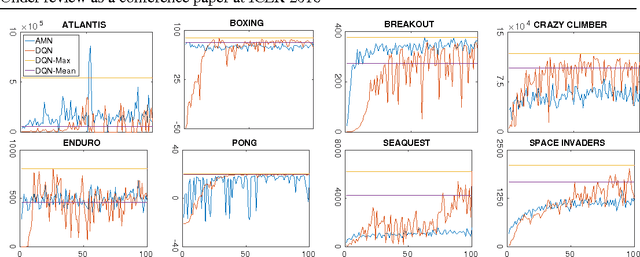

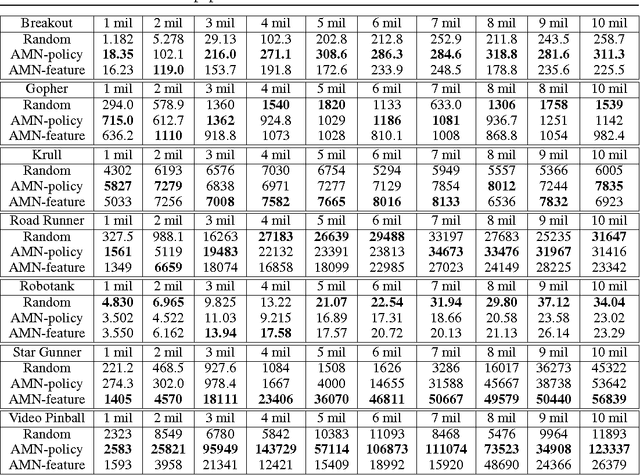
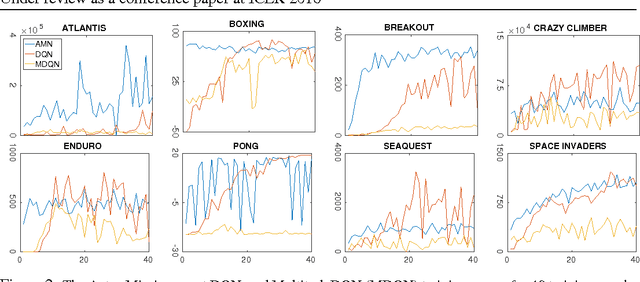
The ability to act in multiple environments and transfer previous knowledge to new situations can be considered a critical aspect of any intelligent agent. Towards this goal, we define a novel method of multitask and transfer learning that enables an autonomous agent to learn how to behave in multiple tasks simultaneously, and then generalize its knowledge to new domains. This method, termed "Actor-Mimic", exploits the use of deep reinforcement learning and model compression techniques to train a single policy network that learns how to act in a set of distinct tasks by using the guidance of several expert teachers. We then show that the representations learnt by the deep policy network are capable of generalizing to new tasks with no prior expert guidance, speeding up learning in novel environments. Although our method can in general be applied to a wide range of problems, we use Atari games as a testing environment to demonstrate these methods.