 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised part representation by Flow Capsules
Paper and Code
Nov 27, 2020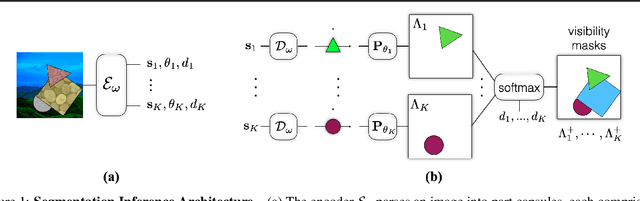
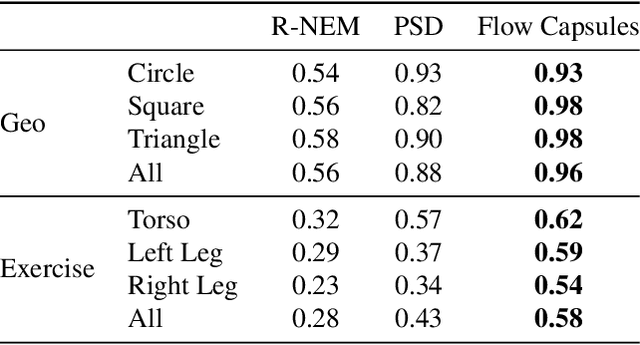
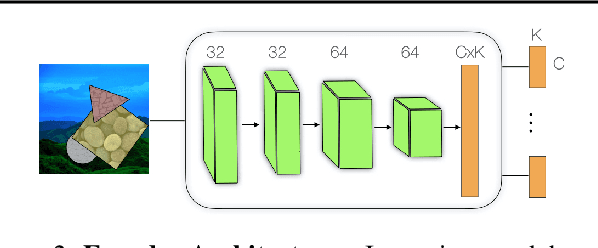

Capsule networks are designed to parse an image into a hierarchy of objects, parts and relations. While promising, they remain limited by an inability to learn effective low level part descriptions. To address this issue we propose a novel self-supervised method for learning part descriptors of an image. During training, we exploit motion as a powerful perceptual cue for part definition, using an expressive decoder for part generation and layered image formation with occlusion. Experiments demonstrate robust part discovery in the presence of multiple objects, cluttered backgrounds, and significant occlusion. The resulting part descriptors, a.k.a. part capsules, are decoded into shape masks, filling in occluded pixels, along with relative depth on single images. We also report unsupervised object classification using our capsule parts in a stacked capsule autoencoder.