 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Learning and Robust 3D Reconstruction
Apr 22, 2025In this thesis we discuss architectural designs and training methods for a neural network to have the ability of dissecting an image into objects of interest without supervision. The main challenge in 2D unsupervised object segmentation is distinguishing between foreground objects of interest and background. FlowCapsules uses motion as a cue for the objects of interest in 2D scenarios. The last part of this thesis focuses on 3D applications where the goal is detecting and removal of the object of interest from the input images. In these tasks, we leverage the geometric consistency of scenes in 3D to detect the inconsistent dynamic objects. Our transient object masks are then used for designing robust optimization kernels to improve 3D modelling in a casual capture setup. One of our goals in this thesis is to show the merits of unsupervised object based approaches in computer vision. Furthermore, we suggest possible directions for defining objects of interest or foreground objects without requiring supervision. Our hope is to motivate and excite the community into further exploring explicit object representations in image understanding tasks.
RoMo: Robust Motion Segmentation Improves Structure from Motion
Nov 27, 2024
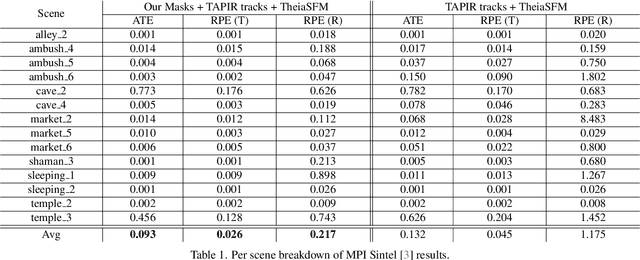


There has been extensive progress in the reconstruction and generation of 4D scenes from monocular casually-captured video. While these tasks rely heavily on known camera poses, the problem of finding such poses using structure-from-motion (SfM) often depends on robustly separating static from dynamic parts of a video. The lack of a robust solution to this problem limits the performance of SfM camera-calibration pipelines. We propose a novel approach to video-based motion segmentation to identify the components of a scene that are moving w.r.t. a fixed world frame. Our simple but effective iterative method, RoMo, combines optical flow and epipolar cues with a pre-trained video segmentation model. It outperforms unsupervised baselines for motion segmentation as well as supervised baselines trained from synthetic data. More importantly, the combination of an off-the-shelf SfM pipeline with our segmentation masks establishes a new state-of-the-art on camera calibration for scenes with dynamic content, outperforming existing methods by a substantial margin.
SpotlessSplats: Ignoring Distractors in 3D Gaussian Splatting
Jun 28, 2024
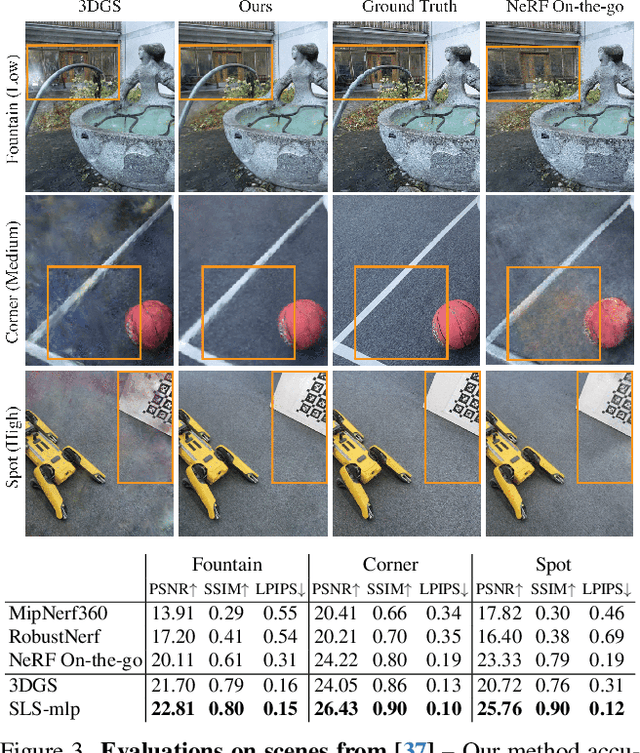

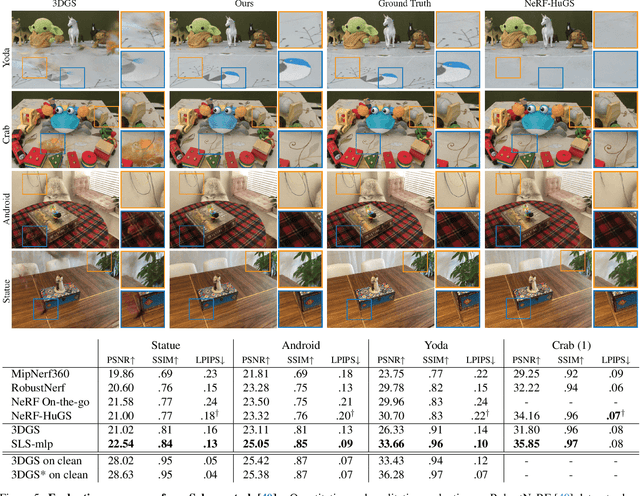
3D Gaussian Splatting (3DGS) is a promising technique for 3D reconstruction, offering efficient training and rendering speeds, making it suitable for real-time applications.However, current methods require highly controlled environments (no moving people or wind-blown elements, and consistent lighting) to meet the inter-view consistency assumption of 3DGS. This makes reconstruction of real-world captures problematic. We present SpotlessSplats, an approach that leverages pre-trained and general-purpose features coupled with robust optimization to effectively ignore transient distractors. Our method achieves state-of-the-art reconstruction quality both visually and quantitatively, on casual captures.
RobustNeRF: Ignoring Distractors with Robust Losses
Feb 02, 2023Neural radiance fields (NeRF) excel at synthesizing new views given multi-view, calibrated images of a static scene. When scenes include distractors, which are not persistent during image capture (moving objects, lighting variations, shadows), artifacts appear as view-dependent effects or 'floaters'. To cope with distractors, we advocate a form of robust estimation for NeRF training, modeling distractors in training data as outliers of an optimization problem. Our method successfully removes outliers from a scene and improves upon our baselines, on synthetic and real-world scenes. Our technique is simple to incorporate in modern NeRF frameworks, with few hyper-parameters. It does not assume a priori knowledge of the types of distractors, and is instead focused on the optimization problem rather than pre-processing or modeling transient objects. More results on our page https://robustnerf.github.io/public.
Testing GLOM's ability to infer wholes from ambiguous parts
Nov 29, 2022



The GLOM architecture proposed by Hinton [2021] is a recurrent neural network for parsing an image into a hierarchy of wholes and parts. When a part is ambiguous, GLOM assumes that the ambiguity can be resolved by allowing the part to make multi-modal predictions for the pose and identity of the whole to which it belongs and then using attention to similar predictions coming from other possibly ambiguous parts to settle on a common mode that is predicted by several different parts. In this study, we describe a highly simplified version of GLOM that allows us to assess the effectiveness of this way of dealing with ambiguity. Our results show that, with supervised training, GLOM is able to successfully form islands of very similar embedding vectors for all of the locations occupied by the same object and it is also robust to strong noise injections in the input and to out-of-distribution input transformations.
nerf2nerf: Pairwise Registration of Neural Radiance Fields
Nov 03, 2022



We introduce a technique for pairwise registration of neural fields that extends classical optimization-based local registration (i.e. ICP) to operate on Neural Radiance Fields (NeRF) -- neural 3D scene representations trained from collections of calibrated images. NeRF does not decompose illumination and color, so to make registration invariant to illumination, we introduce the concept of a ''surface field'' -- a field distilled from a pre-trained NeRF model that measures the likelihood of a point being on the surface of an object. We then cast nerf2nerf registration as a robust optimization that iteratively seeks a rigid transformation that aligns the surface fields of the two scenes. We evaluate the effectiveness of our technique by introducing a dataset of pre-trained NeRF scenes -- our synthetic scenes enable quantitative evaluations and comparisons to classical registration techniques, while our real scenes demonstrate the validity of our technique in real-world scenarios. Additional results available at: https://nerf2nerf.github.io
Kubric: A scalable dataset generator
Mar 07, 2022

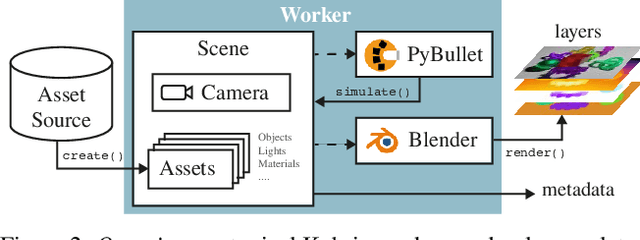
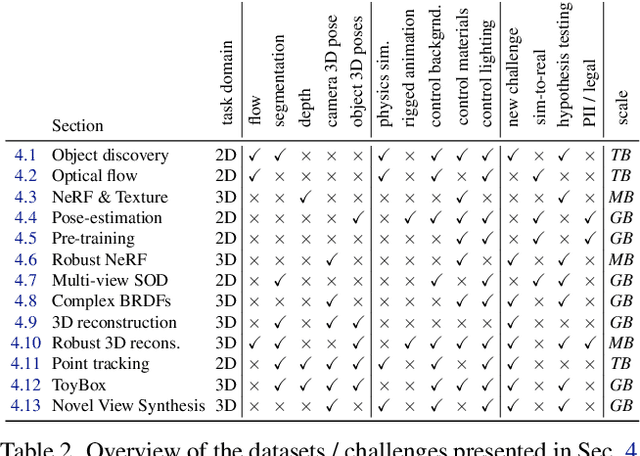
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Conditional Object-Centric Learning from Video
Nov 24, 2021

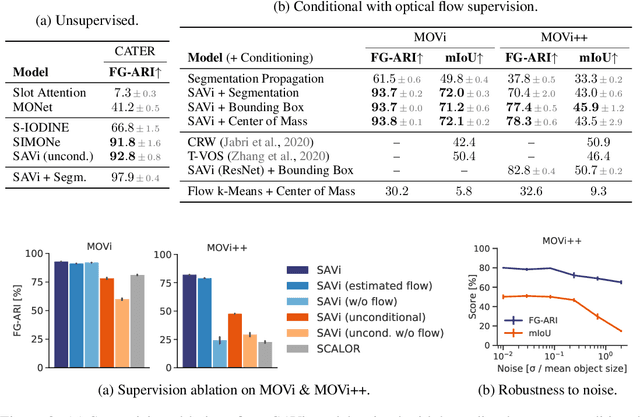

Object-centric representations are a promising path toward more systematic generalization by providing flexible abstractions upon which compositional world models can be built. Recent work on simple 2D and 3D datasets has shown that models with object-centric inductive biases can learn to segment and represent meaningful objects from the statistical structure of the data alone without the need for any supervision. However, such fully-unsupervised methods still fail to scale to diverse realistic data, despite the use of increasingly complex inductive biases such as priors for the size of objects or the 3D geometry of the scene. In this paper, we instead take a weakly-supervised approach and focus on how 1) using the temporal dynamics of video data in the form of optical flow and 2) conditioning the model on simple object location cues can be used to enable segmenting and tracking objects in significantly more realistic synthetic data. We introduce a sequential extension to Slot Attention which we train to predict optical flow for realistic looking synthetic scenes and show that conditioning the initial state of this model on a small set of hints, such as center of mass of objects in the first frame, is sufficient to significantly improve instance segmentation. These benefits generalize beyond the training distribution to novel objects, novel backgrounds, and to longer video sequences. We also find that such initial-state-conditioning can be used during inference as a flexible interface to query the model for specific objects or parts of objects, which could pave the way for a range of weakly-supervised approaches and allow more effective interaction with trained models.
Canonical Capsules: Unsupervised Capsules in Canonical Pose
Dec 08, 2020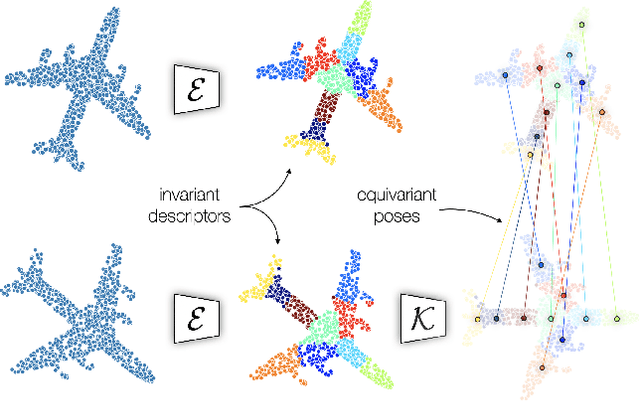
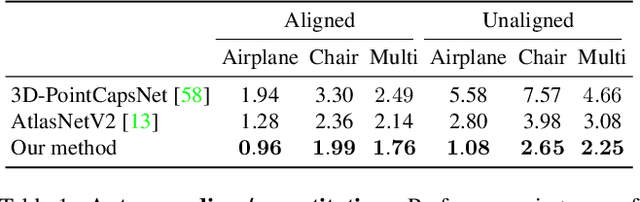

We propose an unsupervised capsule architecture for 3D point clouds. We compute capsule decompositions of objects through permutation-equivariant attention, and self-supervise the process by training with pairs of randomly rotated objects. Our key idea is to aggregate the attention masks into semantic keypoints, and use these to supervise a decomposition that satisfies the capsule invariance/equivariance properties. This not only enables the training of a semantically consistent decomposition, but also allows us to learn a canonicalization operation that enables object-centric reasoning. In doing so, we require neither classification labels nor manually-aligned training datasets to train. Yet, by learning an object-centric representation in an unsupervised manner, our method outperforms the state-of-the-art on 3D point cloud reconstruction, registration, and unsupervised classification. We will release the code and dataset to reproduce our results as soon as the paper is published.
Unsupervised part representation by Flow Capsules
Nov 27, 2020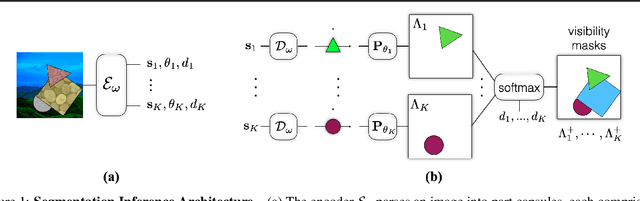
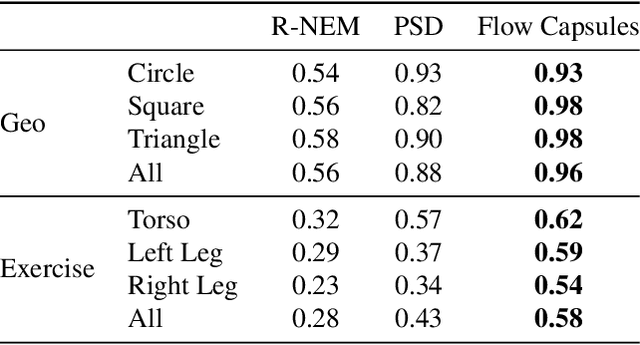
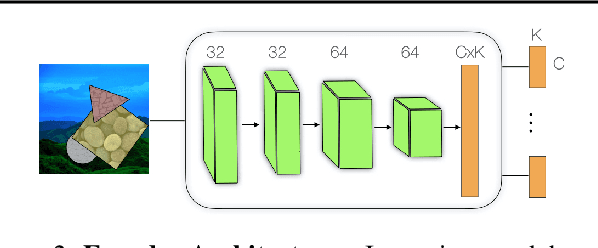

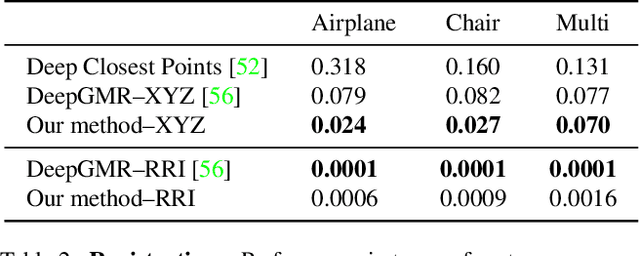
Capsule networks are designed to parse an image into a hierarchy of objects, parts and relations. While promising, they remain limited by an inability to learn effective low level part descriptions. To address this issue we propose a novel self-supervised method for learning part descriptors of an image. During training, we exploit motion as a powerful perceptual cue for part definition, using an expressive decoder for part generation and layered image formation with occlusion. Experiments demonstrate robust part discovery in the presence of multiple objects, cluttered backgrounds, and significant occlusion. The resulting part descriptors, a.k.a. part capsules, are decoded into shape masks, filling in occluded pixels, along with relative depth on single images. We also report unsupervised object classification using our capsule parts in a stacked capsule autoencoder.