 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustNeRF: Ignoring Distractors with Robust Losses
Feb 02, 2023Neural radiance fields (NeRF) excel at synthesizing new views given multi-view, calibrated images of a static scene. When scenes include distractors, which are not persistent during image capture (moving objects, lighting variations, shadows), artifacts appear as view-dependent effects or 'floaters'. To cope with distractors, we advocate a form of robust estimation for NeRF training, modeling distractors in training data as outliers of an optimization problem. Our method successfully removes outliers from a scene and improves upon our baselines, on synthetic and real-world scenes. Our technique is simple to incorporate in modern NeRF frameworks, with few hyper-parameters. It does not assume a priori knowledge of the types of distractors, and is instead focused on the optimization problem rather than pre-processing or modeling transient objects. More results on our page https://robustnerf.github.io/public.
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
Oct 27, 2020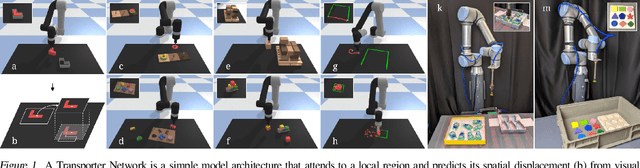
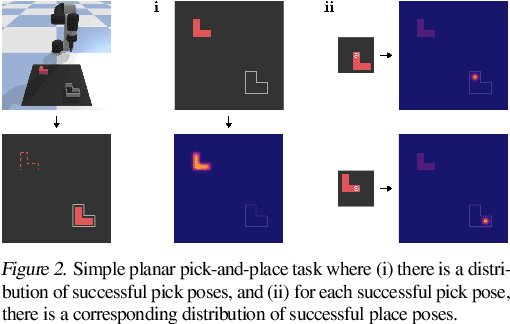
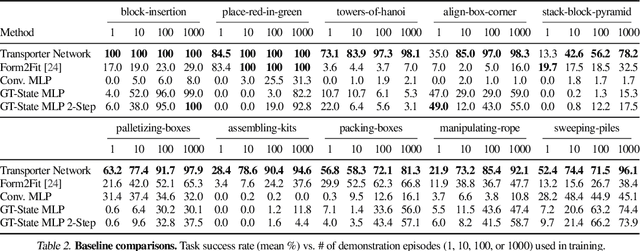
Robotic manipulation can be formulated as inducing a sequence of spatial displacements: where the space being moved can encompass an object, part of an object, or end effector. In this work, we propose the Transporter Network, a simple model architecture that rearranges deep features to infer spatial displacements from visual input - which can parameterize robot actions. It makes no assumptions of objectness (e.g. canonical poses, models, or keypoints), it exploits spatial symmetries, and is orders of magnitude more sample efficient than our benchmarked alternatives in learning vision-based manipulation tasks: from stacking a pyramid of blocks, to assembling kits with unseen objects; from manipulating deformable ropes, to pushing piles of small objects with closed-loop feedback. Our method can represent complex multi-modal policy distributions and generalizes to multi-step sequential tasks, as well as 6DoF pick-and-place. Experiments on 10 simulated tasks show that it learns faster and generalizes better than a variety of end-to-end baselines, including policies that use ground-truth object poses. We validate our methods with hardware in the real world. Experiment videos and code will be made available at https://transporternets.github.io
The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale
Nov 02, 2018


We present Open Images V4, a dataset of 9.2M images with unified annotations for image classification, object detection and visual relationship detection. The images have a Creative Commons Attribution license that allows to share and adapt the material, and they have been collected from Flickr without a predefined list of class names or tags, leading to natural class statistics and avoiding an initial design bias. Open Images V4 offers large scale across several dimensions: 30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes, and 375k visual relationship annotations involving 57 classes. For object detection in particular, we provide 15x more bounding boxes than the next largest datasets (15.4M boxes on 1.9M images). The images often show complex scenes with several objects (8 annotated objects per image on average). We annotated visual relationships between them, which support visual relationship detection, an emerging task that requires structured reasoning. We provide in-depth comprehensive statistics about the dataset, we validate the quality of the annotations, and we study how the performance of many modern models evolves with increasing amounts of training data. We hope that the scale, quality, and variety of Open Images V4 will foster further research and innovation even beyond the areas of image classification, object detection, and visual relationship detection.
Learning From Noisy Large-Scale Datasets With Minimal Supervision
Apr 10, 2017
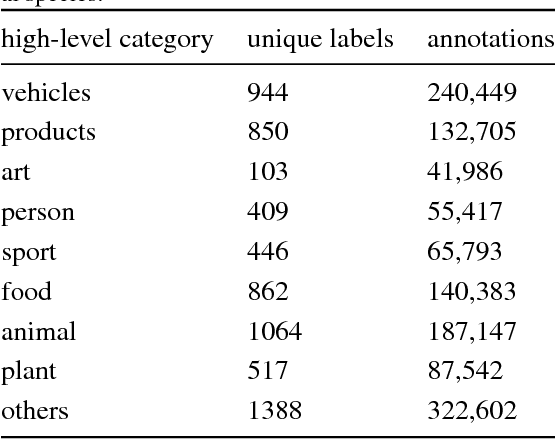


We present an approach to effectively use millions of images with noisy annotations in conjunction with a small subset of cleanly-annotated images to learn powerful image representations. One common approach to combine clean and noisy data is to first pre-train a network using the large noisy dataset and then fine-tune with the clean dataset. We show this approach does not fully leverage the information contained in the clean set. Thus, we demonstrate how to use the clean annotations to reduce the noise in the large dataset before fine-tuning the network using both the clean set and the full set with reduced noise. The approach comprises a multi-task network that jointly learns to clean noisy annotations and to accurately classify images. We evaluate our approach on the recently released Open Images dataset, containing ~9 million images, multiple annotations per image and over 6000 unique classes. For the small clean set of annotations we use a quarter of the validation set with ~40k images. Our results demonstrate that the proposed approach clearly outperforms direct fine-tuning across all major categories of classes in the Open Image dataset. Further, our approach is particularly effective for a large number of classes with wide range of noise in annotations (20-80% false positive annotations).