 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond SOT: It's Time to Track Multiple Generic Objects at Once
Dec 22, 2022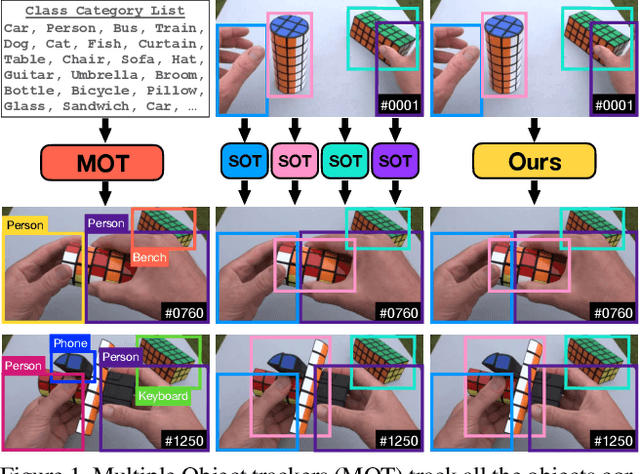



Generic Object Tracking (GOT) is the problem of tracking target objects, specified by bounding boxes in the first frame of a video. While the task has received much attention in the last decades, researchers have almost exclusively focused on the single object setting. Multi-object GOT benefits from a wider applicability, rendering it more attractive in real-world applications. We attribute the lack of research interest into this problem to the absence of suitable benchmarks. In this work, we introduce a new large-scale GOT benchmark, LaGOT, containing multiple annotated target objects per sequence. Our benchmark allows researchers to tackle key remaining challenges in GOT, aiming to increase robustness and reduce computation through joint tracking of multiple objects simultaneously. Furthermore, we propose a Transformer-based GOT tracker TaMOS capable of joint processing of multiple objects through shared computation. TaMOs achieves a 4x faster run-time in case of 10 concurrent objects compared to tracking each object independently and outperforms existing single object trackers on our new benchmark. Finally, TaMOs achieves highly competitive results on single-object GOT datasets, setting a new state-of-the-art on TrackingNet with a success rate AUC of 84.4%. Our benchmark, code, and trained models will be made publicly available.
Factors of Influence for Transfer Learning across Diverse Appearance Domains and Task Types
Mar 24, 2021
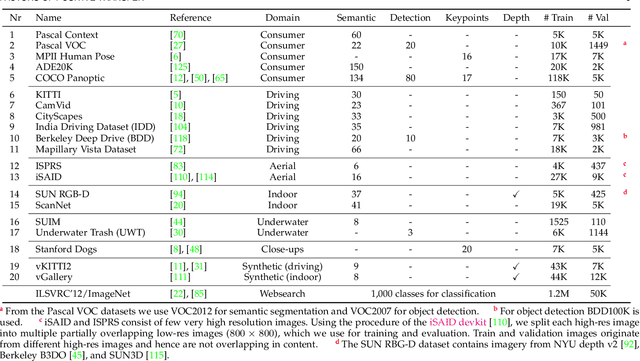


Transfer learning enables to re-use knowledge learned on a source task to help learning a target task. A simple form of transfer learning is common in current state-of-the-art computer vision models, i.e. pre-training a model for image classification on the ILSVRC dataset, and then fine-tune on any target task. However, previous systematic studies of transfer learning have been limited and the circumstances in which it is expected to work are not fully understood. In this paper we carry out an extensive experimental exploration of transfer learning across vastly different image domains (consumer photos, autonomous driving, aerial imagery, underwater, indoor scenes, synthetic, close-ups) and task types (semantic segmentation, object detection, depth estimation, keypoint detection). Importantly, these are all complex, structured output tasks types relevant to modern computer vision applications. In total we carry out over 1200 transfer experiments, including many where the source and target come from different image domains, task types, or both. We systematically analyze these experiments to understand the impact of image domain, task type, and dataset size on transfer learning performance. Our study leads to several insights and concrete recommendations for practitioners.
The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale
Nov 02, 2018


We present Open Images V4, a dataset of 9.2M images with unified annotations for image classification, object detection and visual relationship detection. The images have a Creative Commons Attribution license that allows to share and adapt the material, and they have been collected from Flickr without a predefined list of class names or tags, leading to natural class statistics and avoiding an initial design bias. Open Images V4 offers large scale across several dimensions: 30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes, and 375k visual relationship annotations involving 57 classes. For object detection in particular, we provide 15x more bounding boxes than the next largest datasets (15.4M boxes on 1.9M images). The images often show complex scenes with several objects (8 annotated objects per image on average). We annotated visual relationships between them, which support visual relationship detection, an emerging task that requires structured reasoning. We provide in-depth comprehensive statistics about the dataset, we validate the quality of the annotations, and we study how the performance of many modern models evolves with increasing amounts of training data. We hope that the scale, quality, and variety of Open Images V4 will foster further research and innovation even beyond the areas of image classification, object detection, and visual relationship detection.