 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond SOT: It's Time to Track Multiple Generic Objects at Once
Dec 22, 2022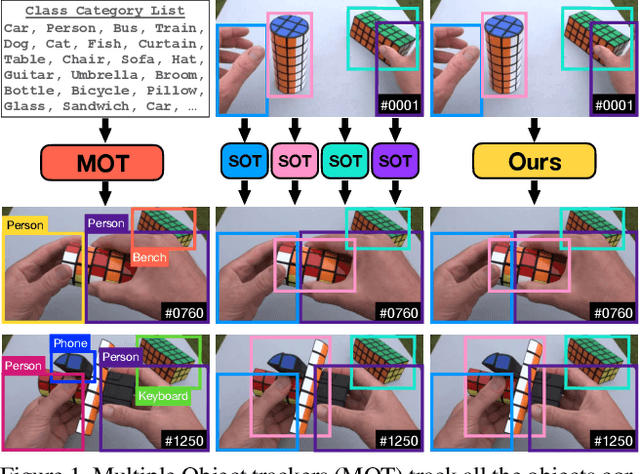



Generic Object Tracking (GOT) is the problem of tracking target objects, specified by bounding boxes in the first frame of a video. While the task has received much attention in the last decades, researchers have almost exclusively focused on the single object setting. Multi-object GOT benefits from a wider applicability, rendering it more attractive in real-world applications. We attribute the lack of research interest into this problem to the absence of suitable benchmarks. In this work, we introduce a new large-scale GOT benchmark, LaGOT, containing multiple annotated target objects per sequence. Our benchmark allows researchers to tackle key remaining challenges in GOT, aiming to increase robustness and reduce computation through joint tracking of multiple objects simultaneously. Furthermore, we propose a Transformer-based GOT tracker TaMOS capable of joint processing of multiple objects through shared computation. TaMOs achieves a 4x faster run-time in case of 10 concurrent objects compared to tracking each object independently and outperforms existing single object trackers on our new benchmark. Finally, TaMOs achieves highly competitive results on single-object GOT datasets, setting a new state-of-the-art on TrackingNet with a success rate AUC of 84.4%. Our benchmark, code, and trained models will be made publicly available.
AVisT: A Benchmark for Visual Object Tracking in Adverse Visibility
Aug 14, 2022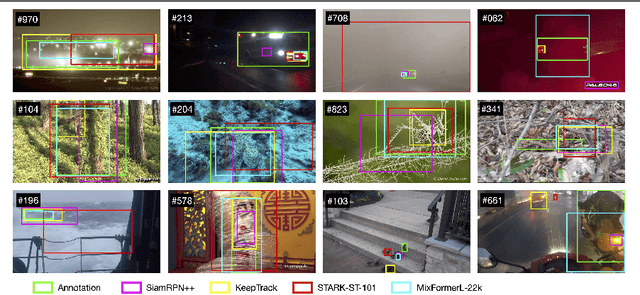


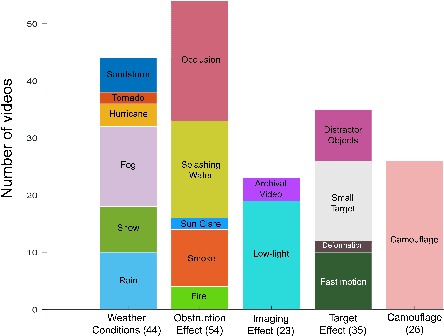
One of the key factors behind the recent success in visual tracking is the availability of dedicated benchmarks. While being greatly benefiting to the tracking research, existing benchmarks do not pose the same difficulty as before with recent trackers achieving higher performance mainly due to (i) the introduction of more sophisticated transformers-based methods and (ii) the lack of diverse scenarios with adverse visibility such as, severe weather conditions, camouflage and imaging effects. We introduce AVisT, a dedicated benchmark for visual tracking in diverse scenarios with adverse visibility. AVisT comprises 120 challenging sequences with 80k annotated frames, spanning 18 diverse scenarios broadly grouped into five attributes with 42 object categories. The key contribution of AVisT is diverse and challenging scenarios covering severe weather conditions such as, dense fog, heavy rain and sandstorm; obstruction effects including, fire, sun glare and splashing water; adverse imaging effects such as, low-light; target effects including, small targets and distractor objects along with camouflage. We further benchmark 17 popular and recent trackers on AVisT with detailed analysis of their tracking performance across attributes, demonstrating a big room for improvement in performance. We believe that AVisT can greatly benefit the tracking community by complementing the existing benchmarks, in developing new creative tracking solutions in order to continue pushing the boundaries of the state-of-the-art. Our dataset along with the complete tracking performance evaluation is available at: https://github.com/visionml/pytracking
Transforming Model Prediction for Tracking
Mar 21, 2022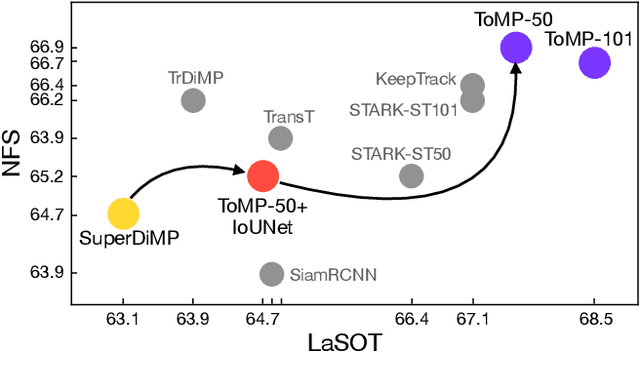
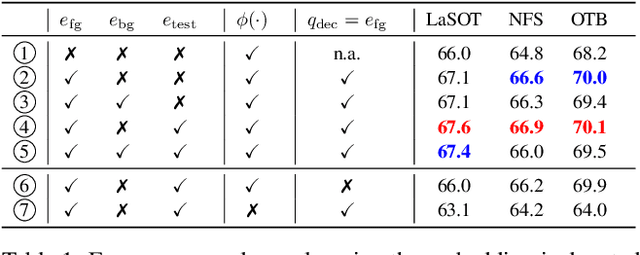
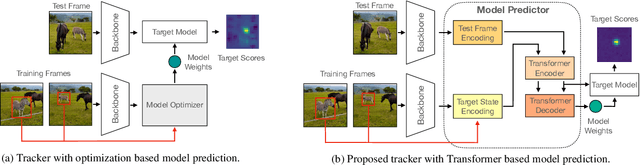

Optimization based tracking methods have been widely successful by integrating a target model prediction module, providing effective global reasoning by minimizing an objective function. While this inductive bias integrates valuable domain knowledge, it limits the expressivity of the tracking network. In this work, we therefore propose a tracker architecture employing a Transformer-based model prediction module. Transformers capture global relations with little inductive bias, allowing it to learn the prediction of more powerful target models. We further extend the model predictor to estimate a second set of weights that are applied for accurate bounding box regression. The resulting tracker relies on training and on test frame information in order to predict all weights transductively. We train the proposed tracker end-to-end and validate its performance by conducting comprehensive experiments on multiple tracking datasets. Our tracker sets a new state of the art on three benchmarks, achieving an AUC of 68.5% on the challenging LaSOT dataset.
Robust Visual Tracking by Segmentation
Mar 21, 2022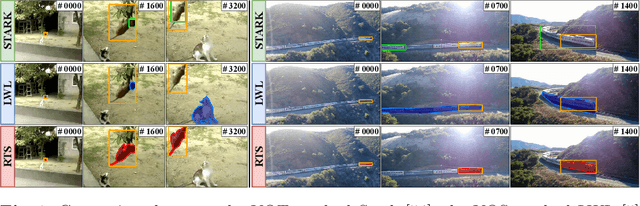

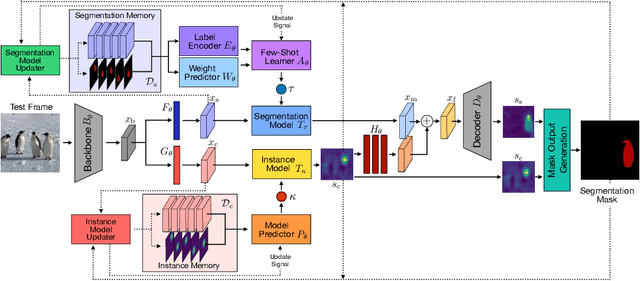
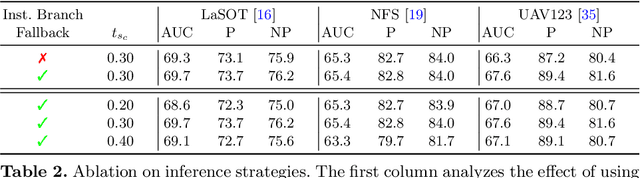
Estimating the target extent poses a fundamental challenge in visual object tracking. Typically, trackers are box-centric and fully rely on a bounding box to define the target in the scene. In practice, objects often have complex shapes and are not aligned with the image axis. In these cases, bounding boxes do not provide an accurate description of the target and often contain a majority of background pixels. We propose a segmentation-centric tracking pipeline that not only produces a highly accurate segmentation mask, but also works internally with segmentation masks instead of bounding boxes. Thus, our tracker is able to better learn a target representation that clearly differentiates the target in the scene from background content. In order to achieve the necessary robustness for the challenging tracking scenario, we propose a separate instance localization component that is used to condition the segmentation decoder when producing the output mask. We infer a bounding box from the segmentation mask and validate our tracker on challenging tracking datasets and achieve the new state of the art on LaSOT with a success AUC score of 69.7%. Since fully evaluating the predicted masks on tracking datasets is not possible due to the missing mask annotations, we further validate our segmentation quality on two popular video object segmentation datasets.
Learning Target Candidate Association to Keep Track of What Not to Track
Mar 30, 2021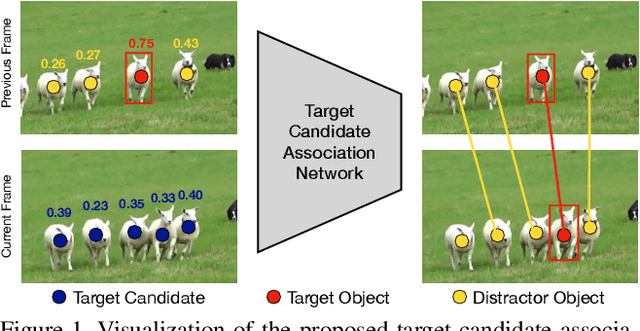

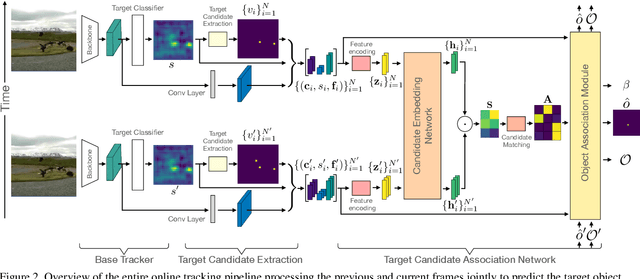

The presence of objects that are confusingly similar to the tracked target, poses a fundamental challenge in appearance-based visual tracking. Such distractor objects are easily misclassified as the target itself, leading to eventual tracking failure. While most methods strive to suppress distractors through more powerful appearance models, we take an alternative approach. We propose to keep track of distractor objects in order to continue tracking the target. To this end, we introduce a learned association network, allowing us to propagate the identities of all target candidates from frame-to-frame. To tackle the problem of lacking ground-truth correspondences between distractor objects in visual tracking, we propose a training strategy that combines partial annotations with self-supervision. We conduct comprehensive experimental validation and analysis of our approach on several challenging datasets. Our tracker sets a new state-of-the-art on six benchmarks, achieving an AUC score of 67.2% on LaSOT and a +6.1% absolute gain on the OxUvA long-term dataset.
Group Sparsity: The Hinge Between Filter Pruning and Decomposition for Network Compression
Mar 19, 2020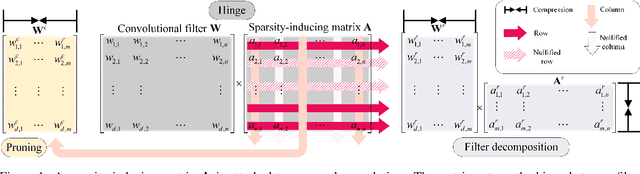
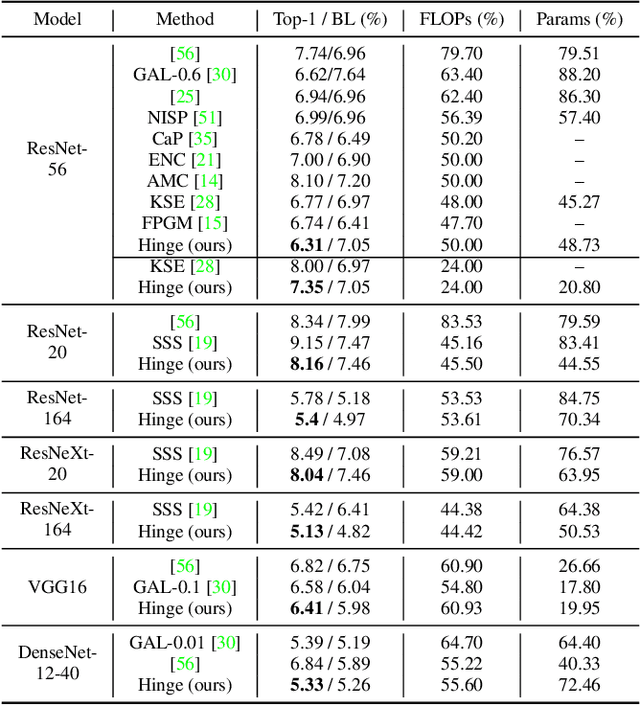
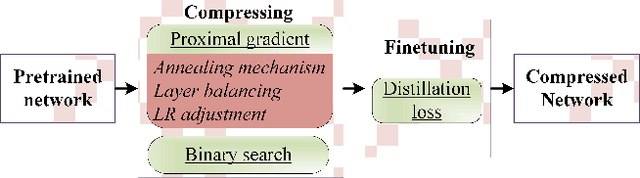
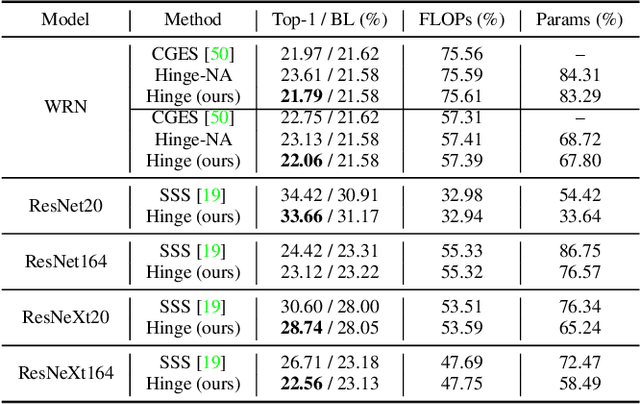
In this paper, we analyze two popular network compression techniques, i.e. filter pruning and low-rank decomposition, in a unified sense. By simply changing the way the sparsity regularization is enforced, filter pruning and low-rank decomposition can be derived accordingly. This provides another flexible choice for network compression because the techniques complement each other. For example, in popular network architectures with shortcut connections (e.g. ResNet), filter pruning cannot deal with the last convolutional layer in a ResBlock while the low-rank decomposition methods can. In addition, we propose to compress the whole network jointly instead of in a layer-wise manner. Our approach proves its potential as it compares favorably to the state-of-the-art on several benchmarks.
Efficient Video Semantic Segmentation with Labels Propagation and Refinement
Dec 26, 2019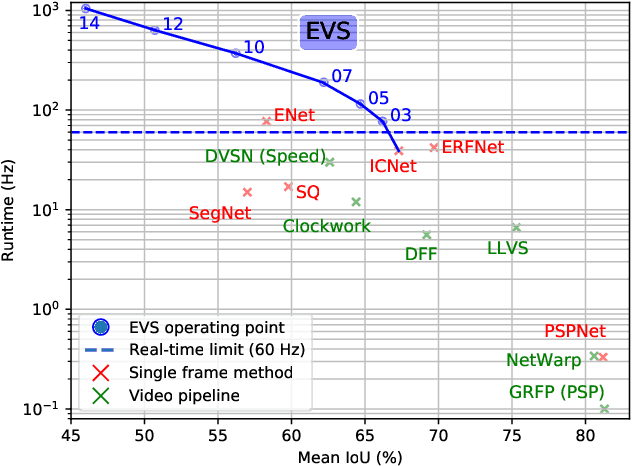

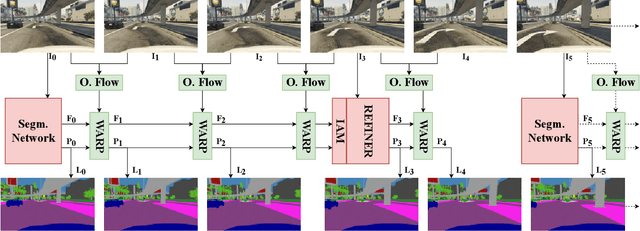
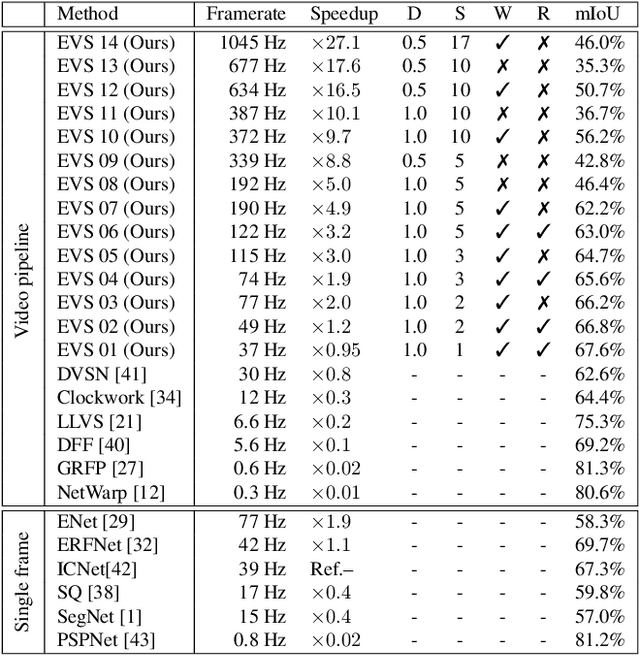
This paper tackles the problem of real-time semantic segmentation of high definition videos using a hybrid GPU / CPU approach. We propose an Efficient Video Segmentation(EVS) pipeline that combines: (i) On the CPU, a very fast optical flow method, that is used to exploit the temporal aspect of the video and propagate semantic information from one frame to the next. It runs in parallel with the GPU. (ii) On the GPU, two Convolutional Neural Networks: A main segmentation network that is used to predict dense semantic labels from scratch, and a Refiner that is designed to improve predictions from previous frames with the help of a fast Inconsistencies Attention Module (IAM). The latter can identify regions that cannot be propagated accurately. We suggest several operating points depending on the desired frame rate and accuracy. Our pipeline achieves accuracy levels competitive to the existing real-time methods for semantic image segmentation(mIoU above 60%), while achieving much higher frame rates. On the popular Cityscapes dataset with high resolution frames (2048 x 1024), the proposed operating points range from 80 to 1000 Hz on a single GPU and CPU.
Adversarial Feature Distribution Alignment for Semi-Supervised Learning
Dec 22, 2019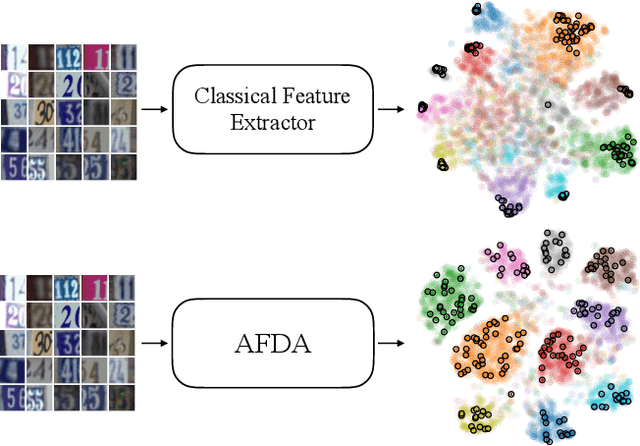
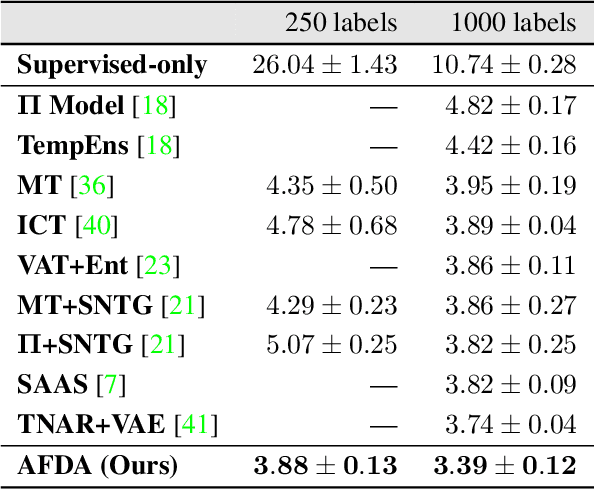
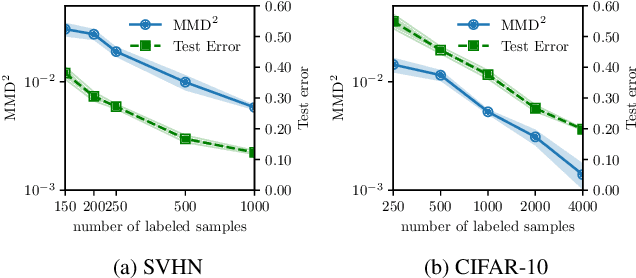

Training deep neural networks with only a few labeled samples can lead to overfitting. This is problematic in semi-supervised learning where only a few labeled samples are available. In this paper, we show that a consequence of overfitting in SSL is feature distribution misalignment between labeled and unlabeled samples. Hence, we propose a new feature distribution alignment method. Our method is particularly effective when using only a small amount of labeled samples. We test our method on CIFAR10 and SVHN. On SVHN we achieve a test error of 3.88% (250 labeled samples) and 3.39% (1000 labeled samples) which is close to the fully supervised model 2.89% (73k labeled samples). In comparison, the current SOTA achieves only 4.29% and 3.74%. Finally, we provide a theoretical insight why feature distribution alignment occurs and show that our method reduces it.
Adversarial Sampling for Active Learning
Aug 20, 2018
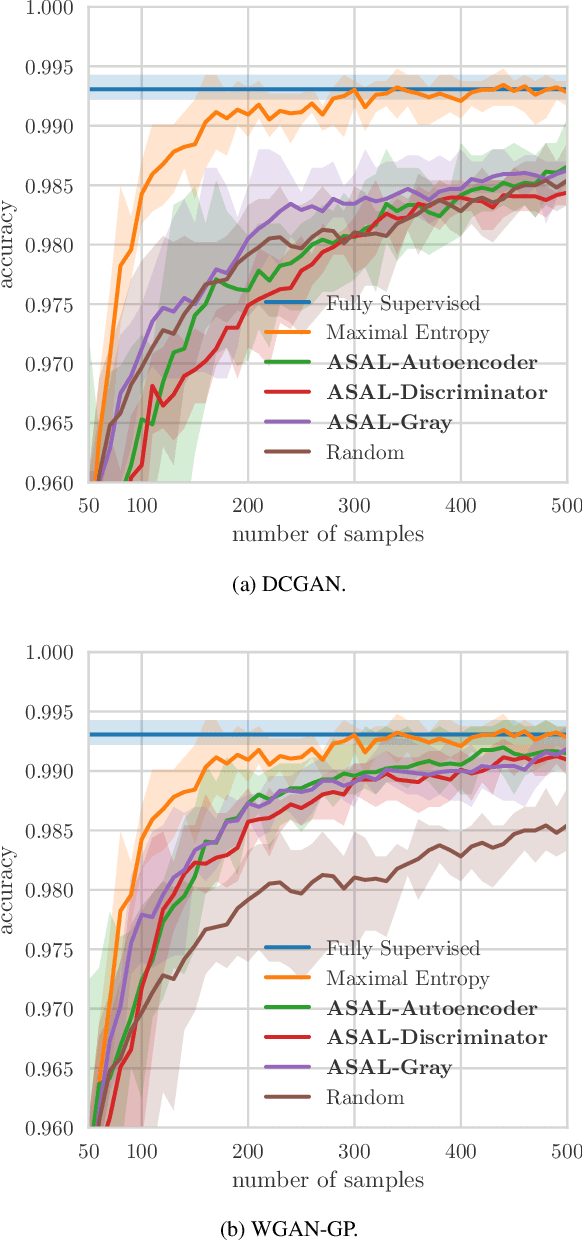
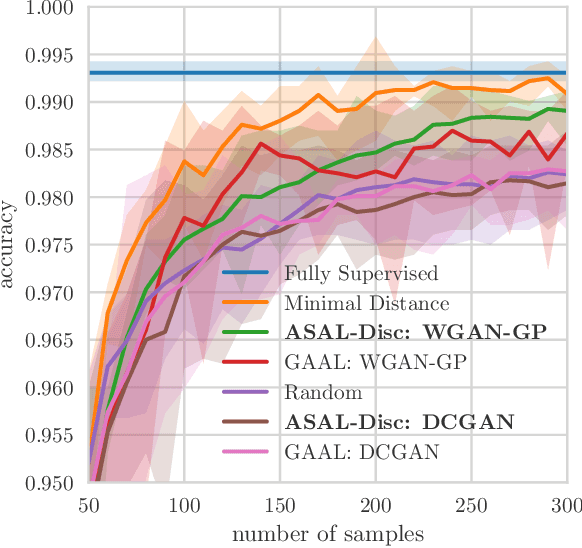
This paper describes ASAL a new active learning strategy that uses uncertainty sampling, adversarial sample generation and sample matching. Compared to traditional pool-based uncertainty sampling strategies, ASAL synthesizes uncertain samples instead of performing an exhaustive search in each active learning cycle. Then, the sample matching efficiently selects similar samples from the pool. We present a comprehensive set of experiments on MNIST and CIFAR-10 and show that ASAL outperforms similar methods and clearly exceeds passive learning. To the best of our knowledge this is the first pool-based adversarial active learning technique and the first that is applied for multi-label classification using deep convolutional classifiers.
Towards Closing the Gap in Weakly Supervised Semantic Segmentation with DCNNs: Combining Local and Global Models
Aug 05, 2018

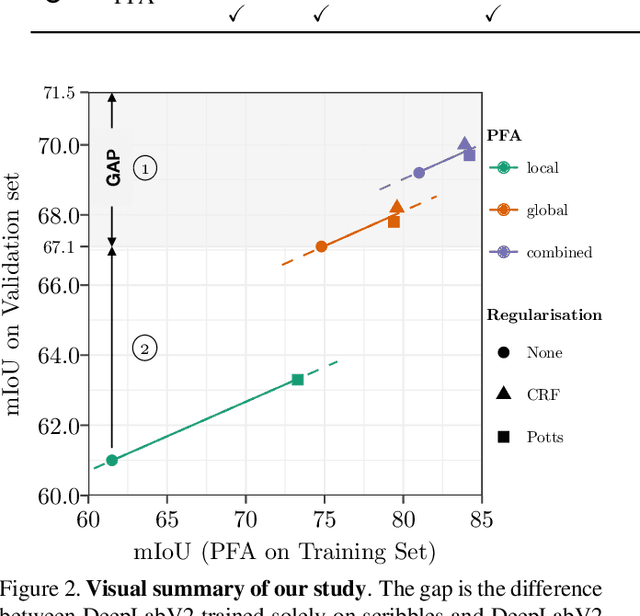
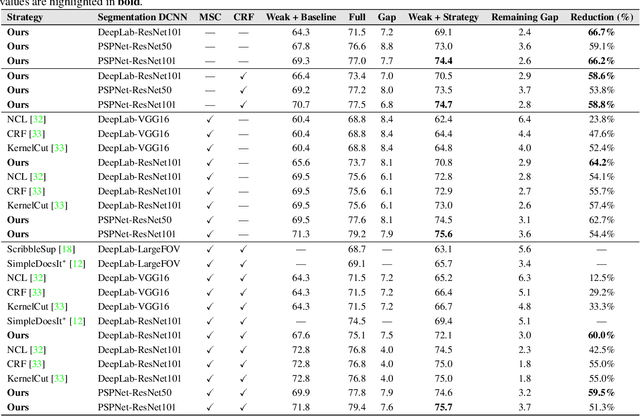
Generating training sets for deep convolutional neural networks is a bottleneck for modern real-world applications. This is a demanding tasks for applications where annotating training data is costly, such as in semantic segmentation. In the literature, there is still a gap between the performance achieved by a network trained on full and on weak annotations. In this paper, we establish a strategy to measure this gap and to identify the ingredients necessary to close it. On scribbles, we establish state-of-the-art results comparable to the latest published ones (Tang et al., 2018, arXiv:1804.01346): we obtain a gap in mIoU of 2.4% without CRF (2.8% in Tang et al., 2018, arXiv:1804.01346), and 2.9% with CRF post-processing (2.3% in Tang et al., 2018, arXiv:1804.01346). However, we use completely different ideas: combining local and global annotator models and regularising their prediction to train DeepLabV2. Finally, closing the gap was reported only recently for bounding boxes in Khoreva et al. (arXiv:1603.07485v2), by requiring 10x more training images. By simulating varying amounts of pixel-level annotations respecting scribble human annotations statistics, we show that our training strategy reacts to small increases in the amount of annotations and requires only 2-5x more annotated pixels, closing the gap with only 3.1% of all pixels annotated. This work contributes new ideas towards closing the gap in real-world applications.