 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Closing the Gap in Weakly Supervised Semantic Segmentation with DCNNs: Combining Local and Global Models
Paper and Code
Aug 05, 2018

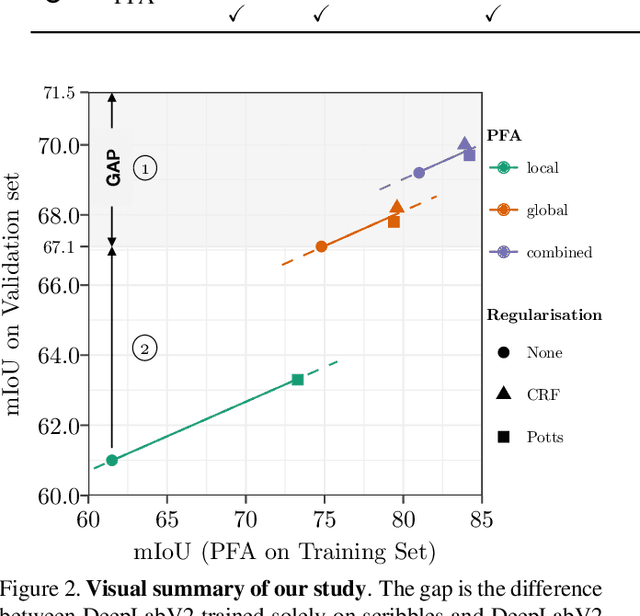
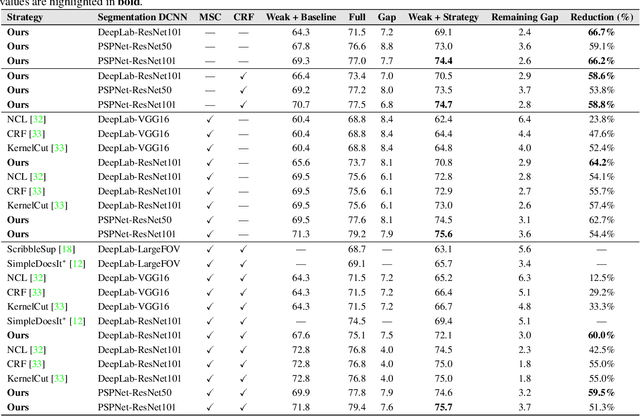
Generating training sets for deep convolutional neural networks is a bottleneck for modern real-world applications. This is a demanding tasks for applications where annotating training data is costly, such as in semantic segmentation. In the literature, there is still a gap between the performance achieved by a network trained on full and on weak annotations. In this paper, we establish a strategy to measure this gap and to identify the ingredients necessary to close it. On scribbles, we establish state-of-the-art results comparable to the latest published ones (Tang et al., 2018, arXiv:1804.01346): we obtain a gap in mIoU of 2.4% without CRF (2.8% in Tang et al., 2018, arXiv:1804.01346), and 2.9% with CRF post-processing (2.3% in Tang et al., 2018, arXiv:1804.01346). However, we use completely different ideas: combining local and global annotator models and regularising their prediction to train DeepLabV2. Finally, closing the gap was reported only recently for bounding boxes in Khoreva et al. (arXiv:1603.07485v2), by requiring 10x more training images. By simulating varying amounts of pixel-level annotations respecting scribble human annotations statistics, we show that our training strategy reacts to small increases in the amount of annotations and requires only 2-5x more annotated pixels, closing the gap with only 3.1% of all pixels annotated. This work contributes new ideas towards closing the gap in real-world applications.