 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Visual Tracking by Segmentation
Paper and Code
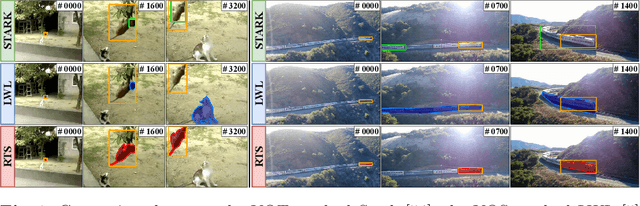

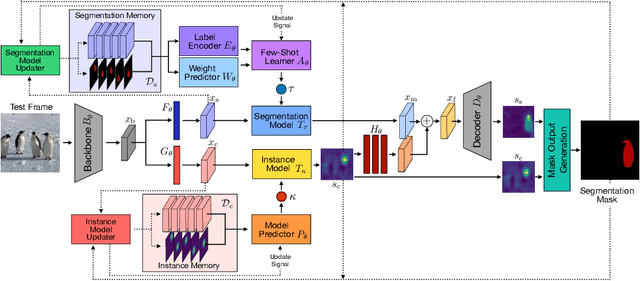
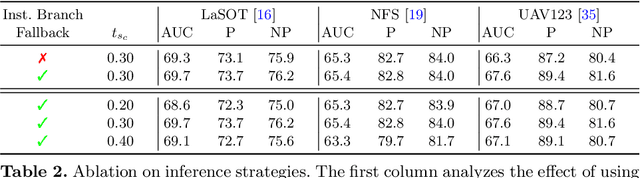
Estimating the target extent poses a fundamental challenge in visual object tracking. Typically, trackers are box-centric and fully rely on a bounding box to define the target in the scene. In practice, objects often have complex shapes and are not aligned with the image axis. In these cases, bounding boxes do not provide an accurate description of the target and often contain a majority of background pixels. We propose a segmentation-centric tracking pipeline that not only produces a highly accurate segmentation mask, but also works internally with segmentation masks instead of bounding boxes. Thus, our tracker is able to better learn a target representation that clearly differentiates the target in the scene from background content. In order to achieve the necessary robustness for the challenging tracking scenario, we propose a separate instance localization component that is used to condition the segmentation decoder when producing the output mask. We infer a bounding box from the segmentation mask and validate our tracker on challenging tracking datasets and achieve the new state of the art on LaSOT with a success AUC score of 69.7%. Since fully evaluating the predicted masks on tracking datasets is not possible due to the missing mask annotations, we further validate our segmentation quality on two popular video object segmentation datasets.