 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Model Prediction for Tracking
Mar 21, 2022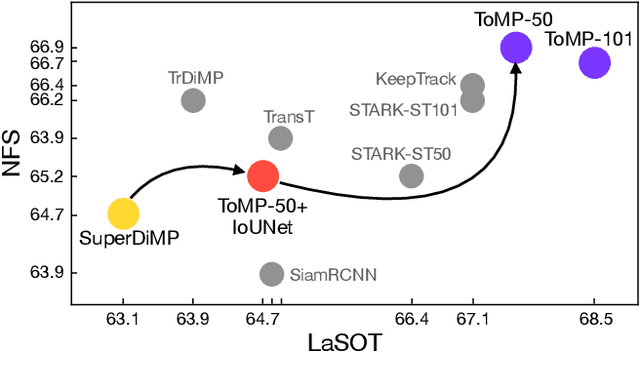
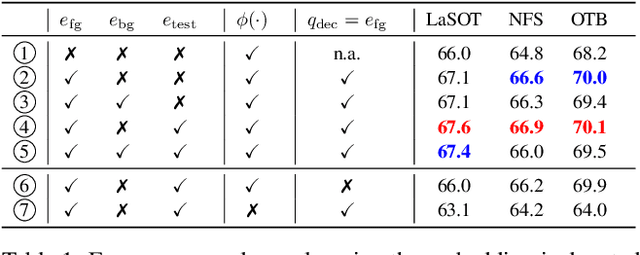
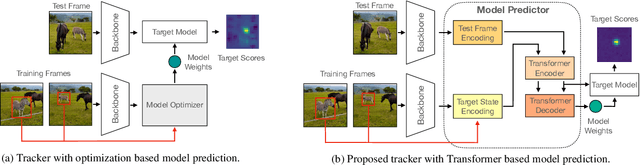

Optimization based tracking methods have been widely successful by integrating a target model prediction module, providing effective global reasoning by minimizing an objective function. While this inductive bias integrates valuable domain knowledge, it limits the expressivity of the tracking network. In this work, we therefore propose a tracker architecture employing a Transformer-based model prediction module. Transformers capture global relations with little inductive bias, allowing it to learn the prediction of more powerful target models. We further extend the model predictor to estimate a second set of weights that are applied for accurate bounding box regression. The resulting tracker relies on training and on test frame information in order to predict all weights transductively. We train the proposed tracker end-to-end and validate its performance by conducting comprehensive experiments on multiple tracking datasets. Our tracker sets a new state of the art on three benchmarks, achieving an AUC of 68.5% on the challenging LaSOT dataset.
Robust Visual Tracking by Segmentation
Mar 21, 2022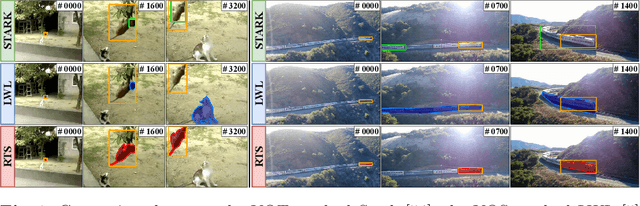

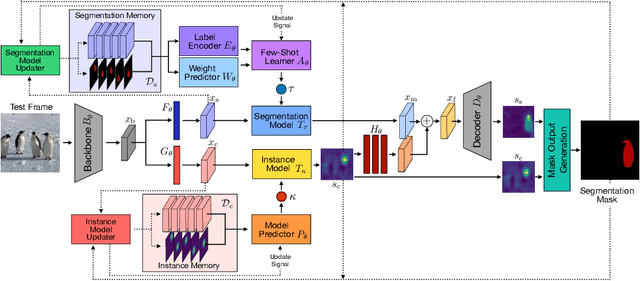
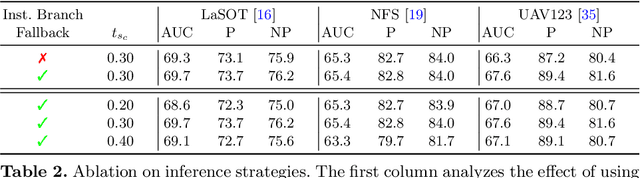
Estimating the target extent poses a fundamental challenge in visual object tracking. Typically, trackers are box-centric and fully rely on a bounding box to define the target in the scene. In practice, objects often have complex shapes and are not aligned with the image axis. In these cases, bounding boxes do not provide an accurate description of the target and often contain a majority of background pixels. We propose a segmentation-centric tracking pipeline that not only produces a highly accurate segmentation mask, but also works internally with segmentation masks instead of bounding boxes. Thus, our tracker is able to better learn a target representation that clearly differentiates the target in the scene from background content. In order to achieve the necessary robustness for the challenging tracking scenario, we propose a separate instance localization component that is used to condition the segmentation decoder when producing the output mask. We infer a bounding box from the segmentation mask and validate our tracker on challenging tracking datasets and achieve the new state of the art on LaSOT with a success AUC score of 69.7%. Since fully evaluating the predicted masks on tracking datasets is not possible due to the missing mask annotations, we further validate our segmentation quality on two popular video object segmentation datasets.
Local Memory Attention for Fast Video Semantic Segmentation
Jan 05, 2021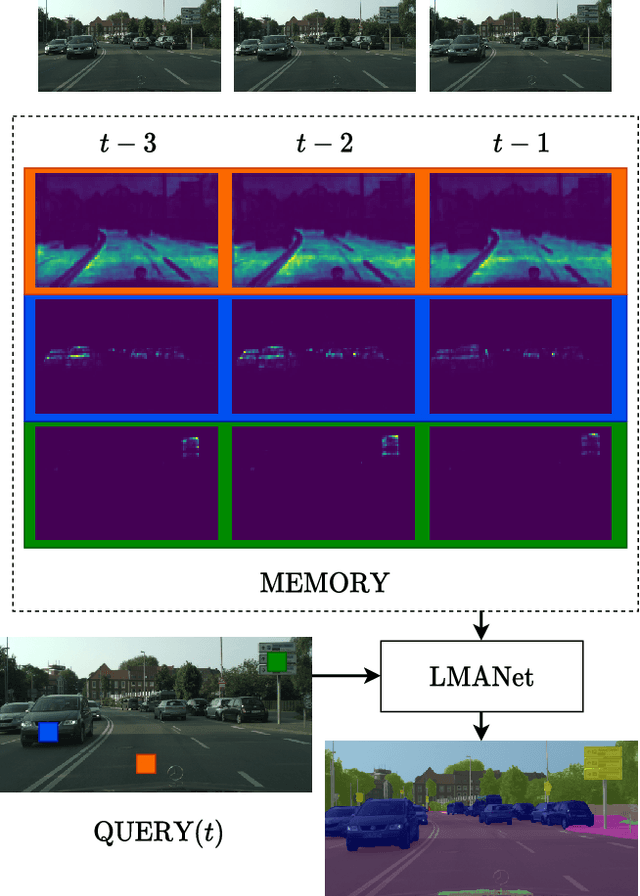
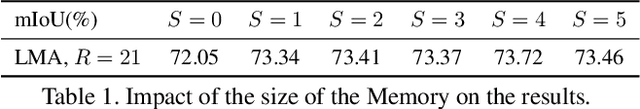
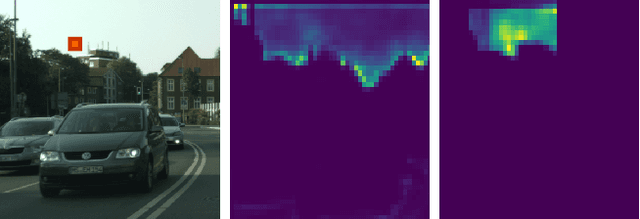

We propose a novel neural network module that transforms an existing single-frame semantic segmentation model into a video semantic segmentation pipeline. In contrast to prior works, we strive towards a simple and general module that can be integrated into virtually any single-frame architecture. Our approach aggregates a rich representation of the semantic information in past frames into a memory module. Information stored in the memory is then accessed through an attention mechanism. This provides temporal appearance cues from prior frames, which are then fused with an encoding of the current frame through a second attention-based module. The segmentation decoder processes the fused representation to predict the final semantic segmentation. We integrate our approach into two popular semantic segmentation networks: ERFNet and PSPNet. We observe an improvement in segmentation performance on Cityscapes by 1.7% and 2.1% in mIoU respectively, while increasing inference time of ERFNet by only 1.5ms.
Efficient Video Semantic Segmentation with Labels Propagation and Refinement
Dec 26, 2019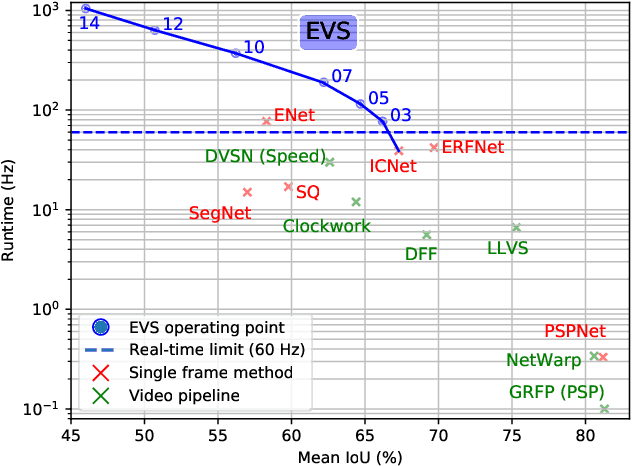

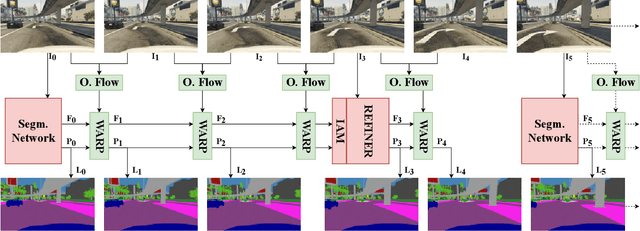
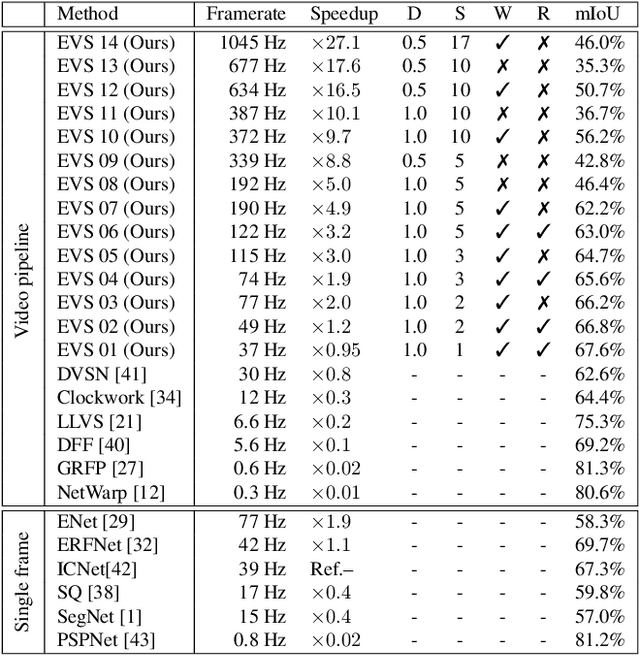
This paper tackles the problem of real-time semantic segmentation of high definition videos using a hybrid GPU / CPU approach. We propose an Efficient Video Segmentation(EVS) pipeline that combines: (i) On the CPU, a very fast optical flow method, that is used to exploit the temporal aspect of the video and propagate semantic information from one frame to the next. It runs in parallel with the GPU. (ii) On the GPU, two Convolutional Neural Networks: A main segmentation network that is used to predict dense semantic labels from scratch, and a Refiner that is designed to improve predictions from previous frames with the help of a fast Inconsistencies Attention Module (IAM). The latter can identify regions that cannot be propagated accurately. We suggest several operating points depending on the desired frame rate and accuracy. Our pipeline achieves accuracy levels competitive to the existing real-time methods for semantic image segmentation(mIoU above 60%), while achieving much higher frame rates. On the popular Cityscapes dataset with high resolution frames (2048 x 1024), the proposed operating points range from 80 to 1000 Hz on a single GPU and CPU.
Adversarial Feature Distribution Alignment for Semi-Supervised Learning
Dec 22, 2019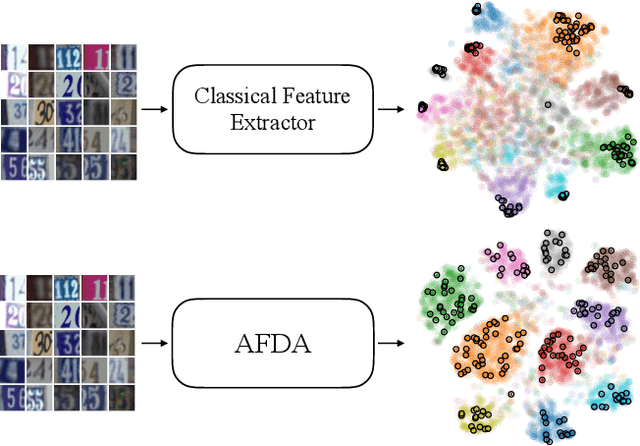
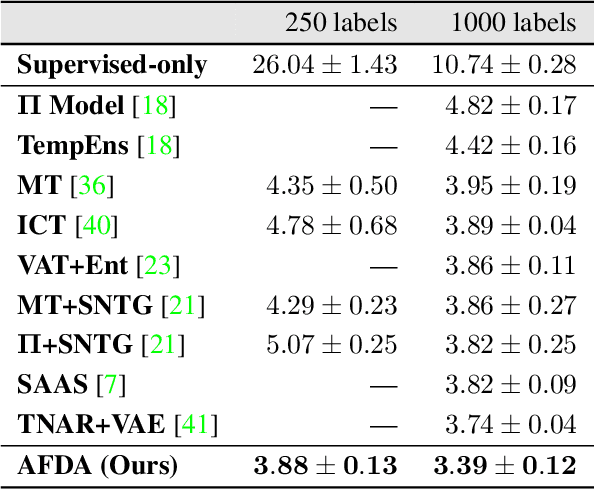
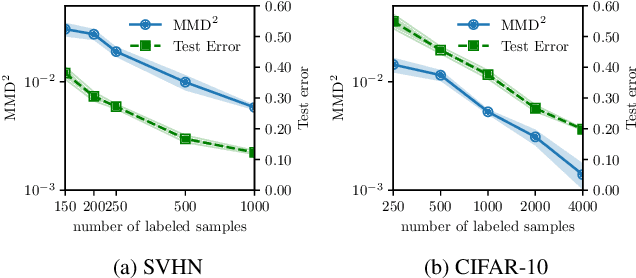

Training deep neural networks with only a few labeled samples can lead to overfitting. This is problematic in semi-supervised learning where only a few labeled samples are available. In this paper, we show that a consequence of overfitting in SSL is feature distribution misalignment between labeled and unlabeled samples. Hence, we propose a new feature distribution alignment method. Our method is particularly effective when using only a small amount of labeled samples. We test our method on CIFAR10 and SVHN. On SVHN we achieve a test error of 3.88% (250 labeled samples) and 3.39% (1000 labeled samples) which is close to the fully supervised model 2.89% (73k labeled samples). In comparison, the current SOTA achieves only 4.29% and 3.74%. Finally, we provide a theoretical insight why feature distribution alignment occurs and show that our method reduces it.