 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Feature Distribution Alignment for Semi-Supervised Learning
Paper and Code
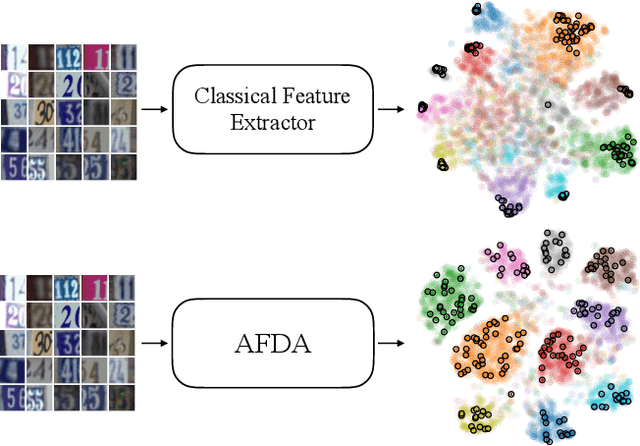
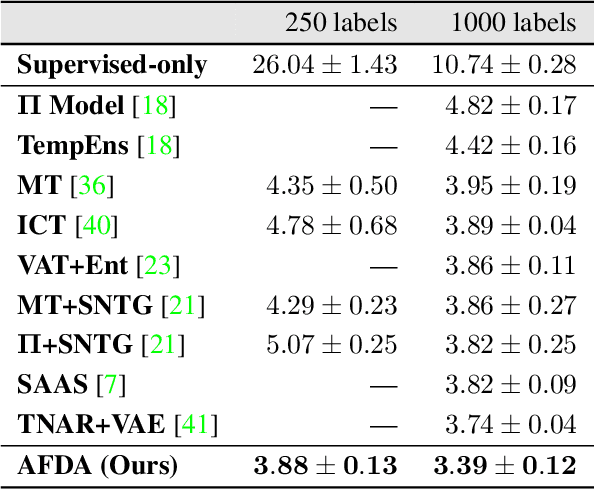
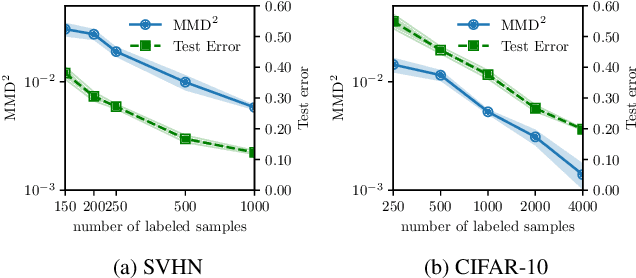

Training deep neural networks with only a few labeled samples can lead to overfitting. This is problematic in semi-supervised learning where only a few labeled samples are available. In this paper, we show that a consequence of overfitting in SSL is feature distribution misalignment between labeled and unlabeled samples. Hence, we propose a new feature distribution alignment method. Our method is particularly effective when using only a small amount of labeled samples. We test our method on CIFAR10 and SVHN. On SVHN we achieve a test error of 3.88% (250 labeled samples) and 3.39% (1000 labeled samples) which is close to the fully supervised model 2.89% (73k labeled samples). In comparison, the current SOTA achieves only 4.29% and 3.74%. Finally, we provide a theoretical insight why feature distribution alignment occurs and show that our method reduces it.