 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterNeRF: Scaling Radiance Fields via Parameter Interpolation
Jun 17, 2024Neural Radiance Fields (NeRFs) have unmatched fidelity on large, real-world scenes. A common approach for scaling NeRFs is to partition the scene into regions, each of which is assigned its own parameters. When implemented naively, such an approach is limited by poor test-time scaling and inconsistent appearance and geometry. We instead propose InterNeRF, a novel architecture for rendering a target view using a subset of the model's parameters. Our approach enables out-of-core training and rendering, increasing total model capacity with only a modest increase to training time. We demonstrate significant improvements in multi-room scenes while remaining competitive on standard benchmarks.
RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
Mar 20, 2024



Recent advances in view synthesis and real-time rendering have achieved photorealistic quality at impressive rendering speeds. While Radiance Field-based methods achieve state-of-the-art quality in challenging scenarios such as in-the-wild captures and large-scale scenes, they often suffer from excessively high compute requirements linked to volumetric rendering. Gaussian Splatting-based methods, on the other hand, rely on rasterization and naturally achieve real-time rendering but suffer from brittle optimization heuristics that underperform on more challenging scenes. In this work, we present RadSplat, a lightweight method for robust real-time rendering of complex scenes. Our main contributions are threefold. First, we use radiance fields as a prior and supervision signal for optimizing point-based scene representations, leading to improved quality and more robust optimization. Next, we develop a novel pruning technique reducing the overall point count while maintaining high quality, leading to smaller and more compact scene representations with faster inference speeds. Finally, we propose a novel test-time filtering approach that further accelerates rendering and allows to scale to larger, house-sized scenes. We find that our method enables state-of-the-art synthesis of complex captures at 900+ FPS.
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
Dec 12, 2023



Recent techniques for real-time view synthesis have rapidly advanced in fidelity and speed, and modern methods are capable of rendering near-photorealistic scenes at interactive frame rates. At the same time, a tension has arisen between explicit scene representations amenable to rasterization and neural fields built on ray marching, with state-of-the-art instances of the latter surpassing the former in quality while being prohibitively expensive for real-time applications. In this work, we introduce SMERF, a view synthesis approach that achieves state-of-the-art accuracy among real-time methods on large scenes with footprints up to 300 m$^2$ at a volumetric resolution of 3.5 mm$^3$. Our method is built upon two primary contributions: a hierarchical model partitioning scheme, which increases model capacity while constraining compute and memory consumption, and a distillation training strategy that simultaneously yields high fidelity and internal consistency. Our approach enables full six degrees of freedom (6DOF) navigation within a web browser and renders in real-time on commodity smartphones and laptops. Extensive experiments show that our method exceeds the current state-of-the-art in real-time novel view synthesis by 0.78 dB on standard benchmarks and 1.78 dB on large scenes, renders frames three orders of magnitude faster than state-of-the-art radiance field models, and achieves real-time performance across a wide variety of commodity devices, including smartphones. We encourage the reader to explore these models in person at our project website: https://smerf-3d.github.io.
RePAST: Relative Pose Attention Scene Representation Transformer
Apr 10, 2023The Scene Representation Transformer (SRT) is a recent method to render novel views at interactive rates. Since SRT uses camera poses with respect to an arbitrarily chosen reference camera, it is not invariant to the order of the input views. As a result, SRT is not directly applicable to large-scale scenes where the reference frame would need to be changed regularly. In this work, we propose Relative Pose Attention SRT (RePAST): Instead of fixing a reference frame at the input, we inject pairwise relative camera pose information directly into the attention mechanism of the Transformers. This leads to a model that is by definition invariant to the choice of any global reference frame, while still retaining the full capabilities of the original method. Empirical results show that adding this invariance to the model does not lead to a loss in quality. We believe that this is a step towards applying fully latent transformer-based rendering methods to large-scale scenes.
PaLM-E: An Embodied Multimodal Language Model
Mar 06, 2023

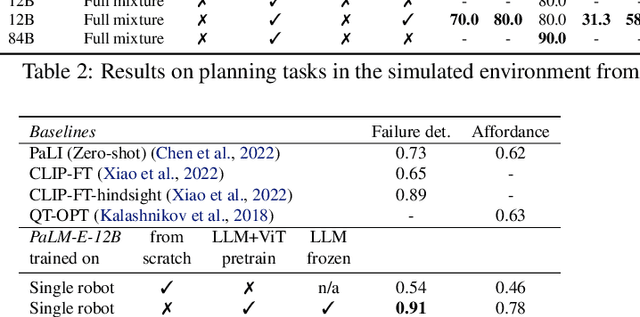

Large language models excel at a wide range of complex tasks. However, enabling general inference in the real world, e.g., for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.
RobustNeRF: Ignoring Distractors with Robust Losses
Feb 02, 2023Neural radiance fields (NeRF) excel at synthesizing new views given multi-view, calibrated images of a static scene. When scenes include distractors, which are not persistent during image capture (moving objects, lighting variations, shadows), artifacts appear as view-dependent effects or 'floaters'. To cope with distractors, we advocate a form of robust estimation for NeRF training, modeling distractors in training data as outliers of an optimization problem. Our method successfully removes outliers from a scene and improves upon our baselines, on synthetic and real-world scenes. Our technique is simple to incorporate in modern NeRF frameworks, with few hyper-parameters. It does not assume a priori knowledge of the types of distractors, and is instead focused on the optimization problem rather than pre-processing or modeling transient objects. More results on our page https://robustnerf.github.io/public.
RUST: Latent Neural Scene Representations from Unposed Imagery
Nov 25, 2022



Inferring the structure of 3D scenes from 2D observations is a fundamental challenge in computer vision. Recently popularized approaches based on neural scene representations have achieved tremendous impact and have been applied across a variety of applications. One of the major remaining challenges in this space is training a single model which can provide latent representations which effectively generalize beyond a single scene. Scene Representation Transformer (SRT) has shown promise in this direction, but scaling it to a larger set of diverse scenes is challenging and necessitates accurately posed ground truth data. To address this problem, we propose RUST (Really Unposed Scene representation Transformer), a pose-free approach to novel view synthesis trained on RGB images alone. Our main insight is that one can train a Pose Encoder that peeks at the target image and learns a latent pose embedding which is used by the decoder for view synthesis. We perform an empirical investigation into the learned latent pose structure and show that it allows meaningful test-time camera transformations and accurate explicit pose readouts. Perhaps surprisingly, RUST achieves similar quality as methods which have access to perfect camera pose, thereby unlocking the potential for large-scale training of amortized neural scene representations.
Object Scene Representation Transformer
Jun 14, 2022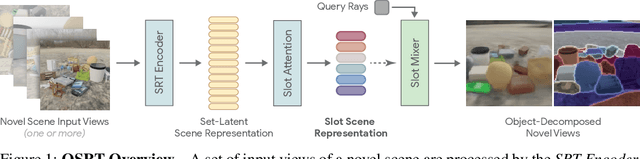

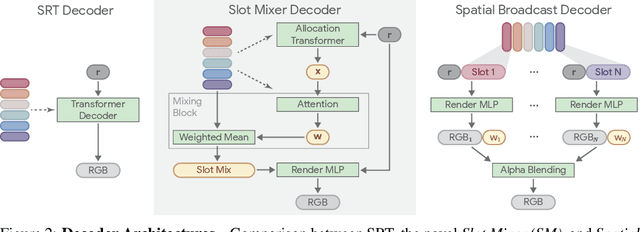
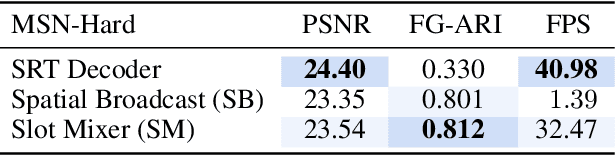
A compositional understanding of the world in terms of objects and their geometry in 3D space is considered a cornerstone of human cognition. Facilitating the learning of such a representation in neural networks holds promise for substantially improving labeled data efficiency. As a key step in this direction, we make progress on the problem of learning 3D-consistent decompositions of complex scenes into individual objects in an unsupervised fashion. We introduce Object Scene Representation Transformer (OSRT), a 3D-centric model in which individual object representations naturally emerge through novel view synthesis. OSRT scales to significantly more complex scenes with larger diversity of objects and backgrounds than existing methods. At the same time, it is multiple orders of magnitude faster at compositional rendering thanks to its light field parametrization and the novel Slot Mixer decoder. We believe this work will not only accelerate future architecture exploration and scaling efforts, but it will also serve as a useful tool for both object-centric as well as neural scene representation learning communities.
Kubric: A scalable dataset generator
Mar 07, 2022

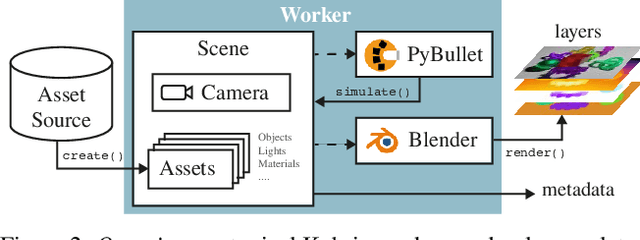
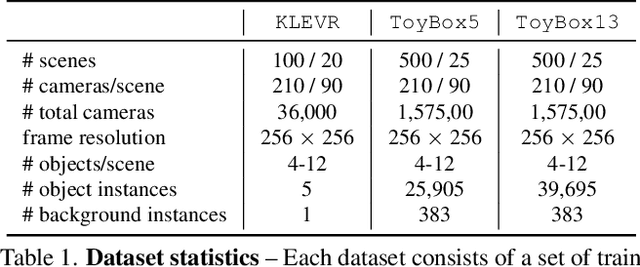
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
NeSF: Neural Semantic Fields for Generalizable Semantic Segmentation of 3D Scenes
Dec 03, 2021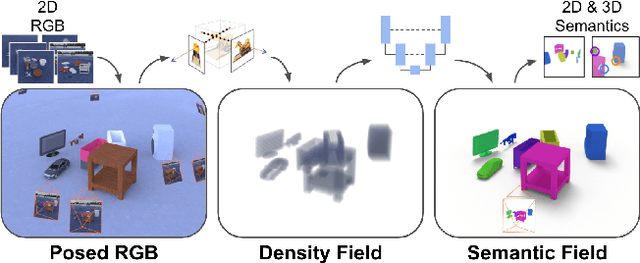

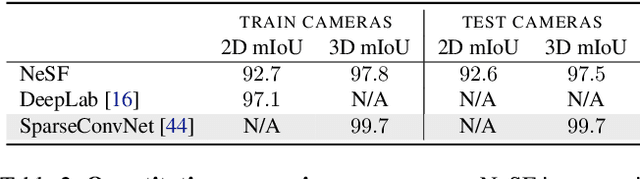
We present NeSF, a method for producing 3D semantic fields from posed RGB images alone. In place of classical 3D representations, our method builds on recent work in implicit neural scene representations wherein 3D structure is captured by point-wise functions. We leverage this methodology to recover 3D density fields upon which we then train a 3D semantic segmentation model supervised by posed 2D semantic maps. Despite being trained on 2D signals alone, our method is able to generate 3D-consistent semantic maps from novel camera poses and can be queried at arbitrary 3D points. Notably, NeSF is compatible with any method producing a density field, and its accuracy improves as the quality of the density field improves. Our empirical analysis demonstrates comparable quality to competitive 2D and 3D semantic segmentation baselines on complex, realistically rendered synthetic scenes. Our method is the first to offer truly dense 3D scene segmentations requiring only 2D supervision for training, and does not require any semantic input for inference on novel scenes. We encourage the readers to visit the project website.