 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
Volumetric Surfaces: Representing Fuzzy Geometries with Multiple Meshes
Sep 04, 2024



High-quality real-time view synthesis methods are based on volume rendering, splatting, or surface rendering. While surface-based methods generally are the fastest, they cannot faithfully model fuzzy geometry like hair. In turn, alpha-blending techniques excel at representing fuzzy materials but require an unbounded number of samples per ray (P1). Further overheads are induced by empty space skipping in volume rendering (P2) and sorting input primitives in splatting (P3). These problems are exacerbated on low-performance graphics hardware, e.g. on mobile devices. We present a novel representation for real-time view synthesis where the (P1) number of sampling locations is small and bounded, (P2) sampling locations are efficiently found via rasterization, and (P3) rendering is sorting-free. We achieve this by representing objects as semi-transparent multi-layer meshes, rendered in fixed layer order from outermost to innermost. We model mesh layers as SDF shells with optimal spacing learned during training. After baking, we fit UV textures to the corresponding meshes. We show that our method can represent challenging fuzzy objects while achieving higher frame rates than volume-based and splatting-based methods on low-end and mobile devices.
Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
Feb 19, 2024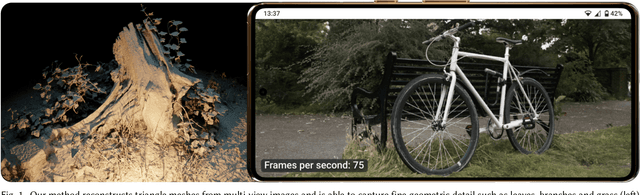



While surface-based view synthesis algorithms are appealing due to their low computational requirements, they often struggle to reproduce thin structures. In contrast, more expensive methods that model the scene's geometry as a volumetric density field (e.g. NeRF) excel at reconstructing fine geometric detail. However, density fields often represent geometry in a "fuzzy" manner, which hinders exact localization of the surface. In this work, we modify density fields to encourage them to converge towards surfaces, without compromising their ability to reconstruct thin structures. First, we employ a discrete opacity grid representation instead of a continuous density field, which allows opacity values to discontinuously transition from zero to one at the surface. Second, we anti-alias by casting multiple rays per pixel, which allows occlusion boundaries and subpixel structures to be modelled without using semi-transparent voxels. Third, we minimize the binary entropy of the opacity values, which facilitates the extraction of surface geometry by encouraging opacity values to binarize towards the end of training. Lastly, we develop a fusion-based meshing strategy followed by mesh simplification and appearance model fitting. The compact meshes produced by our model can be rendered in real-time on mobile devices and achieve significantly higher view synthesis quality compared to existing mesh-based approaches.
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
Dec 12, 2023



Recent techniques for real-time view synthesis have rapidly advanced in fidelity and speed, and modern methods are capable of rendering near-photorealistic scenes at interactive frame rates. At the same time, a tension has arisen between explicit scene representations amenable to rasterization and neural fields built on ray marching, with state-of-the-art instances of the latter surpassing the former in quality while being prohibitively expensive for real-time applications. In this work, we introduce SMERF, a view synthesis approach that achieves state-of-the-art accuracy among real-time methods on large scenes with footprints up to 300 m$^2$ at a volumetric resolution of 3.5 mm$^3$. Our method is built upon two primary contributions: a hierarchical model partitioning scheme, which increases model capacity while constraining compute and memory consumption, and a distillation training strategy that simultaneously yields high fidelity and internal consistency. Our approach enables full six degrees of freedom (6DOF) navigation within a web browser and renders in real-time on commodity smartphones and laptops. Extensive experiments show that our method exceeds the current state-of-the-art in real-time novel view synthesis by 0.78 dB on standard benchmarks and 1.78 dB on large scenes, renders frames three orders of magnitude faster than state-of-the-art radiance field models, and achieves real-time performance across a wide variety of commodity devices, including smartphones. We encourage the reader to explore these models in person at our project website: https://smerf-3d.github.io.
BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis
Feb 28, 2023
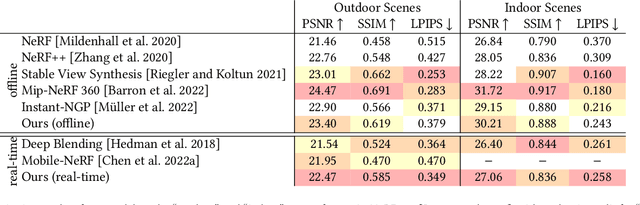

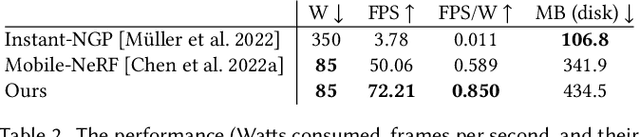
We present a method for reconstructing high-quality meshes of large unbounded real-world scenes suitable for photorealistic novel view synthesis. We first optimize a hybrid neural volume-surface scene representation designed to have well-behaved level sets that correspond to surfaces in the scene. We then bake this representation into a high-quality triangle mesh, which we equip with a simple and fast view-dependent appearance model based on spherical Gaussians. Finally, we optimize this baked representation to best reproduce the captured viewpoints, resulting in a model that can leverage accelerated polygon rasterization pipelines for real-time view synthesis on commodity hardware. Our approach outperforms previous scene representations for real-time rendering in terms of accuracy, speed, and power consumption, and produces high quality meshes that enable applications such as appearance editing and physical simulation.
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
Feb 23, 2023



Neural radiance fields enable state-of-the-art photorealistic view synthesis. However, existing radiance field representations are either too compute-intensive for real-time rendering or require too much memory to scale to large scenes. We present a Memory-Efficient Radiance Field (MERF) representation that achieves real-time rendering of large-scale scenes in a browser. MERF reduces the memory consumption of prior sparse volumetric radiance fields using a combination of a sparse feature grid and high-resolution 2D feature planes. To support large-scale unbounded scenes, we introduce a novel contraction function that maps scene coordinates into a bounded volume while still allowing for efficient ray-box intersection. We design a lossless procedure for baking the parameterization used during training into a model that achieves real-time rendering while still preserving the photorealistic view synthesis quality of a volumetric radiance field.
Observational and Interventional Causal Learning for Regret-Minimizing Control
Dec 05, 2022We explore how observational and interventional causal discovery methods can be combined. A state-of-the-art observational causal discovery algorithm for time series capable of handling latent confounders and contemporaneous effects, called LPCMCI, is extended to profit from casual constraints found through randomized control trials. Numerical results show that, given perfect interventional constraints, the reconstructed structural causal models (SCMs) of the extended LPCMCI allow 84.6% of the time for the optimal prediction of the target variable. The implementation of interventional and observational causal discovery is modular, allowing causal constraints from other sources. The second part of this thesis investigates the question of regret minimizing control by simultaneously learning a causal model and planning actions through the causal model. The idea is that an agent to optimize a measured variable first learns the system's mechanics through observational causal discovery. The agent then intervenes on the most promising variable with randomized values allowing for the exploitation and generation of new interventional data. The agent then uses the interventional data to enhance the causal model further, allowing improved actions the next time. The extended LPCMCI can be favorable compared to the original LPCMCI algorithm. The numerical results show that detecting and using interventional constraints leads to reconstructed SCMs that allow 60.9% of the time for the optimal prediction of the target variable in contrast to the baseline of 53.6% when using the original LPCMCI algorithm. Furthermore, the induced average regret decreases from 1.2 when using the original LPCMCI algorithm to 1.0 when using the extended LPCMCI algorithm with interventional discovery.
Causal discovery for time series with latent confounders
Sep 07, 2022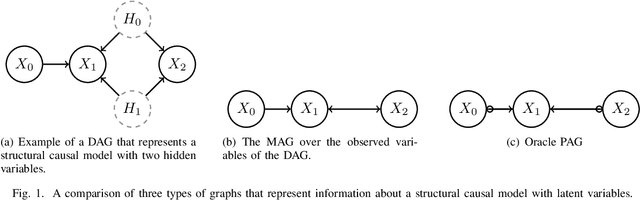
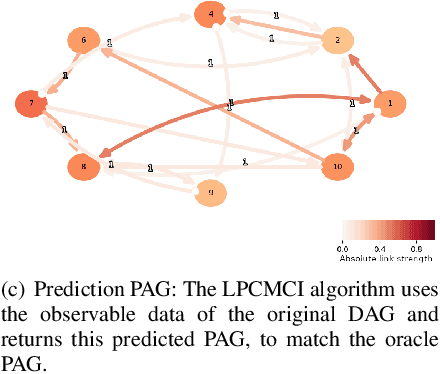
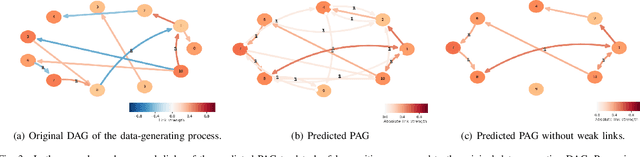

Reconstructing the causal relationships behind the phenomena we observe is a fundamental challenge in all areas of science. Discovering causal relationships through experiments is often infeasible, unethical, or expensive in complex systems. However, increases in computational power allow us to process the ever-growing amount of data that modern science generates, leading to an emerging interest in the causal discovery problem from observational data. This work evaluates the LPCMCI algorithm, which aims to find generators compatible with a multi-dimensional, highly autocorrelated time series while some variables are unobserved. We find that LPCMCI performs much better than a random algorithm mimicking not knowing anything but is still far from optimal detection. Furthermore, LPCMCI performs best on auto-dependencies, then contemporaneous dependencies, and struggles most with lagged dependencies. The source code of this project is available online.
KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
Mar 25, 2021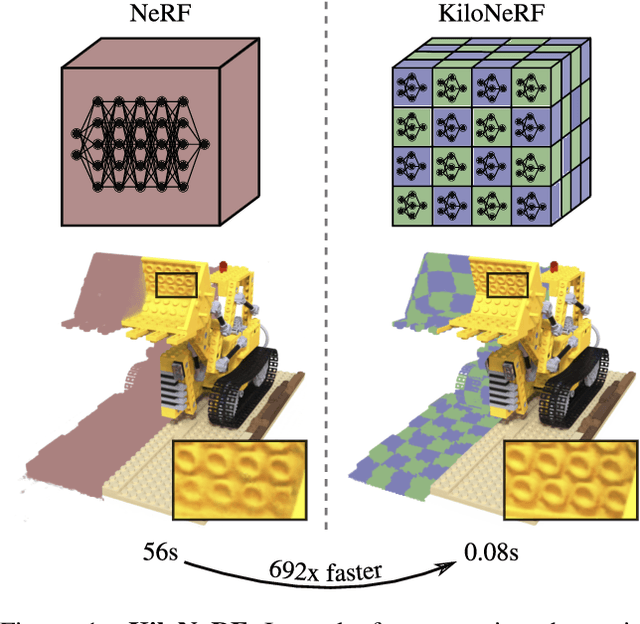
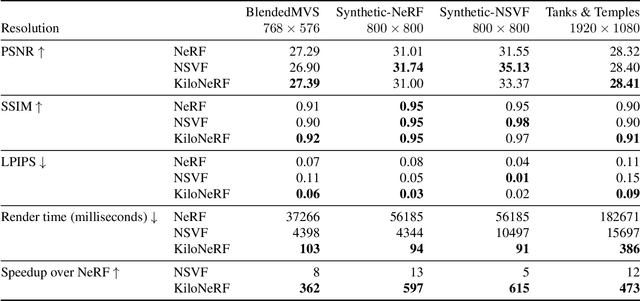
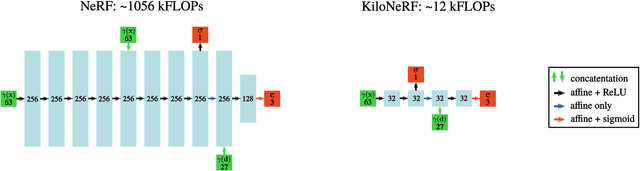

NeRF synthesizes novel views of a scene with unprecedented quality by fitting a neural radiance field to RGB images. However, NeRF requires querying a deep Multi-Layer Perceptron (MLP) millions of times, leading to slow rendering times, even on modern GPUs. In this paper, we demonstrate that significant speed-ups are possible by utilizing thousands of tiny MLPs instead of one single large MLP. In our setting, each individual MLP only needs to represent parts of the scene, thus smaller and faster-to-evaluate MLPs can be used. By combining this divide-and-conquer strategy with further optimizations, rendering is accelerated by two orders of magnitude compared to the original NeRF model without incurring high storage costs. Further, using teacher-student distillation for training, we show that this speed-up can be achieved without sacrificing visual quality.
Parallel Total Variation Distance Estimation with Neural Networks for Merging Over-Clusterings
Dec 09, 2019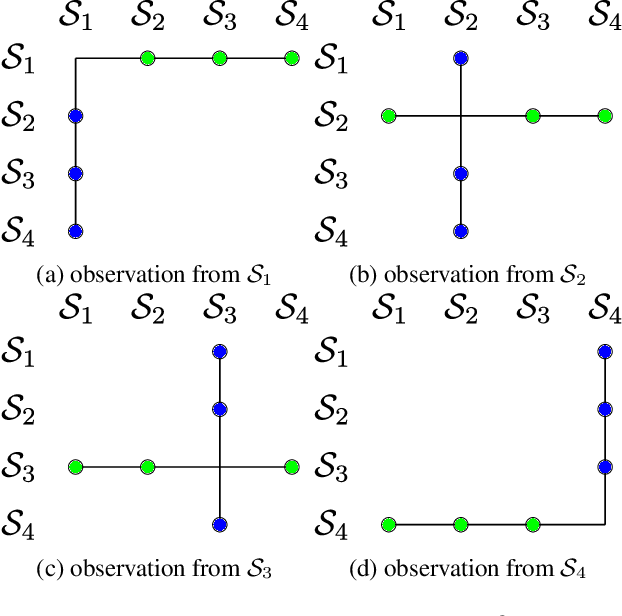

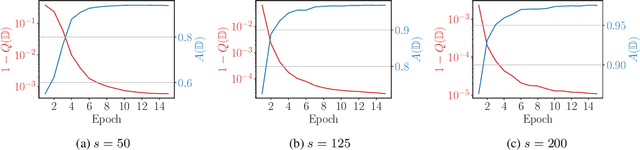
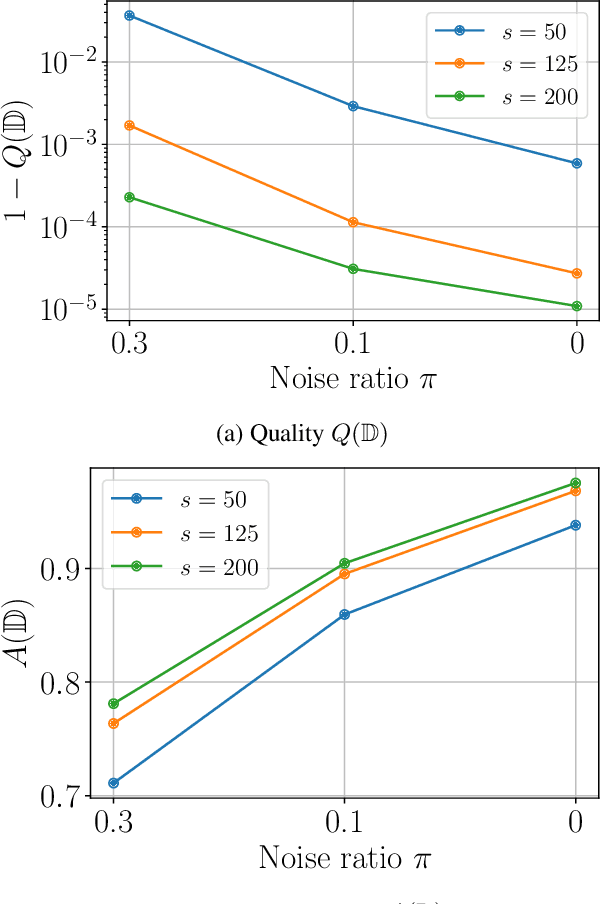
We consider the initial situation where a dataset has been over-partitioned into $k$ clusters and seek a domain independent way to merge those initial clusters. We identify the total variation distance (TVD) as suitable for this goal. By exploiting the relation of the TVD to the Bayes accuracy we show how neural networks can be used to estimate TVDs between all pairs of clusters in parallel. Crucially, the needed memory space is decreased by reducing the required number of output neurons from $k^2$ to $k$. On realistically obtained over-clusterings of ImageNet subsets it is demonstrated that our TVD estimates lead to better merge decisions than those obtained by relying on state-of-the-art unsupervised representations. Further the generality of the approach is verified by evaluating it on a a point cloud dataset.