 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEulerian Gaussian Splatting using Hashed Probability Pyramids
May 27, 2026We introduce a probabilistic splat-based radiance field framework that retains the fast rasterization and test-time efficiency of 3D Gaussian Splatting (3DGS) while replacing heuristic primitive manipulation with gradient-based optimization of a volumetric probability density. Rather than relocating, splitting, or culling Gaussians via hand-tuned densification (e.g., ADC), we treat primitive locations as samples drawn from a persistent, learnable density. We instantiate this density using a novel, memory-efficient multi-scale hierarchical grid that enables end-to-end gradient-based optimization. To stabilize the optimization, we derive an unbiased gradient estimator with control variates that markedly reduces variance. By allowing probability mass to flow to where the loss demands, our framework eliminates brittle priors and naturally explores the volume, achieving state-of-the-art reconstruction quality on mip-NeRF 360 while preserving 3DGS-level rendering speed.
Fourier Feature Pyramids for Physics-Informed Neural Networks
May 22, 2026We present an improved neural field architecture for solving partial differential equations (PDEs). Current physics-informed neural networks (PINNs) provide a flexible framework for solving PDEs, but they struggle to achieve highly accurate solutions and require computation that scales poorly with parameter count. Our model, which we call beignet (Bandlimited Embedding with Interpolated Grid Network), replaces the random Fourier feature embedding used by existing PINN models with a trainable multi-resolution Fourier feature pyramid. To query beignet at a continuous coordinate, we use Fourier interpolation at each level of the pyramid to return features at the input coordinate, and then decode this vector with a fully-connected neural network trunk. Our model provides multiple benefits: 1) Spatial derivatives can be computed efficiently by using the chain rule to compose derivatives of the neural network computed with automatic differentiation with derivatives of the feature grid computed spectrally by the Fast Fourier transform (FFT). 2) beignet can achieve higher accuracy in a compute-efficient manner by scaling the parameter count of this Fourier feature pyramid, instead of the less-efficient strategy of scaling the neural network architecture. 3) beignet can directly control the representation bandlimit, resulting in more stable optimization for difficult PDEs. We demonstrate that beignet finds significantly more accurate solutions on PDE benchmarks using fewer parameters than state-of-the-art PINN methods. We further evaluate beignet on the self-similar inviscid Burgers blowup problem and show that it can minimize residuals to near machine precision using Adam, an accuracy regime previously attained only by using computationally expensive higher-order optimizers.
Power Foam: Unifying Real-Time Differentiable Ray Tracing and Rasterization
Apr 27, 2026We introduce a differentiable 3D representation that unifies the ray tracing capabilities of foam-based ray tracing with the efficiency of modern rasterization pipelines. While prior foam representations enable constant-time ray traversal through an explicit volumetric partition of space, their potentially unbounded cells hinder efficient tile-based rasterization. We address this limitation by generalizing Voronoi foams to bounded power diagrams with controllable cell extents, enabling spatially bounded primitives without requiring expensive Delaunay triangulations during training. We further introduce an oriented surface formulation that explicitly models interfaces between interior and exterior regions, and decouple geometry from appearance by embedding differentiable texture directly on these surfaces. Together, these contributions yield a representation that preserves state-of-the-art ray tracing efficiency while achieving rasterization performance competitive with current generation 3DGS, providing a practical path toward unified real-time differentiable rendering.
GR3EN: Generative Relighting for 3D Environments
Jan 22, 2026We present a method for relighting 3D reconstructions of large room-scale environments. Existing solutions for 3D scene relighting often require solving under-determined or ill-conditioned inverse rendering problems, and are as such unable to produce high-quality results on complex real-world scenes. Though recent progress in using generative image and video diffusion models for relighting has been promising, these techniques are either limited to 2D image and video relighting or 3D relighting of individual objects. Our approach enables controllable 3D relighting of room-scale scenes by distilling the outputs of a video-to-video relighting diffusion model into a 3D reconstruction. This side-steps the need to solve a difficult inverse rendering problem, and results in a flexible system that can relight 3D reconstructions of complex real-world scenes. We validate our approach on both synthetic and real-world datasets to show that it can faithfully render novel views of scenes under new lighting conditions.
Spherical Voronoi: Directional Appearance as a Differentiable Partition of the Sphere
Dec 16, 2025
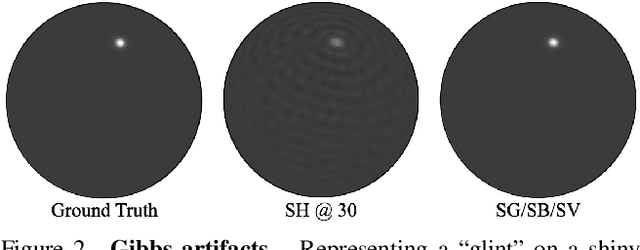
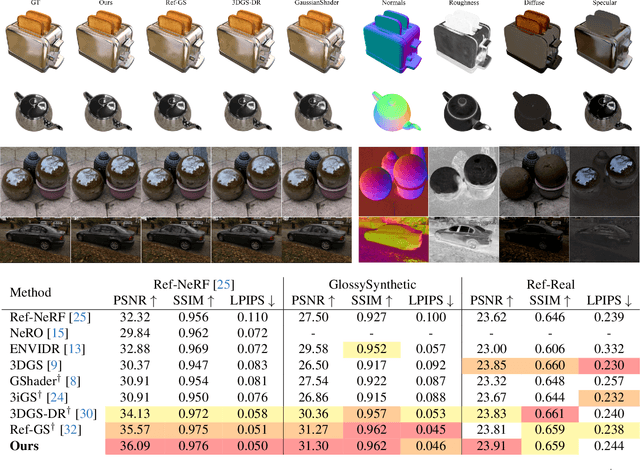
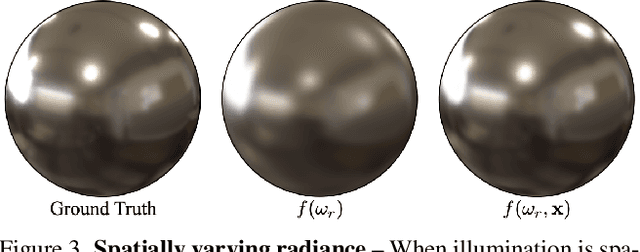
Radiance field methods (e.g. 3D Gaussian Splatting) have emerged as a powerful paradigm for novel view synthesis, yet their appearance modeling often relies on Spherical Harmonics (SH), which impose fundamental limitations. SH struggle with high-frequency signals, exhibit Gibbs ringing artifacts, and fail to capture specular reflections - a key component of realistic rendering. Although alternatives like spherical Gaussians offer improvements, they add significant optimization complexity. We propose Spherical Voronoi (SV) as a unified framework for appearance representation in 3D Gaussian Splatting. SV partitions the directional domain into learnable regions with smooth boundaries, providing an intuitive and stable parameterization for view-dependent effects. For diffuse appearance, SV achieves competitive results while keeping optimization simpler than existing alternatives. For reflections - where SH fail - we leverage SV as learnable reflection probes, taking reflected directions as input following principles from classical graphics. This formulation attains state-of-the-art results on synthetic and real-world datasets, demonstrating that SV offers a principled, efficient, and general solution for appearance modeling in explicit 3D representations.
Generative Multiview Relighting for 3D Reconstruction under Extreme Illumination Variation
Dec 19, 2024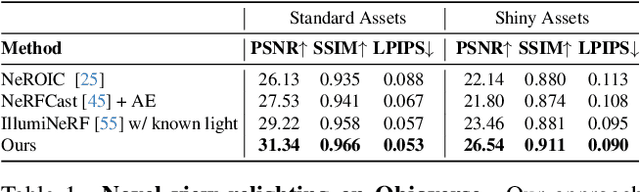
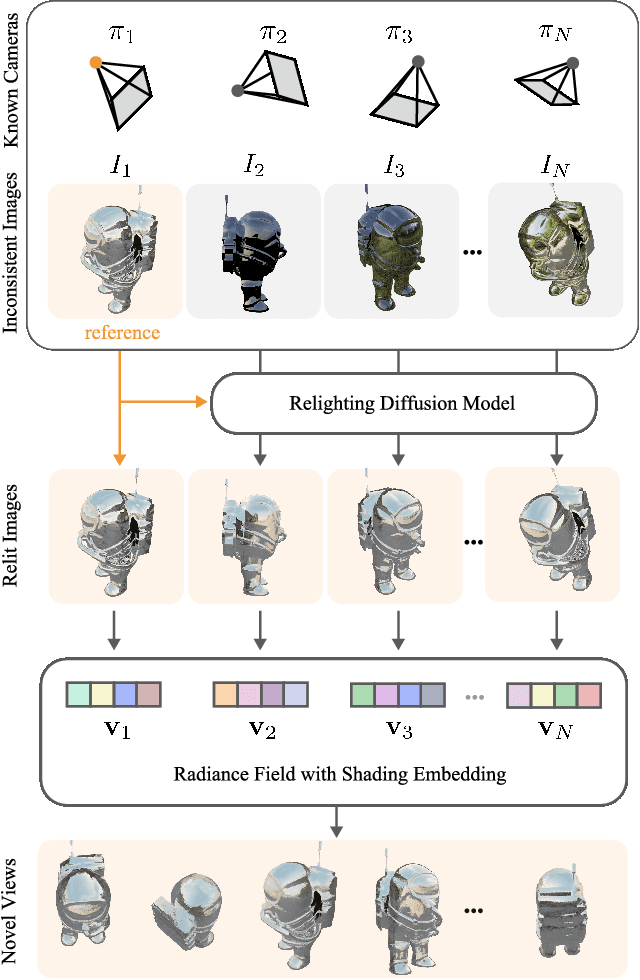
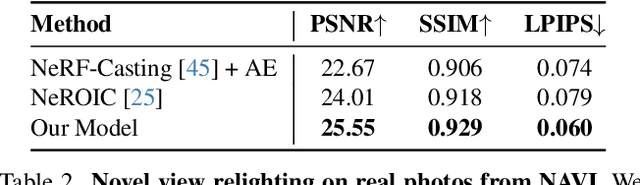

Reconstructing the geometry and appearance of objects from photographs taken in different environments is difficult as the illumination and therefore the object appearance vary across captured images. This is particularly challenging for more specular objects whose appearance strongly depends on the viewing direction. Some prior approaches model appearance variation across images using a per-image embedding vector, while others use physically-based rendering to recover the materials and per-image illumination. Such approaches fail at faithfully recovering view-dependent appearance given significant variation in input illumination and tend to produce mostly diffuse results. We present an approach that reconstructs objects from images taken under different illuminations by first relighting the images under a single reference illumination with a multiview relighting diffusion model and then reconstructing the object's geometry and appearance with a radiance field architecture that is robust to the small remaining inconsistencies among the relit images. We validate our proposed approach on both synthetic and real datasets and demonstrate that it greatly outperforms existing techniques at reconstructing high-fidelity appearance from images taken under extreme illumination variation. Moreover, our approach is particularly effective at recovering view-dependent "shiny" appearance which cannot be reconstructed by prior methods.
SimVS: Simulating World Inconsistencies for Robust View Synthesis
Dec 10, 2024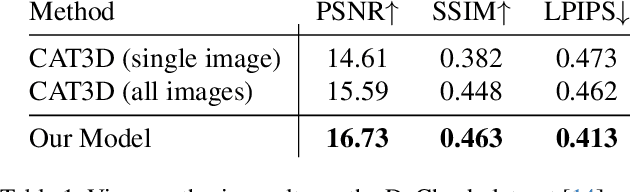



Novel-view synthesis techniques achieve impressive results for static scenes but struggle when faced with the inconsistencies inherent to casual capture settings: varying illumination, scene motion, and other unintended effects that are difficult to model explicitly. We present an approach for leveraging generative video models to simulate the inconsistencies in the world that can occur during capture. We use this process, along with existing multi-view datasets, to create synthetic data for training a multi-view harmonization network that is able to reconcile inconsistent observations into a consistent 3D scene. We demonstrate that our world-simulation strategy significantly outperforms traditional augmentation methods in handling real-world scene variations, thereby enabling highly accurate static 3D reconstructions in the presence of a variety of challenging inconsistencies. Project page: https://alextrevithick.github.io/simvs
EVER: Exact Volumetric Ellipsoid Rendering for Real-time View Synthesis
Oct 02, 2024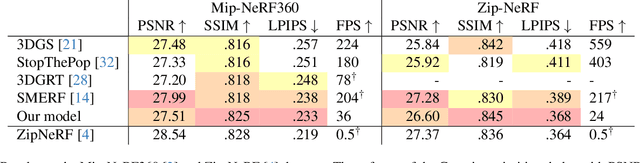
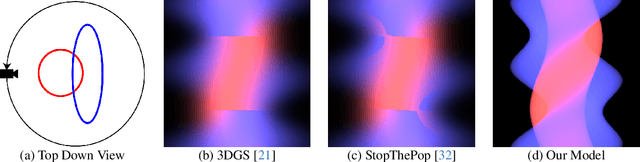
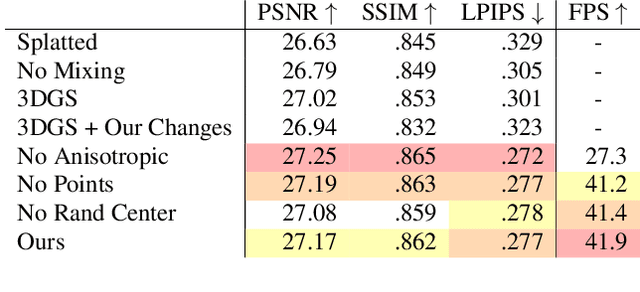
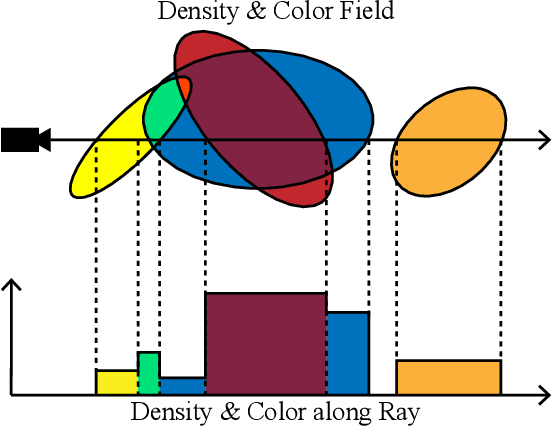
We present Exact Volumetric Ellipsoid Rendering (EVER), a method for real-time differentiable emission-only volume rendering. Unlike recent rasterization based approach by 3D Gaussian Splatting (3DGS), our primitive based representation allows for exact volume rendering, rather than alpha compositing 3D Gaussian billboards. As such, unlike 3DGS our formulation does not suffer from popping artifacts and view dependent density, but still achieves frame rates of $\sim\!30$ FPS at 720p on an NVIDIA RTX4090. Since our approach is built upon ray tracing it enables effects such as defocus blur and camera distortion (e.g. such as from fisheye cameras), which are difficult to achieve by rasterization. We show that our method is more accurate with fewer blending issues than 3DGS and follow-up work on view-consistent rendering, especially on the challenging large-scale scenes from the Zip-NeRF dataset where it achieves sharpest results among real-time techniques.
Flash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Sep 09, 2024State-of-the-art techniques for 3D reconstruction are largely based on volumetric scene representations, which require sampling multiple points to compute the color arriving along a ray. Using these representations for more general inverse rendering -- reconstructing geometry, materials, and lighting from observed images -- is challenging because recursively path-tracing such volumetric representations is expensive. Recent works alleviate this issue through the use of radiance caches: data structures that store the steady-state, infinite-bounce radiance arriving at any point from any direction. However, these solutions rely on approximations that introduce bias into the renderings and, more importantly, into the gradients used for optimization. We present a method that avoids these approximations while remaining computationally efficient. In particular, we leverage two techniques to reduce variance for unbiased estimators of the rendering equation: (1) an occlusion-aware importance sampler for incoming illumination and (2) a fast cache architecture that can be used as a control variate for the radiance from a high-quality, but more expensive, volumetric cache. We show that by removing these biases our approach improves the generality of radiance cache based inverse rendering, as well as increasing quality in the presence of challenging light transport effects such as specular reflections.
IllumiNeRF: 3D Relighting without Inverse Rendering
Jun 10, 2024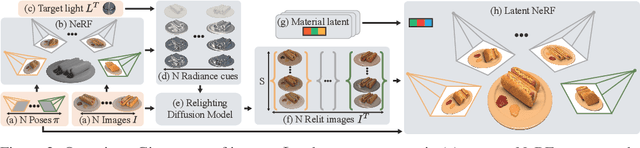



Existing methods for relightable view synthesis -- using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination -- are based on inverse rendering, and attempt to disentangle the object geometry, materials, and lighting that explain the input images. Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally-expensive. In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on lighting and then reconstruct a Neural Radiance Field (NeRF) with these relit images, from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks. Please see our project page at https://illuminerf.github.io/.