 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDark3R: Learning Structure from Motion in the Dark
Mar 05, 2026We introduce Dark3R, a framework for structure from motion in the dark that operates directly on raw images with signal-to-noise ratios (SNRs) below $-4$ dB -- a regime where conventional feature- and learning-based methods break down. Our key insight is to adapt large-scale 3D foundation models to extreme low-light conditions through a teacher--student distillation process, enabling robust feature matching and camera pose estimation in low light. Dark3R requires no 3D supervision; it is trained solely on noisy--clean raw image pairs, which can be either captured directly or synthesized using a simple Poisson--Gaussian noise model applied to well-exposed raw images. To train and evaluate our approach, we introduce a new, exposure-bracketed dataset that includes $\sim$42,000 multi-view raw images with ground-truth 3D annotations, and we demonstrate that Dark3R achieves state-of-the-art structure from motion in the low-SNR regime. Further, we demonstrate state-of-the-art novel view synthesis in the dark using Dark3R's predicted poses and a coarse-to-fine radiance field optimization procedure.
Neural Inverse Rendering from Propagating Light
Jun 05, 2025We present the first system for physically based, neural inverse rendering from multi-viewpoint videos of propagating light. Our approach relies on a time-resolved extension of neural radiance caching -- a technique that accelerates inverse rendering by storing infinite-bounce radiance arriving at any point from any direction. The resulting model accurately accounts for direct and indirect light transport effects and, when applied to captured measurements from a flash lidar system, enables state-of-the-art 3D reconstruction in the presence of strong indirect light. Further, we demonstrate view synthesis of propagating light, automatic decomposition of captured measurements into direct and indirect components, as well as novel capabilities such as multi-view time-resolved relighting of captured scenes.
Flash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Sep 09, 2024State-of-the-art techniques for 3D reconstruction are largely based on volumetric scene representations, which require sampling multiple points to compute the color arriving along a ray. Using these representations for more general inverse rendering -- reconstructing geometry, materials, and lighting from observed images -- is challenging because recursively path-tracing such volumetric representations is expensive. Recent works alleviate this issue through the use of radiance caches: data structures that store the steady-state, infinite-bounce radiance arriving at any point from any direction. However, these solutions rely on approximations that introduce bias into the renderings and, more importantly, into the gradients used for optimization. We present a method that avoids these approximations while remaining computationally efficient. In particular, we leverage two techniques to reduce variance for unbiased estimators of the rendering equation: (1) an occlusion-aware importance sampler for incoming illumination and (2) a fast cache architecture that can be used as a control variate for the radiance from a high-quality, but more expensive, volumetric cache. We show that by removing these biases our approach improves the generality of radiance cache based inverse rendering, as well as increasing quality in the presence of challenging light transport effects such as specular reflections.
NeRF-Casting: Improved View-Dependent Appearance with Consistent Reflections
May 23, 2024

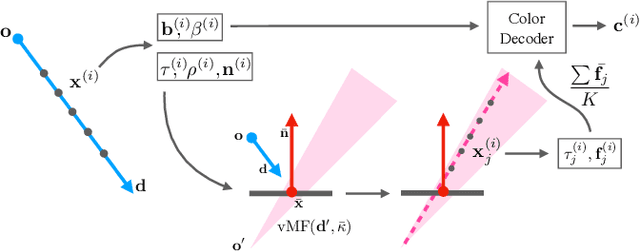

Neural Radiance Fields (NeRFs) typically struggle to reconstruct and render highly specular objects, whose appearance varies quickly with changes in viewpoint. Recent works have improved NeRF's ability to render detailed specular appearance of distant environment illumination, but are unable to synthesize consistent reflections of closer content. Moreover, these techniques rely on large computationally-expensive neural networks to model outgoing radiance, which severely limits optimization and rendering speed. We address these issues with an approach based on ray tracing: instead of querying an expensive neural network for the outgoing view-dependent radiance at points along each camera ray, our model casts reflection rays from these points and traces them through the NeRF representation to render feature vectors which are decoded into color using a small inexpensive network. We demonstrate that our model outperforms prior methods for view synthesis of scenes containing shiny objects, and that it is the only existing NeRF method that can synthesize photorealistic specular appearance and reflections in real-world scenes, while requiring comparable optimization time to current state-of-the-art view synthesis models.
HyperReel: High-Fidelity 6-DoF Video with Ray-Conditioned Sampling
Jan 05, 2023Volumetric scene representations enable photorealistic view synthesis for static scenes and form the basis of several existing 6-DoF video techniques. However, the volume rendering procedures that drive these representations necessitate careful trade-offs in terms of quality, rendering speed, and memory efficiency. In particular, existing methods fail to simultaneously achieve real-time performance, small memory footprint, and high-quality rendering for challenging real-world scenes. To address these issues, we present HyperReel -- a novel 6-DoF video representation. The two core components of HyperReel are: (1) a ray-conditioned sample prediction network that enables high-fidelity, high frame rate rendering at high resolutions and (2) a compact and memory efficient dynamic volume representation. Our 6-DoF video pipeline achieves the best performance compared to prior and contemporary approaches in terms of visual quality with small memory requirements, while also rendering at up to 18 frames-per-second at megapixel resolution without any custom CUDA code.
Learning Neural Light Fields with Ray-Space Embedding Networks
Dec 06, 2021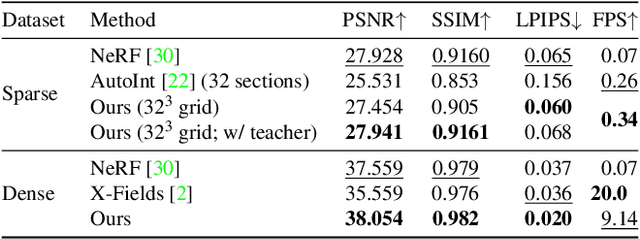
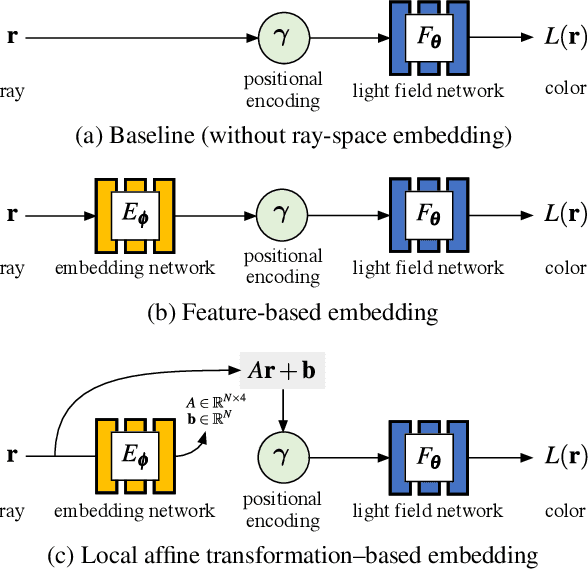

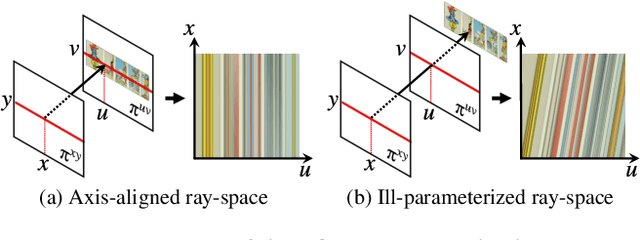
Neural radiance fields (NeRFs) produce state-of-the-art view synthesis results. However, they are slow to render, requiring hundreds of network evaluations per pixel to approximate a volume rendering integral. Baking NeRFs into explicit data structures enables efficient rendering, but results in a large increase in memory footprint and, in many cases, a quality reduction. In this paper, we propose a novel neural light field representation that, in contrast, is compact and directly predicts integrated radiance along rays. Our method supports rendering with a single network evaluation per pixel for small baseline light field datasets and can also be applied to larger baselines with only a few evaluations per pixel. At the core of our approach is a ray-space embedding network that maps the 4D ray-space manifold into an intermediate, interpolable latent space. Our method achieves state-of-the-art quality on dense forward-facing datasets such as the Stanford Light Field dataset. In addition, for forward-facing scenes with sparser inputs we achieve results that are competitive with NeRF-based approaches in terms of quality while providing a better speed/quality/memory trade-off with far fewer network evaluations.
TöRF: Time-of-Flight Radiance Fields for Dynamic Scene View Synthesis
Sep 30, 2021
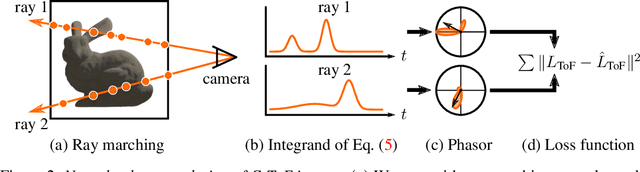
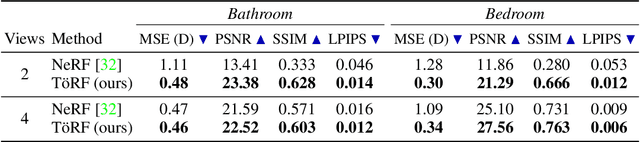
Neural networks can represent and accurately reconstruct radiance fields for static 3D scenes (e.g., NeRF). Several works extend these to dynamic scenes captured with monocular video, with promising performance. However, the monocular setting is known to be an under-constrained problem, and so methods rely on data-driven priors for reconstructing dynamic content. We replace these priors with measurements from a time-of-flight (ToF) camera, and introduce a neural representation based on an image formation model for continuous-wave ToF cameras. Instead of working with processed depth maps, we model the raw ToF sensor measurements to improve reconstruction quality and avoid issues with low reflectance regions, multi-path interference, and a sensor's limited unambiguous depth range. We show that this approach improves robustness of dynamic scene reconstruction to erroneous calibration and large motions, and discuss the benefits and limitations of integrating RGB+ToF sensors that are now available on modern smartphones.
MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
Aug 14, 2020We introduce a method to convert stereo 360{\deg} (omnidirectional stereo) imagery into a layered, multi-sphere image representation for six degree-of-freedom (6DoF) rendering. Stereo 360{\deg} imagery can be captured from multi-camera systems for virtual reality (VR), but lacks motion parallax and correct-in-all-directions disparity cues. Together, these can quickly lead to VR sickness when viewing content. One solution is to try and generate a format suitable for 6DoF rendering, such as by estimating depth. However, this raises questions as to how to handle disoccluded regions in dynamic scenes. Our approach is to simultaneously learn depth and disocclusions via a multi-sphere image representation, which can be rendered with correct 6DoF disparity and motion parallax in VR. This significantly improves comfort for the viewer, and can be inferred and rendered in real time on modern GPU hardware. Together, these move towards making VR video a more comfortable immersive medium.