 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-Flow: Transforming Text to Audio-Visual Human-like Interactions
Feb 18, 2025We introduce AV-Flow, an audio-visual generative model that animates photo-realistic 4D talking avatars given only text input. In contrast to prior work that assumes an existing speech signal, we synthesize speech and vision jointly. We demonstrate human-like speech synthesis, synchronized lip motion, lively facial expressions and head pose; all generated from just text characters. The core premise of our approach lies in the architecture of our two parallel diffusion transformers. Intermediate highway connections ensure communication between the audio and visual modalities, and thus, synchronized speech intonation and facial dynamics (e.g., eyebrow motion). Our model is trained with flow matching, leading to expressive results and fast inference. In case of dyadic conversations, AV-Flow produces an always-on avatar, that actively listens and reacts to the audio-visual input of a user. Through extensive experiments, we show that our method outperforms prior work, synthesizing natural-looking 4D talking avatars. Project page: https://aggelinacha.github.io/AV-Flow/
Relightable Full-Body Gaussian Codec Avatars
Jan 24, 2025



We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.
A Local Appearance Model for Volumetric Capture of Diverse Hairstyle
Dec 14, 2023



Hair plays a significant role in personal identity and appearance, making it an essential component of high-quality, photorealistic avatars. Existing approaches either focus on modeling the facial region only or rely on personalized models, limiting their generalizability and scalability. In this paper, we present a novel method for creating high-fidelity avatars with diverse hairstyles. Our method leverages the local similarity across different hairstyles and learns a universal hair appearance prior from multi-view captures of hundreds of people. This prior model takes 3D-aligned features as input and generates dense radiance fields conditioned on a sparse point cloud with color. As our model splits different hairstyles into local primitives and builds prior at that level, it is capable of handling various hair topologies. Through experiments, we demonstrate that our model captures a diverse range of hairstyles and generalizes well to challenging new hairstyles. Empirical results show that our method improves the state-of-the-art approaches in capturing and generating photorealistic, personalized avatars with complete hair.
SceNeRFlow: Time-Consistent Reconstruction of General Dynamic Scenes
Aug 16, 2023



Existing methods for the 4D reconstruction of general, non-rigidly deforming objects focus on novel-view synthesis and neglect correspondences. However, time consistency enables advanced downstream tasks like 3D editing, motion analysis, or virtual-asset creation. We propose SceNeRFlow to reconstruct a general, non-rigid scene in a time-consistent manner. Our dynamic-NeRF method takes multi-view RGB videos and background images from static cameras with known camera parameters as input. It then reconstructs the deformations of an estimated canonical model of the geometry and appearance in an online fashion. Since this canonical model is time-invariant, we obtain correspondences even for long-term, long-range motions. We employ neural scene representations to parametrize the components of our method. Like prior dynamic-NeRF methods, we use a backwards deformation model. We find non-trivial adaptations of this model necessary to handle larger motions: We decompose the deformations into a strongly regularized coarse component and a weakly regularized fine component, where the coarse component also extends the deformation field into the space surrounding the object, which enables tracking over time. We show experimentally that, unlike prior work that only handles small motion, our method enables the reconstruction of studio-scale motions.
HyperReel: High-Fidelity 6-DoF Video with Ray-Conditioned Sampling
Jan 05, 2023Volumetric scene representations enable photorealistic view synthesis for static scenes and form the basis of several existing 6-DoF video techniques. However, the volume rendering procedures that drive these representations necessitate careful trade-offs in terms of quality, rendering speed, and memory efficiency. In particular, existing methods fail to simultaneously achieve real-time performance, small memory footprint, and high-quality rendering for challenging real-world scenes. To address these issues, we present HyperReel -- a novel 6-DoF video representation. The two core components of HyperReel are: (1) a ray-conditioned sample prediction network that enables high-fidelity, high frame rate rendering at high resolutions and (2) a compact and memory efficient dynamic volume representation. Our 6-DoF video pipeline achieves the best performance compared to prior and contemporary approaches in terms of visual quality with small memory requirements, while also rendering at up to 18 frames-per-second at megapixel resolution without any custom CUDA code.
NeuWigs: A Neural Dynamic Model for Volumetric Hair Capture and Animation
Dec 08, 2022



The capture and animation of human hair are two of the major challenges in the creation of realistic avatars for the virtual reality. Both problems are highly challenging, because hair has complex geometry and appearance, as well as exhibits challenging motion. In this paper, we present a two-stage approach that models hair independently from the head to address these challenges in a data-driven manner. The first stage, state compression, learns a low-dimensional latent space of 3D hair states containing motion and appearance, via a novel autoencoder-as-a-tracker strategy. To better disentangle the hair and head in appearance learning, we employ multi-view hair segmentation masks in combination with a differentiable volumetric renderer. The second stage learns a novel hair dynamics model that performs temporal hair transfer based on the discovered latent codes. To enforce higher stability while driving our dynamics model, we employ the 3D point-cloud autoencoder from the compression stage for de-noising of the hair state. Our model outperforms the state of the art in novel view synthesis and is capable of creating novel hair animations without having to rely on hair observations as a driving signal. Project page is here https://ziyanw1.github.io/neuwigs/.
Neural Pixel Composition: 3D-4D View Synthesis from Multi-Views
Jul 21, 2022
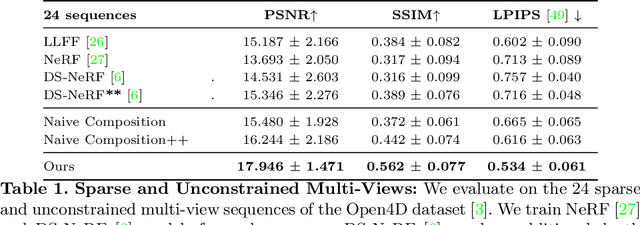
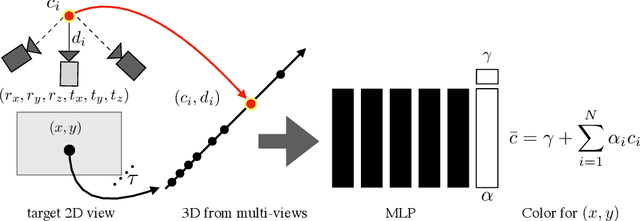
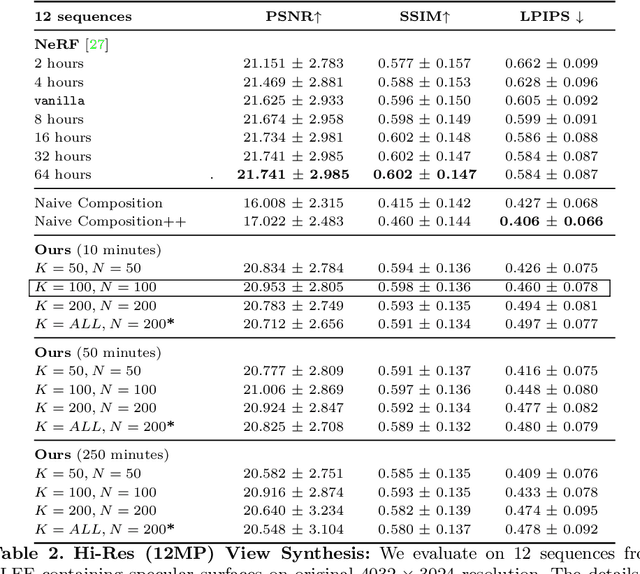
We present Neural Pixel Composition (NPC), a novel approach for continuous 3D-4D view synthesis given only a discrete set of multi-view observations as input. Existing state-of-the-art approaches require dense multi-view supervision and an extensive computational budget. The proposed formulation reliably operates on sparse and wide-baseline multi-view imagery and can be trained efficiently within a few seconds to 10 minutes for hi-res (12MP) content, i.e., 200-400X faster convergence than existing methods. Crucial to our approach are two core novelties: 1) a representation of a pixel that contains color and depth information accumulated from multi-views for a particular location and time along a line of sight, and 2) a multi-layer perceptron (MLP) that enables the composition of this rich information provided for a pixel location to obtain the final color output. We experiment with a large variety of multi-view sequences, compare to existing approaches, and achieve better results in diverse and challenging settings. Finally, our approach enables dense 3D reconstruction from sparse multi-views, where COLMAP, a state-of-the-art 3D reconstruction approach, struggles.
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints
May 10, 2022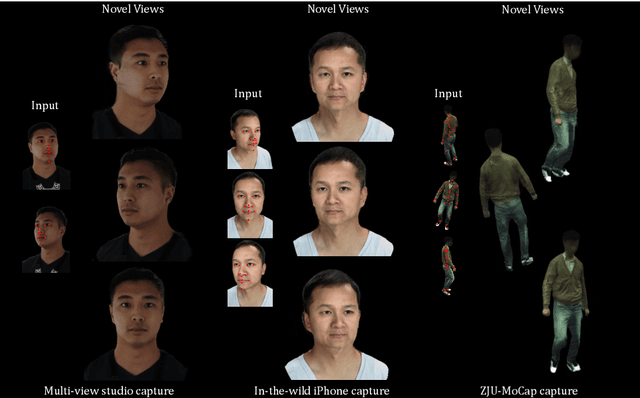

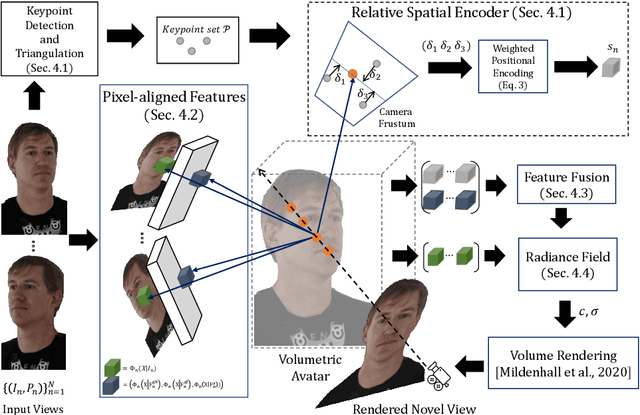
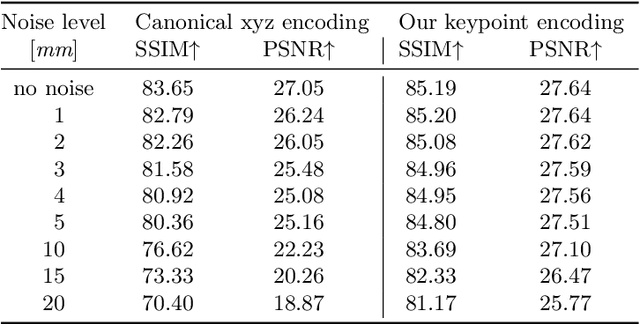
Image-based volumetric avatars using pixel-aligned features promise generalization to unseen poses and identities. Prior work leverages global spatial encodings and multi-view geometric consistency to reduce spatial ambiguity. However, global encodings often suffer from overfitting to the distribution of the training data, and it is difficult to learn multi-view consistent reconstruction from sparse views. In this work, we investigate common issues with existing spatial encodings and propose a simple yet highly effective approach to modeling high-fidelity volumetric avatars from sparse views. One of the key ideas is to encode relative spatial 3D information via sparse 3D keypoints. This approach is robust to the sparsity of viewpoints and cross-dataset domain gap. Our approach outperforms state-of-the-art methods for head reconstruction. On human body reconstruction for unseen subjects, we also achieve performance comparable to prior work that uses a parametric human body model and temporal feature aggregation. Our experiments show that a majority of errors in prior work stem from an inappropriate choice of spatial encoding and thus we suggest a new direction for high-fidelity image-based avatar modeling. https://markomih.github.io/KeypointNeRF
COAP: Compositional Articulated Occupancy of People
Apr 13, 2022
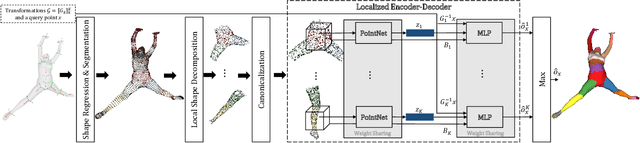
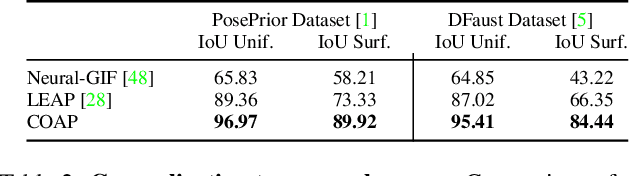
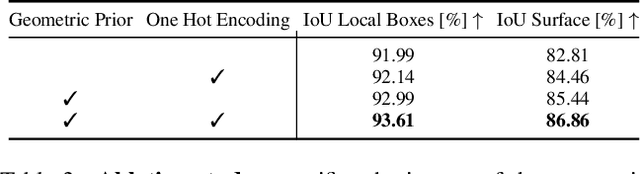
We present a novel neural implicit representation for articulated human bodies. Compared to explicit template meshes, neural implicit body representations provide an efficient mechanism for modeling interactions with the environment, which is essential for human motion reconstruction and synthesis in 3D scenes. However, existing neural implicit bodies suffer from either poor generalization on highly articulated poses or slow inference time. In this work, we observe that prior knowledge about the human body's shape and kinematic structure can be leveraged to improve generalization and efficiency. We decompose the full-body geometry into local body parts and employ a part-aware encoder-decoder architecture to learn neural articulated occupancy that models complex deformations locally. Our local shape encoder represents the body deformation of not only the corresponding body part but also the neighboring body parts. The decoder incorporates the geometric constraints of local body shape which significantly improves pose generalization. We demonstrate that our model is suitable for resolving self-intersections and collisions with 3D environments. Quantitative and qualitative experiments show that our method largely outperforms existing solutions in terms of both efficiency and accuracy. The code and models are available at https://neuralbodies.github.io/COAP/index.html
iSDF: Real-Time Neural Signed Distance Fields for Robot Perception
Apr 05, 2022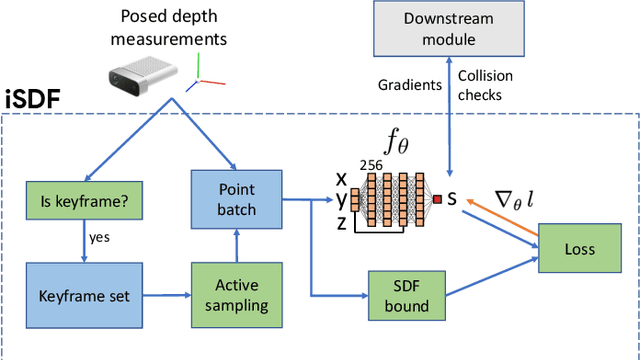
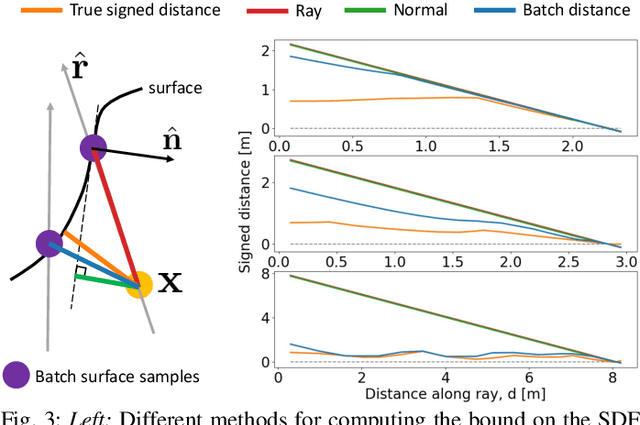
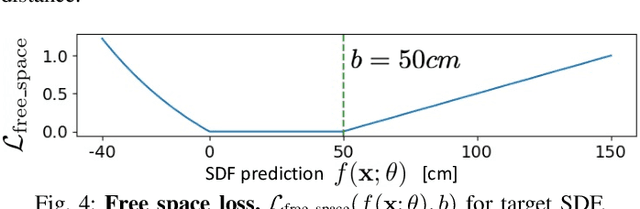
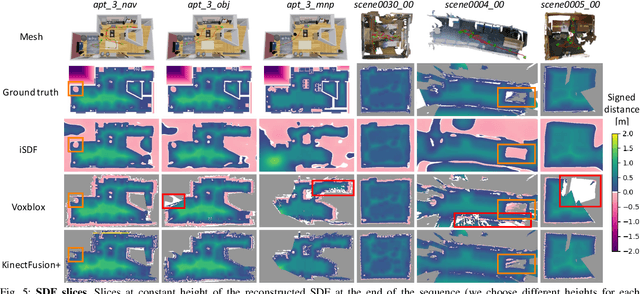
We present iSDF, a continual learning system for real-time signed distance field (SDF) reconstruction. Given a stream of posed depth images from a moving camera, it trains a randomly initialised neural network to map input 3D coordinate to approximate signed distance. The model is self-supervised by minimising a loss that bounds the predicted signed distance using the distance to the closest sampled point in a batch of query points that are actively sampled. In contrast to prior work based on voxel grids, our neural method is able to provide adaptive levels of detail with plausible filling in of partially observed regions and denoising of observations, all while having a more compact representation. In evaluations against alternative methods on real and synthetic datasets of indoor environments, we find that iSDF produces more accurate reconstructions, and better approximations of collision costs and gradients useful for downstream planners in domains from navigation to manipulation. Code and video results can be found at our project page: https://joeaortiz.github.io/iSDF/ .