 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-Flow: Transforming Text to Audio-Visual Human-like Interactions
Feb 18, 2025We introduce AV-Flow, an audio-visual generative model that animates photo-realistic 4D talking avatars given only text input. In contrast to prior work that assumes an existing speech signal, we synthesize speech and vision jointly. We demonstrate human-like speech synthesis, synchronized lip motion, lively facial expressions and head pose; all generated from just text characters. The core premise of our approach lies in the architecture of our two parallel diffusion transformers. Intermediate highway connections ensure communication between the audio and visual modalities, and thus, synchronized speech intonation and facial dynamics (e.g., eyebrow motion). Our model is trained with flow matching, leading to expressive results and fast inference. In case of dyadic conversations, AV-Flow produces an always-on avatar, that actively listens and reacts to the audio-visual input of a user. Through extensive experiments, we show that our method outperforms prior work, synthesizing natural-looking 4D talking avatars. Project page: https://aggelinacha.github.io/AV-Flow/
TalkinNeRF: Animatable Neural Fields for Full-Body Talking Humans
Sep 25, 2024



We introduce a novel framework that learns a dynamic neural radiance field (NeRF) for full-body talking humans from monocular videos. Prior work represents only the body pose or the face. However, humans communicate with their full body, combining body pose, hand gestures, as well as facial expressions. In this work, we propose TalkinNeRF, a unified NeRF-based network that represents the holistic 4D human motion. Given a monocular video of a subject, we learn corresponding modules for the body, face, and hands, that are combined together to generate the final result. To capture complex finger articulation, we learn an additional deformation field for the hands. Our multi-identity representation enables simultaneous training for multiple subjects, as well as robust animation under completely unseen poses. It can also generalize to novel identities, given only a short video as input. We demonstrate state-of-the-art performance for animating full-body talking humans, with fine-grained hand articulation and facial expressions.
JEAN: Joint Expression and Audio-guided NeRF-based Talking Face Generation
Sep 18, 2024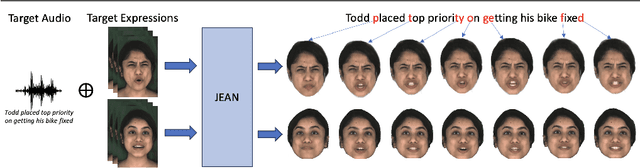
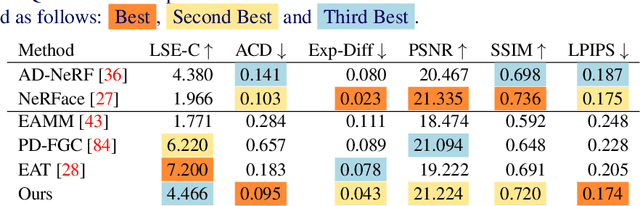
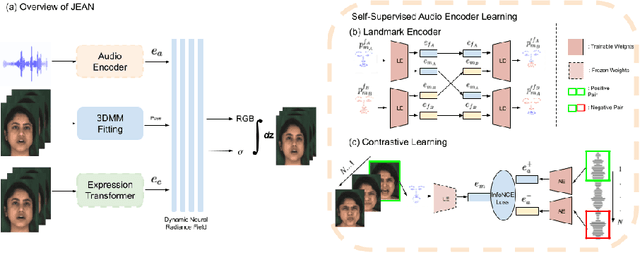

We introduce a novel method for joint expression and audio-guided talking face generation. Recent approaches either struggle to preserve the speaker identity or fail to produce faithful facial expressions. To address these challenges, we propose a NeRF-based network. Since we train our network on monocular videos without any ground truth, it is essential to learn disentangled representations for audio and expression. We first learn audio features in a self-supervised manner, given utterances from multiple subjects. By incorporating a contrastive learning technique, we ensure that the learned audio features are aligned to the lip motion and disentangled from the muscle motion of the rest of the face. We then devise a transformer-based architecture that learns expression features, capturing long-range facial expressions and disentangling them from the speech-specific mouth movements. Through quantitative and qualitative evaluation, we demonstrate that our method can synthesize high-fidelity talking face videos, achieving state-of-the-art facial expression transfer along with lip synchronization to unseen audio.
MIGS: Multi-Identity Gaussian Splatting via Tensor Decomposition
Jul 10, 2024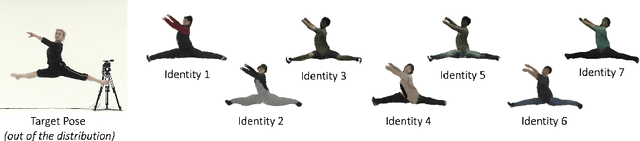

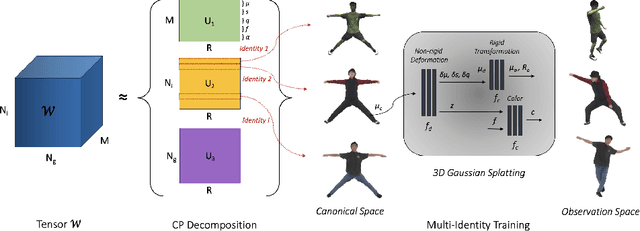

We introduce MIGS (Multi-Identity Gaussian Splatting), a novel method that learns a single neural representation for multiple identities, using only monocular videos. Recent 3D Gaussian Splatting (3DGS) approaches for human avatars require per-identity optimization. However, learning a multi-identity representation presents advantages in robustly animating humans under arbitrary poses. We propose to construct a high-order tensor that combines all the learnable 3DGS parameters for all the training identities. By assuming a low-rank structure and factorizing the tensor, we model the complex rigid and non-rigid deformations of multiple subjects in a unified network, significantly reducing the total number of parameters. Our proposed approach leverages information from all the training identities, enabling robust animation under challenging unseen poses, outperforming existing approaches. We also demonstrate how it can be extended to learn unseen identities.
MI-NeRF: Learning a Single Face NeRF from Multiple Identities
Apr 03, 2024



In this work, we introduce a method that learns a single dynamic neural radiance field (NeRF) from monocular talking face videos of multiple identities. NeRFs have shown remarkable results in modeling the 4D dynamics and appearance of human faces. However, they require per-identity optimization. Although recent approaches have proposed techniques to reduce the training and rendering time, increasing the number of identities can be expensive. We introduce MI-NeRF (multi-identity NeRF), a single unified network that models complex non-rigid facial motion for multiple identities, using only monocular videos of arbitrary length. The core premise in our method is to learn the non-linear interactions between identity and non-identity specific information with a multiplicative module. By training on multiple videos simultaneously, MI-NeRF not only reduces the total training time compared to standard single-identity NeRFs, but also demonstrates robustness in synthesizing novel expressions for any input identity. We present results for both facial expression transfer and talking face video synthesis. Our method can be further personalized for a target identity given only a short video.
AVFace: Towards Detailed Audio-Visual 4D Face Reconstruction
May 11, 2023



In this work, we present a multimodal solution to the problem of 4D face reconstruction from monocular videos. 3D face reconstruction from 2D images is an under-constrained problem due to the ambiguity of depth. State-of-the-art methods try to solve this problem by leveraging visual information from a single image or video, whereas 3D mesh animation approaches rely more on audio. However, in most cases (e.g. AR/VR applications), videos include both visual and speech information. We propose AVFace that incorporates both modalities and accurately reconstructs the 4D facial and lip motion of any speaker, without requiring any 3D ground truth for training. A coarse stage estimates the per-frame parameters of a 3D morphable model, followed by a lip refinement, and then a fine stage recovers facial geometric details. Due to the temporal audio and video information captured by transformer-based modules, our method is robust in cases when either modality is insufficient (e.g. face occlusions). Extensive qualitative and quantitative evaluation demonstrates the superiority of our method over the current state-of-the-art.
SIDER: Single-Image Neural Optimization for Facial Geometric Detail Recovery
Aug 11, 2021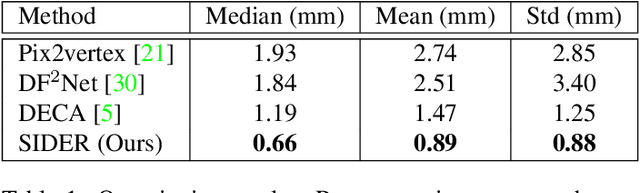
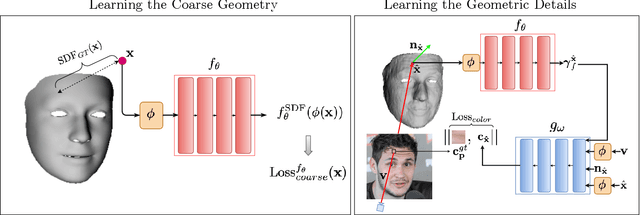


We present SIDER(Single-Image neural optimization for facial geometric DEtail Recovery), a novel photometric optimization method that recovers detailed facial geometry from a single image in an unsupervised manner. Inspired by classical techniques of coarse-to-fine optimization and recent advances in implicit neural representations of 3D shape, SIDER combines a geometry prior based on statistical models and Signed Distance Functions (SDFs) to recover facial details from single images. First, it estimates a coarse geometry using a morphable model represented as an SDF. Next, it reconstructs facial geometry details by optimizing a photometric loss with respect to the ground truth image. In contrast to prior work, SIDER does not rely on any dataset priors and does not require additional supervision from multiple views, lighting changes or ground truth 3D shape. Extensive qualitative and quantitative evaluation demonstrates that our method achieves state-of-the-art on facial geometric detail recovery, using only a single in-the-wild image.