 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Augmented Algorithms for $k$-median via Online Learning
Mar 18, 2026The field of learning-augmented algorithms seeks to use ML techniques on past instances of a problem to inform an algorithm designed for a future instance. In this paper, we introduce a novel model for learning-augmented algorithms inspired by online learning. In this model, we are given a sequence of instances of a problem and the goal of the learning-augmented algorithm is to use prior instances to propose a solution to a future instance of the problem. The performance of the algorithm is measured by its average performance across all the instances, where the performance on a single instance is the ratio between the cost of the algorithm's solution and that of an optimal solution for that instance. We apply this framework to the classic $k$-median clustering problem, and give an efficient learning algorithm that can approximately match the average performance of the best fixed $k$-median solution in hindsight across all the instances. We also experimentally evaluate our algorithm and show that its empirical performance is close to optimal, and also that it automatically adapts the solution to a dynamically changing sequence.
Inference-Time Rethinking with Latent Thought Vectors for Math Reasoning
Feb 06, 2026Standard chain-of-thought reasoning generates a solution in a single forward pass, committing irrevocably to each token and lacking a mechanism to recover from early errors. We introduce Inference-Time Rethinking, a generative framework that enables iterative self-correction by decoupling declarative latent thought vectors from procedural generation. We factorize reasoning into a continuous latent thought vector (what to reason about) and a decoder that verbalizes the trace conditioned on this vector (how to reason). Beyond serving as a declarative buffer, latent thought vectors compress the reasoning structure into a continuous representation that abstracts away surface-level token variability, making gradient-based optimization over reasoning strategies well-posed. Our prior model maps unstructured noise to a learned manifold of valid reasoning patterns, and at test time we employ a Gibbs-style procedure that alternates between generating a candidate trace and optimizing the latent vector to better explain that trace, effectively navigating the latent manifold to refine the reasoning strategy. Training a 0.2B-parameter model from scratch on GSM8K, our method with 30 rethinking iterations surpasses baselines with 10 to 15 times more parameters, including a 3B counterpart. This result demonstrates that effective mathematical reasoning can emerge from sophisticated inference-time computation rather than solely from massive parameter counts.
CASPER: Cross-modal Alignment of Spatial and single-cell Profiles for Expression Recovery
Nov 19, 2025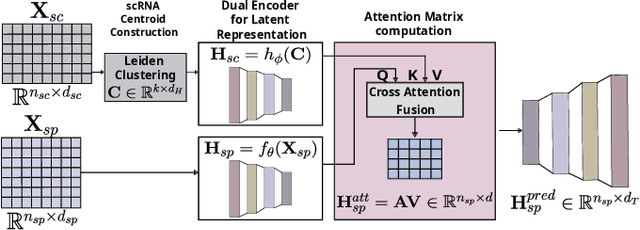
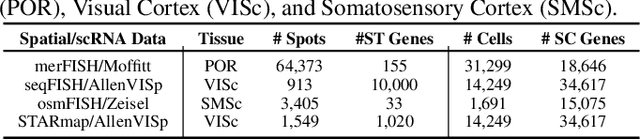
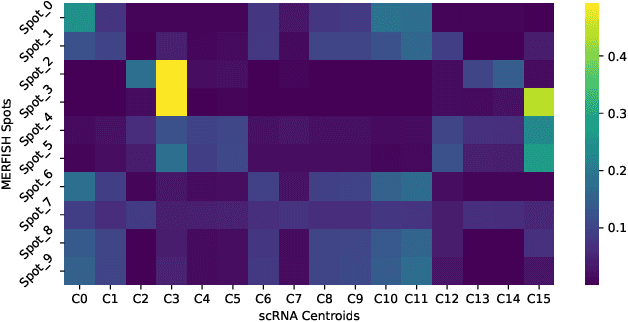
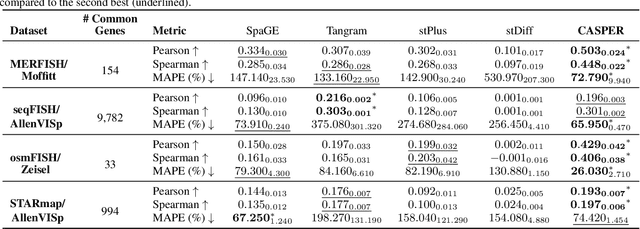
Spatial Transcriptomics enables mapping of gene expression within its native tissue context, but current platforms measure only a limited set of genes due to experimental constraints and excessive costs. To overcome this, computational models integrate Single-Cell RNA Sequencing data with Spatial Transcriptomics to predict unmeasured genes. We propose CASPER, a cross-attention based framework that predicts unmeasured gene expression in Spatial Transcriptomics by leveraging centroid-level representations from Single-Cell RNA Sequencing. We performed rigorous testing over four state-of-the-art Spatial Transcriptomics/Single-Cell RNA Sequencing dataset pairs across four existing baseline models. CASPER shows significant improvement in nine out of the twelve metrics for our experiments. This work paves the way for further work in Spatial Transcriptomics to Single-Cell RNA Sequencing modality translation. The code for CASPER is available at https://github.com/AI4Med-Lab/CASPER.
Haptic-based Complementary Filter for Rigid Body Rotations
Apr 20, 2025The non-commutative nature of 3D rotations poses well-known challenges in generalizing planar problems to three-dimensional ones, even more so in contact-rich tasks where haptic information (i.e., forces/torques) is involved. In this sense, not all learning-based algorithms that are currently available generalize to 3D orientation estimation. Non-linear filters defined on $\mathbf{\mathbb{SO}(3)}$ are widely used with inertial measurement sensors; however, none of them have been used with haptic measurements. This paper presents a unique complementary filtering framework that interprets the geometric shape of objects in the form of superquadrics, exploits the symmetry of $\mathbf{\mathbb{SO}(3)}$, and uses force and vision sensors as measurements to provide an estimate of orientation. The framework's robustness and almost global stability are substantiated by a set of experiments on a dual-arm robotic setup.
CryptoPulse: Short-Term Cryptocurrency Forecasting with Dual-Prediction and Cross-Correlated Market Indicators
Feb 26, 2025



Cryptocurrencies fluctuate in markets with high price volatility, posing significant challenges for investors. To aid in informed decision-making, systems predicting cryptocurrency market movements have been developed, typically focusing on historical patterns. However, these methods often overlook three critical factors influencing market dynamics: 1) the macro investing environment, reflected in major cryptocurrency fluctuations affecting collaborative investor behaviors; 2) overall market sentiment, heavily influenced by news impacting investor strategies; and 3) technical indicators, offering insights into overbought or oversold conditions, momentum, and market trends, which are crucial for short-term price movements. This paper proposes a dual prediction mechanism that forecasts the next day's closing price by incorporating macroeconomic fluctuations, technical indicators, and individual cryptocurrency price changes. Additionally, a novel refinement mechanism enhances predictions through market sentiment-based rescaling and fusion. Experiments demonstrate that the proposed model achieves state-of-the-art performance, consistently outperforming ten comparison methods.
KPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025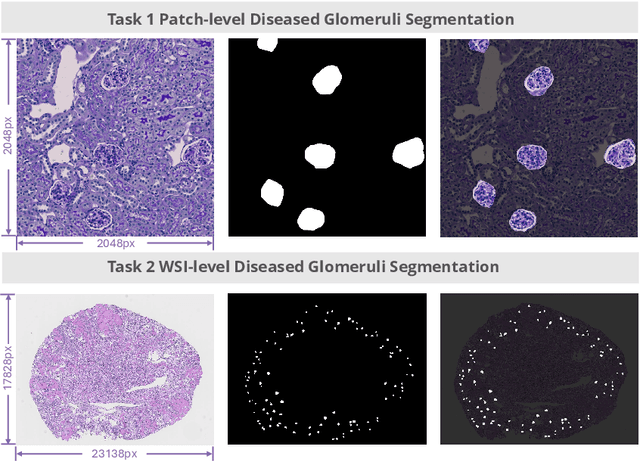

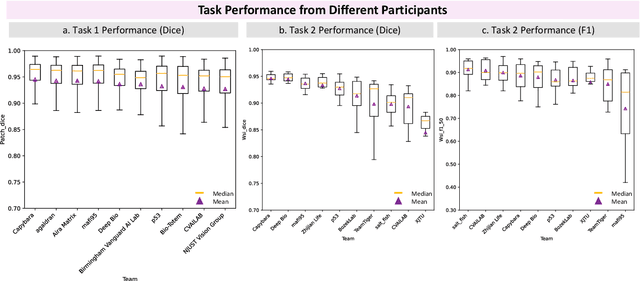

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.
EOG Communication Interface for Quadriplegics: Prototype & Signal Processing
Jan 05, 2025
Electrooculography (EOG) is an electrophysiological signal that determines the human eye orientation and is therefore widely used in Human Tracking Interfaces (HCI). The purpose of this project is to develop a communication method for quadriplegic patients using EOG signals aimed at text and voice generation. The system consists of 3D eye movement tracking embedded using a custom-built prototype to measure the eyeball's left-right and up-down movements. The ESP32 board, which has a set of parameters to convert the data into content displayed on LCDs and MP3 players, is used to capture and process the signal. helps people by facilitating more natural and efficient symptom expression. The blink system will be able to incorporate face masks and more eye tests as it continues to develop. Even if it might work, more research and clinical trials are needed to evaluate the system's usefulness and ensure that it performs as planned in real-world scenarios. With this project, assistive technology will make significant progress and improve the lives of many who suffer from severe motor impairments.
Scalable and low-cost remote lab platforms: Teaching industrial robotics using open-source tools and understanding its social implications
Dec 19, 2024With recent advancements in industrial robots, educating students in new technologies and preparing them for the future is imperative. However, access to industrial robots for teaching poses challenges, such as the high cost of acquiring these robots, the safety of the operator and the robot, and complicated training material. This paper proposes two low-cost platforms built using open-source tools like Robot Operating System (ROS) and its latest version ROS 2 to help students learn and test algorithms on remotely connected industrial robots. Universal Robotics (UR5) arm and a custom mobile rover were deployed in different life-size testbeds, a greenhouse, and a warehouse to create an Autonomous Agricultural Harvester System (AAHS) and an Autonomous Warehouse Management System (AWMS). These platforms were deployed for a period of 7 months and were tested for their efficacy with 1,433 and 1,312 students, respectively. The hardware used in AAHS and AWMS was controlled remotely for 160 and 355 hours, respectively, by students over a period of 3 months.
Movie Recommendation using Web Crawling
Dec 14, 2024In today's digital world, streaming platforms offer a vast array of movies, making it hard for users to find content matching their preferences. This paper explores integrating real time data from popular movie websites using advanced HTML scraping techniques and APIs. It also incorporates a recommendation system trained on a static Kaggle dataset, enhancing the relevance and freshness of suggestions. By combining content based filtering, collaborative filtering, and a hybrid model, we create a system that utilizes both historical and real time data for more personalized suggestions. Our methodology shows that incorporating dynamic data not only boosts user satisfaction but also aligns recommendations with current viewing trends.
Vision-based indoor localization of nano drones in controlled environment with its applications
Dec 11, 2024



Navigating unmanned aerial vehicles in environments where GPS signals are unavailable poses a compelling and intricate challenge. This challenge is further heightened when dealing with Nano Aerial Vehicles (NAVs) due to their compact size, payload restrictions, and computational capabilities. This paper proposes an approach for localization using off-board computing, an off-board monocular camera, and modified open-source algorithms. The proposed method uses three parallel proportional-integral-derivative controllers on the off-board computer to provide velocity corrections via wireless communication, stabilizing the NAV in a custom-controlled environment. Featuring a 3.1cm localization error and a modest setup cost of 50 USD, this approach proves optimal for environments where cost considerations are paramount. It is especially well-suited for applications like teaching drone control in academic institutions, where the specified error margin is deemed acceptable. Various applications are designed to validate the proposed technique, such as landing the NAV on a moving ground vehicle, path planning in a 3D space, and localizing multi-NAVs. The created package is openly available at https://github.com/simmubhangu/eyantra_drone to foster research in this field.