 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinMo: Kinematic-aware Human Motion Understanding and Generation
Nov 23, 2024



Controlling human motion based on text presents an important challenge in computer vision. Traditional approaches often rely on holistic action descriptions for motion synthesis, which struggle to capture subtle movements of local body parts. This limitation restricts the ability to isolate and manipulate specific movements. To address this, we propose a novel motion representation that decomposes motion into distinct body joint group movements and interactions from a kinematic perspective. We design an automatic dataset collection pipeline that enhances the existing text-motion benchmark by incorporating fine-grained local joint-group motion and interaction descriptions. To bridge the gap between text and motion domains, we introduce a hierarchical motion semantics approach that progressively fuses joint-level interaction information into the global action-level semantics for modality alignment. With this hierarchy, we introduce a coarse-to-fine motion synthesis procedure for various generation and editing downstream applications. Our quantitative and qualitative experiments demonstrate that the proposed formulation enhances text-motion retrieval by improving joint-spatial understanding, and enables more precise joint-motion generation and control. Project Page: {\small\url{https://andypinxinliu.github.io/KinMo/}}
TalkinNeRF: Animatable Neural Fields for Full-Body Talking Humans
Sep 25, 2024



We introduce a novel framework that learns a dynamic neural radiance field (NeRF) for full-body talking humans from monocular videos. Prior work represents only the body pose or the face. However, humans communicate with their full body, combining body pose, hand gestures, as well as facial expressions. In this work, we propose TalkinNeRF, a unified NeRF-based network that represents the holistic 4D human motion. Given a monocular video of a subject, we learn corresponding modules for the body, face, and hands, that are combined together to generate the final result. To capture complex finger articulation, we learn an additional deformation field for the hands. Our multi-identity representation enables simultaneous training for multiple subjects, as well as robust animation under completely unseen poses. It can also generalize to novel identities, given only a short video as input. We demonstrate state-of-the-art performance for animating full-body talking humans, with fine-grained hand articulation and facial expressions.
Semi-supervised Synthesis of High-Resolution Editable Textures for 3D Humans
Mar 31, 2021
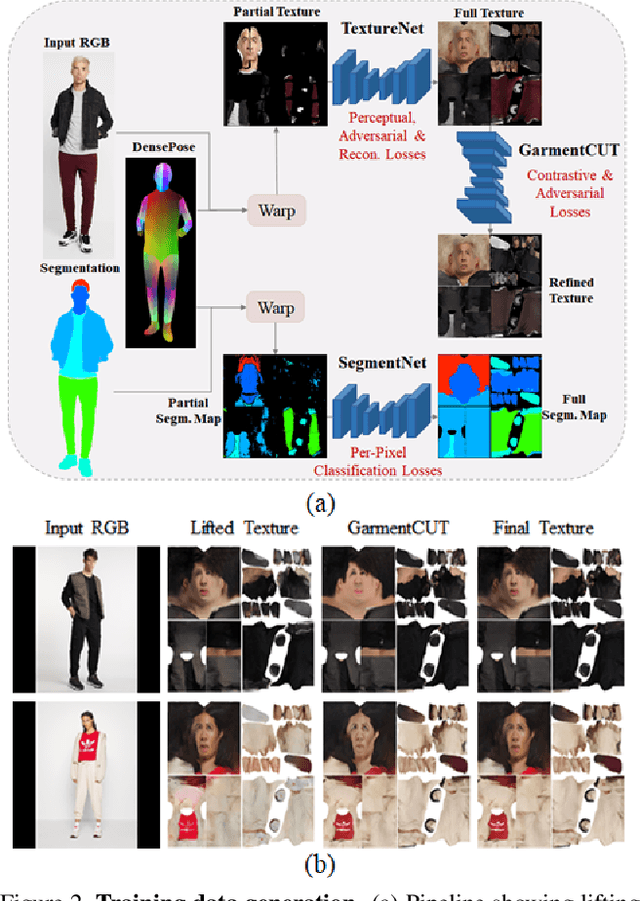
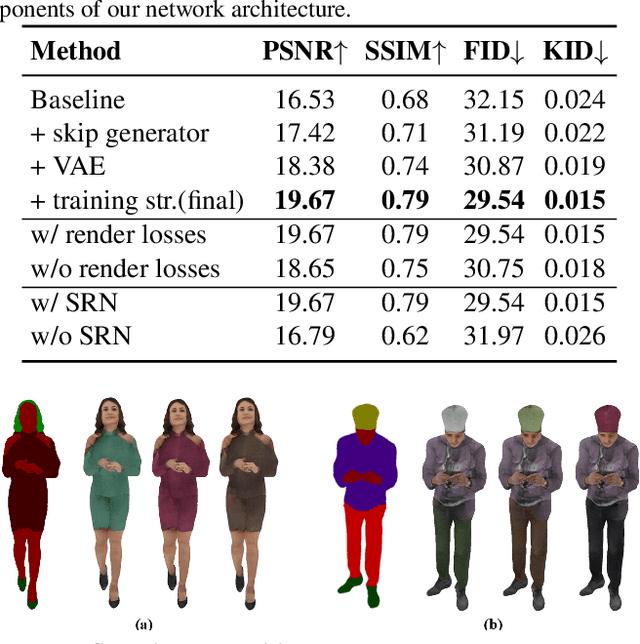
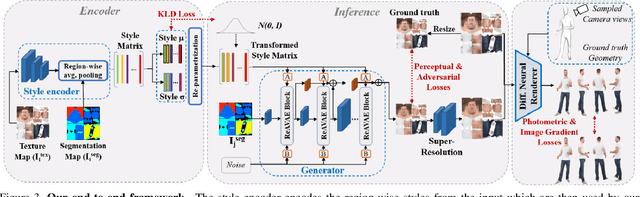
We introduce a novel approach to generate diverse high fidelity texture maps for 3D human meshes in a semi-supervised setup. Given a segmentation mask defining the layout of the semantic regions in the texture map, our network generates high-resolution textures with a variety of styles, that are then used for rendering purposes. To accomplish this task, we propose a Region-adaptive Adversarial Variational AutoEncoder (ReAVAE) that learns the probability distribution of the style of each region individually so that the style of the generated texture can be controlled by sampling from the region-specific distributions. In addition, we introduce a data generation technique to augment our training set with data lifted from single-view RGB inputs. Our training strategy allows the mixing of reference image styles with arbitrary styles for different regions, a property which can be valuable for virtual try-on AR/VR applications. Experimental results show that our method synthesizes better texture maps compared to prior work while enabling independent layout and style controllability.
Personalized Face Modeling for Improved Face Reconstruction and Motion Retargeting
Jul 17, 2020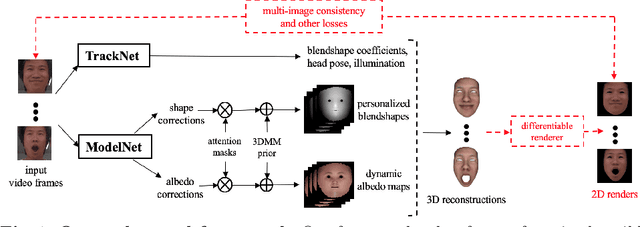
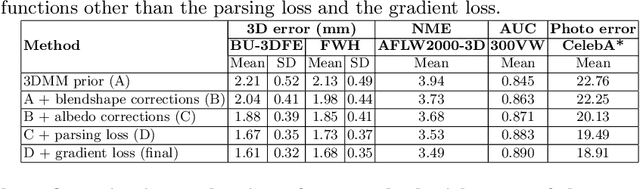


Traditional methods for image-based 3D face reconstruction and facial motion retargeting fit a 3D morphable model (3DMM) to the face, which has limited modeling capacity and fail to generalize well to in-the-wild data. Use of deformation transfer or multilinear tensor as a personalized 3DMM for blendshape interpolation does not address the fact that facial expressions result in different local and global skin deformations in different persons. Moreover, existing methods learn a single albedo per user which is not enough to capture the expression-specific skin reflectance variations. We propose an end-to-end framework that jointly learns a personalized face model per user and per-frame facial motion parameters from a large corpus of in-the-wild videos of user expressions. Specifically, we learn user-specific expression blendshapes and dynamic (expression-specific) albedo maps by predicting personalized corrections on top of a 3DMM prior. We introduce novel constraints to ensure that the corrected blendshapes retain their semantic meanings and the reconstructed geometry is disentangled from the albedo. Experimental results show that our personalization accurately captures fine-grained facial dynamics in a wide range of conditions and efficiently decouples the learned face model from facial motion, resulting in more accurate face reconstruction and facial motion retargeting compared to state-of-the-art methods.
Joint Face Detection and Facial Motion Retargeting for Multiple Faces
Feb 27, 2019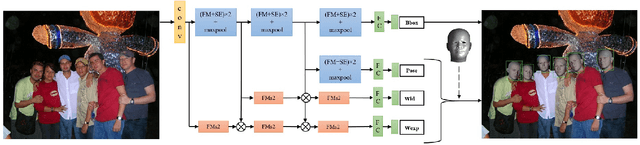
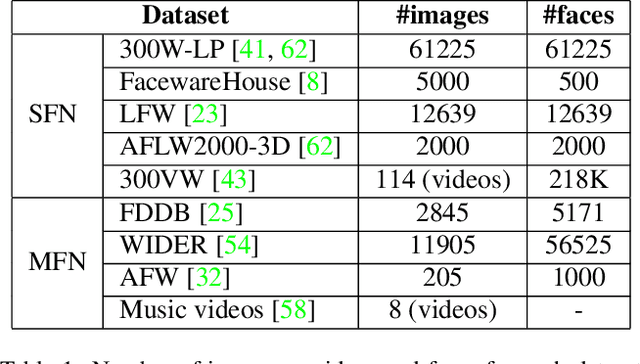

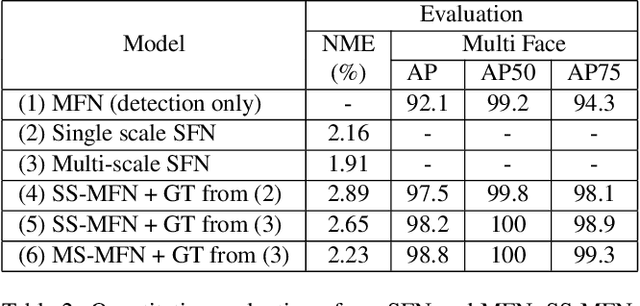
Facial motion retargeting is an important problem in both computer graphics and vision, which involves capturing the performance of a human face and transferring it to another 3D character. Learning 3D morphable model (3DMM) parameters from 2D face images using convolutional neural networks is common in 2D face alignment, 3D face reconstruction etc. However, existing methods either require an additional face detection step before retargeting or use a cascade of separate networks to perform detection followed by retargeting in a sequence. In this paper, we present a single end-to-end network to jointly predict the bounding box locations and 3DMM parameters for multiple faces. First, we design a novel multitask learning framework that learns a disentangled representation of 3DMM parameters for a single face. Then, we leverage the trained single face model to generate ground truth 3DMM parameters for multiple faces to train another network that performs joint face detection and motion retargeting for images with multiple faces. Experimental results show that our joint detection and retargeting network has high face detection accuracy and is robust to extreme expressions and poses while being faster than state-of-the-art methods.