 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRFace: Confidence Ranker for Model-Agnostic Face Detection Refinement
Mar 12, 2021


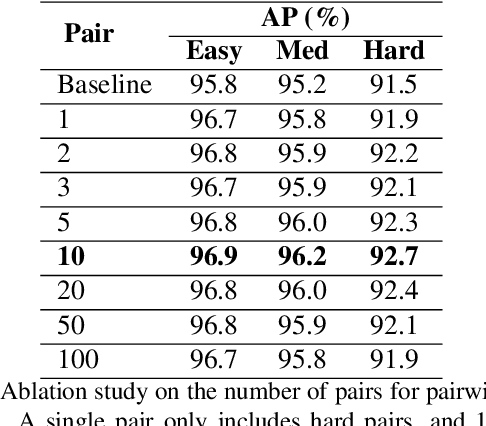
Face detection is a fundamental problem for many downstream face applications, and there is a rising demand for faster, more accurate yet support for higher resolution face detectors. Recent smartphones can record a video in 8K resolution, but many of the existing face detectors still fail due to the anchor size and training data. We analyze the failure cases and observe a large number of correct predicted boxes with incorrect confidences. To calibrate these confidences, we propose a confidence ranking network with a pairwise ranking loss to re-rank the predicted confidences locally within the same image. Our confidence ranker is model-agnostic, so we can augment the data by choosing the pairs from multiple face detectors during the training, and generalize to a wide range of face detectors during the testing. On WiderFace, we achieve the highest AP on the single-scale, and our AP is competitive with the previous multi-scale methods while being significantly faster. On 8K resolution, our method solves the GPU memory issue and allows us to indirectly train on 8K. We collect 8K resolution test set to show the improvement, and we will release our test set as a new benchmark for future research.
JNR: Joint-based Neural Rig Representation for Compact 3D Face Modeling
Jul 17, 2020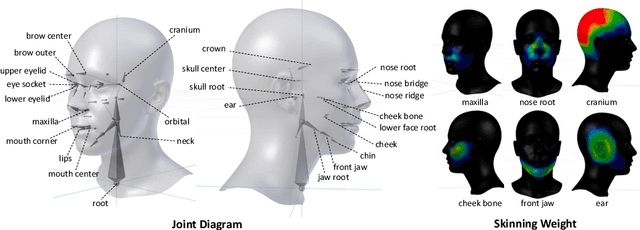


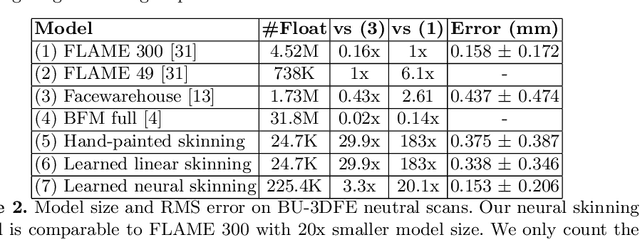
In this paper, we introduce a novel approach to learn a 3D face model using a joint-based face rig and a neural skinning network. Thanks to the joint-based representation, our model enjoys some significant advantages over prior blendshape-based models. First, it is very compact such that we are orders of magnitude smaller while still keeping strong modeling capacity. Second, because each joint has its semantic meaning, interactive facial geometry editing is made easier and more intuitive. Third, through skinning, our model supports adding mouth interior and eyes, as well as accessories (hair, eye glasses, etc.) in a simpler, more accurate and principled way. We argue that because the human face is highly structured and topologically consistent, it does not need to be learned entirely from data. Instead we can leverage prior knowledge in the form of a human-designed 3D face rig to reduce the data dependency, and learn a compact yet strong face model from only a small dataset (less than one hundred 3D scans). To further improve the modeling capacity, we train a skinning weight generator through adversarial learning. Experiments on fitting high-quality 3D scans (both neutral and expressive), noisy depth images, and RGB images demonstrate that its modeling capacity is on-par with state-of-the-art face models, such as FLAME and Facewarehouse, even though the model is 10 to 20 times smaller. This suggests broad value in both graphics and vision applications on mobile and edge devices.
Personalized Face Modeling for Improved Face Reconstruction and Motion Retargeting
Jul 17, 2020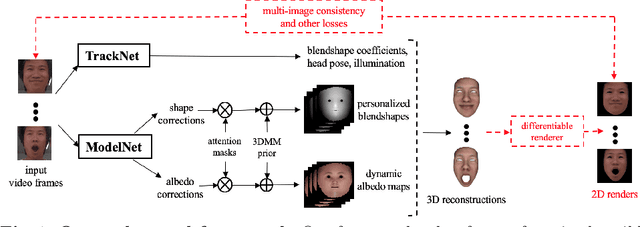
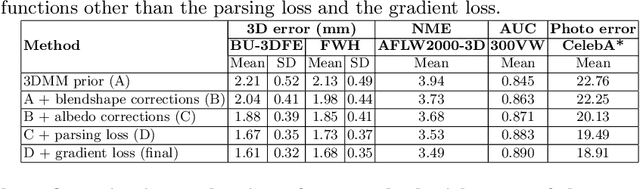


Traditional methods for image-based 3D face reconstruction and facial motion retargeting fit a 3D morphable model (3DMM) to the face, which has limited modeling capacity and fail to generalize well to in-the-wild data. Use of deformation transfer or multilinear tensor as a personalized 3DMM for blendshape interpolation does not address the fact that facial expressions result in different local and global skin deformations in different persons. Moreover, existing methods learn a single albedo per user which is not enough to capture the expression-specific skin reflectance variations. We propose an end-to-end framework that jointly learns a personalized face model per user and per-frame facial motion parameters from a large corpus of in-the-wild videos of user expressions. Specifically, we learn user-specific expression blendshapes and dynamic (expression-specific) albedo maps by predicting personalized corrections on top of a 3DMM prior. We introduce novel constraints to ensure that the corrected blendshapes retain their semantic meanings and the reconstructed geometry is disentangled from the albedo. Experimental results show that our personalization accurately captures fine-grained facial dynamics in a wide range of conditions and efficiently decouples the learned face model from facial motion, resulting in more accurate face reconstruction and facial motion retargeting compared to state-of-the-art methods.
Joint Face Detection and Facial Motion Retargeting for Multiple Faces
Feb 27, 2019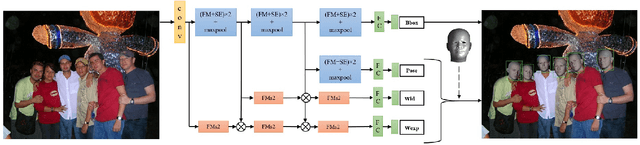

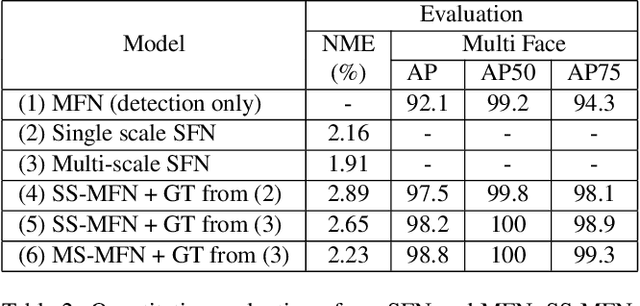
Facial motion retargeting is an important problem in both computer graphics and vision, which involves capturing the performance of a human face and transferring it to another 3D character. Learning 3D morphable model (3DMM) parameters from 2D face images using convolutional neural networks is common in 2D face alignment, 3D face reconstruction etc. However, existing methods either require an additional face detection step before retargeting or use a cascade of separate networks to perform detection followed by retargeting in a sequence. In this paper, we present a single end-to-end network to jointly predict the bounding box locations and 3DMM parameters for multiple faces. First, we design a novel multitask learning framework that learns a disentangled representation of 3DMM parameters for a single face. Then, we leverage the trained single face model to generate ground truth 3DMM parameters for multiple faces to train another network that performs joint face detection and motion retargeting for images with multiple faces. Experimental results show that our joint detection and retargeting network has high face detection accuracy and is robust to extreme expressions and poses while being faster than state-of-the-art methods.
Personalized Exposure Control Using Adaptive Metering and Reinforcement Learning
Aug 05, 2018

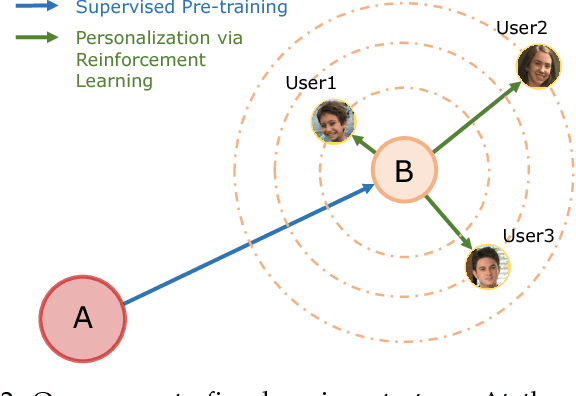

We propose a reinforcement learning approach for real-time exposure control of a mobile camera that is personalizable. Our approach is based on Markov Decision Process (MDP). In the camera viewfinder or live preview mode, given the current frame, our system predicts the change in exposure so as to optimize the trade-off among image quality, fast convergence, and minimal temporal oscillation. We model the exposure prediction function as a fully convolutional neural network that can be trained through Gaussian policy gradient in an end-to-end fashion. As a result, our system can associate scene semantics with exposure values; it can also be extended to personalize the exposure adjustments for a user and device. We improve the learning performance by incorporating an adaptive metering module that links semantics with exposure. This adaptive metering module generalizes the conventional spot or matrix metering techniques. We validate our system using the MIT FiveK and our own datasets captured using iPhone 7 and Google Pixel. Experimental results show that our system exhibits stable real-time behavior while improving visual quality compared to what is achieved through native camera control.
Automatic Stroke Lesions Segmentation in Diffusion-Weighted MRI
Mar 28, 2018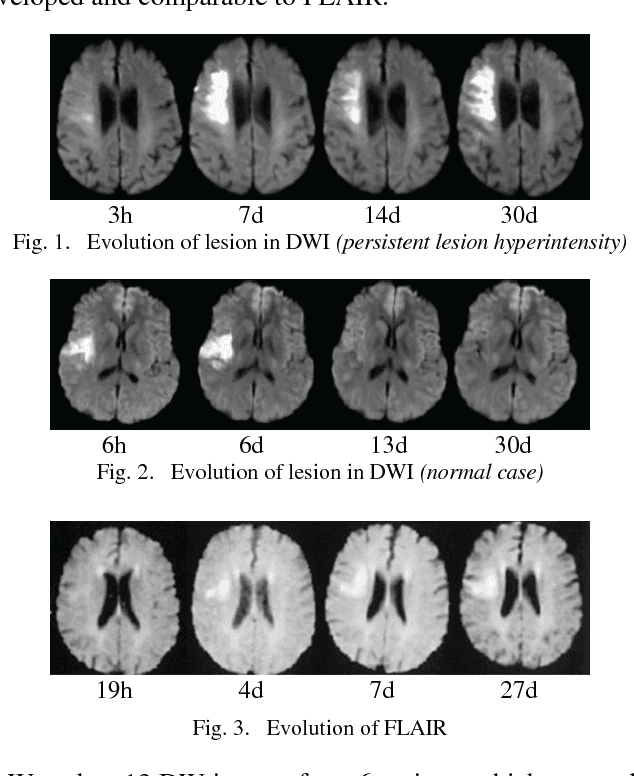
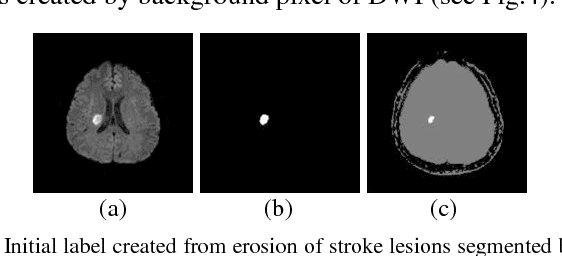
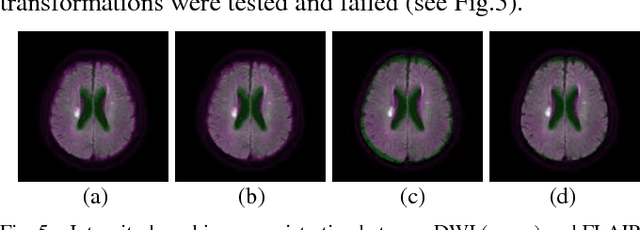

Diffusion-Weighted Magnetic Resonance Imaging (DWI) is widely used for early cerebral infarct detection caused by ischemic stroke. Manual segmentation is done by a radiologist as a common clinical process, nonetheless, challenges of cerebral infarct segmentation come from low resolution and uncertain boundaries. Many segmentation techniques have been proposed and proved by manual segmentation as gold standard. In order to reduce human error in research operation and clinical process, we adopt a semi-automatic segmentation as gold standard using Fluid-Attenuated Inversion-Recovery (FLAIR) Magnetic Resonance Image (MRI) from the same patient under controlled environment. Extensive testing is performed on popular segmentation algorithms including Otsu method, Fuzzy C-means, Hill-climbing based segmentation, and Growcut. The selected segmentation techniques have been validated by accuracy, sensitivity, and specificity using leave-one-out cross-validation to determine the possibility of each techniques first then maximizes the accuracy from the training set. Our experimental results demonstrate the effectiveness of selected methods.
Real-time Burst Photo Selection Using a Light-Head Adversarial Network
Mar 20, 2018
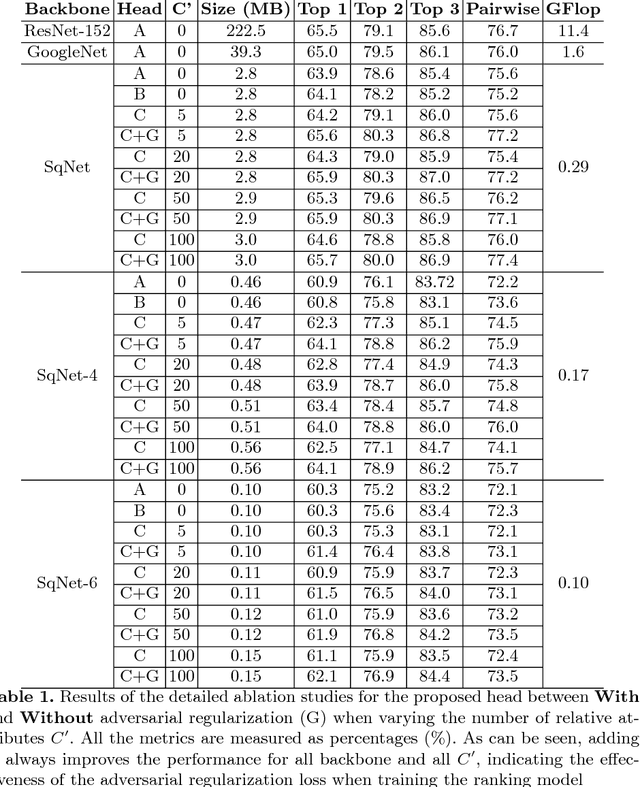
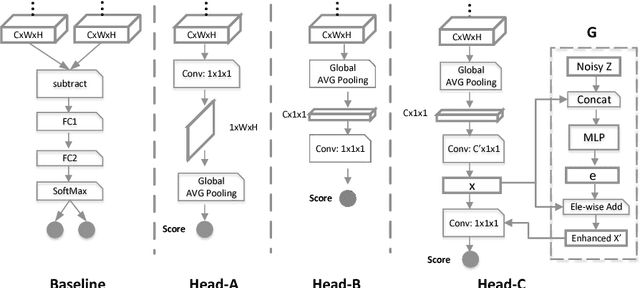
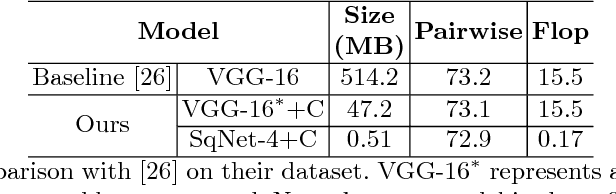
We present an automatic moment capture system that runs in real-time on mobile cameras. The system is designed to run in the viewfinder mode and capture a burst sequence of frames before and after the shutter is pressed. For each frame, the system predicts in real-time a "goodness" score, based on which the best moment in the burst can be selected immediately after the shutter is released, without any user interference. To solve the problem, we develop a highly efficient deep neural network ranking model, which implicitly learns a "latent relative attribute" space to capture subtle visual differences within a sequence of burst images. Then the overall goodness is computed as a linear aggregation of the goodnesses of all the latent attributes. The latent relative attributes and the aggregation function can be seamlessly integrated in one fully convolutional network and trained in an end-to-end fashion. To obtain a compact model which can run on mobile devices in real-time, we have explored and evaluated a wide range of network design choices, taking into account the constraints of model size, computational cost, and accuracy. Extensive studies show that the best frame predicted by our model hit users' top-1 (out of 11 on average) choice for $64.1\%$ cases and top-3 choices for $86.2\%$ cases. Moreover, the model(only 0.47M Bytes) can run in real time on mobile devices, e.g. only 13ms on iPhone 7 for one frame prediction.
In Teacher We Trust: Learning Compressed Models for Pedestrian Detection
Dec 01, 2016



Deep convolutional neural networks continue to advance the state-of-the-art in many domains as they grow bigger and more complex. It has been observed that many of the parameters of a large network are redundant, allowing for the possibility of learning a smaller network that mimics the outputs of the large network through a process called Knowledge Distillation. We show, however, that standard Knowledge Distillation is not effective for learning small models for the task of pedestrian detection. To improve this process, we introduce a higher-dimensional hint layer to increase information flow. We also estimate the variance in the outputs of the large network and propose a loss function to incorporate this uncertainty. Finally, we attempt to boost the complexity of the small network without increasing its size by using as input hand-designed features that have been demonstrated to be effective for pedestrian detection. We succeed in training a model that contains $400\times$ fewer parameters than the large network while outperforming AlexNet on the Caltech Pedestrian Dataset.
Comparison of Optimization Methods in Optical Flow Estimation
May 02, 2016



Optical flow estimation is a widely known problem in computer vision introduced by Gibson, J.J(1950) to describe the visual perception of human by stimulus objects. Estimation of optical flow model can be achieved by solving for the motion vectors from region of interest in the the different timeline. In this paper, we assumed slightly uniform change of velocity between two nearby frames, and solve the optical flow problem by traditional method, Lucas-Kanade(1981). This method performs minimization of errors between template and target frame warped back onto the template. Solving minimization steps requires optimization methods which have diverse convergence rate and error. We explored first and second order optimization methods, and compare their results with Gauss-Newton method in Lucas-Kanade. We generated 105 videos with 10,500 frames by synthetic objects, and 10 videos with 1,000 frames from real world footage. Our experimental results could be used as tuning parameters for Lucas-Kanade method.