 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTotal-Editing: Head Avatar with Editable Appearance, Motion, and Lighting
May 26, 2025Face reenactment and portrait relighting are essential tasks in portrait editing, yet they are typically addressed independently, without much synergy. Most face reenactment methods prioritize motion control and multiview consistency, while portrait relighting focuses on adjusting shading effects. To take advantage of both geometric consistency and illumination awareness, we introduce Total-Editing, a unified portrait editing framework that enables precise control over appearance, motion, and lighting. Specifically, we design a neural radiance field decoder with intrinsic decomposition capabilities. This allows seamless integration of lighting information from portrait images or HDR environment maps into synthesized portraits. We also incorporate a moving least squares based deformation field to enhance the spatiotemporal coherence of avatar motion and shading effects. With these innovations, our unified framework significantly improves the quality and realism of portrait editing results. Further, the multi-source nature of Total-Editing supports more flexible applications, such as illumination transfer from one portrait to another, or portrait animation with customized backgrounds.
S3Editor: A Sparse Semantic-Disentangled Self-Training Framework for Face Video Editing
Apr 11, 2024Face attribute editing plays a pivotal role in various applications. However, existing methods encounter challenges in achieving high-quality results while preserving identity, editing faithfulness, and temporal consistency. These challenges are rooted in issues related to the training pipeline, including limited supervision, architecture design, and optimization strategy. In this work, we introduce S3Editor, a Sparse Semantic-disentangled Self-training framework for face video editing. S3Editor is a generic solution that comprehensively addresses these challenges with three key contributions. Firstly, S3Editor adopts a self-training paradigm to enhance the training process through semi-supervision. Secondly, we propose a semantic disentangled architecture with a dynamic routing mechanism that accommodates diverse editing requirements. Thirdly, we present a structured sparse optimization schema that identifies and deactivates malicious neurons to further disentangle impacts from untarget attributes. S3Editor is model-agnostic and compatible with various editing approaches. Our extensive qualitative and quantitative results affirm that our approach significantly enhances identity preservation, editing fidelity, as well as temporal consistency.
OTOv3: Automatic Architecture-Agnostic Neural Network Training and Compression from Structured Pruning to Erasing Operators
Dec 15, 2023Compressing a predefined deep neural network (DNN) into a compact sub-network with competitive performance is crucial in the efficient machine learning realm. This topic spans various techniques, from structured pruning to neural architecture search, encompassing both pruning and erasing operators perspectives. Despite advancements, existing methods suffers from complex, multi-stage processes that demand substantial engineering and domain knowledge, limiting their broader applications. We introduce the third-generation Only-Train-Once (OTOv3), which first automatically trains and compresses a general DNN through pruning and erasing operations, creating a compact and competitive sub-network without the need of fine-tuning. OTOv3 simplifies and automates the training and compression process, minimizes the engineering efforts required from users. It offers key technological advancements: (i) automatic search space construction for general DNNs based on dependency graph analysis; (ii) Dual Half-Space Projected Gradient (DHSPG) and its enhanced version with hierarchical search (H2SPG) to reliably solve (hierarchical) structured sparsity problems and ensure sub-network validity; and (iii) automated sub-network construction using solutions from DHSPG/H2SPG and dependency graphs. Our empirical results demonstrate the efficacy of OTOv3 across various benchmarks in structured pruning and neural architecture search. OTOv3 produces sub-networks that match or exceed the state-of-the-arts. The source code will be available at https://github.com/tianyic/only_train_once.
GAIA: Zero-shot Talking Avatar Generation
Nov 26, 2023



Zero-shot talking avatar generation aims at synthesizing natural talking videos from speech and a single portrait image. Previous methods have relied on domain-specific heuristics such as warping-based motion representation and 3D Morphable Models, which limit the naturalness and diversity of the generated avatars. In this work, we introduce GAIA (Generative AI for Avatar), which eliminates the domain priors in talking avatar generation. In light of the observation that the speech only drives the motion of the avatar while the appearance of the avatar and the background typically remain the same throughout the entire video, we divide our approach into two stages: 1) disentangling each frame into motion and appearance representations; 2) generating motion sequences conditioned on the speech and reference portrait image. We collect a large-scale high-quality talking avatar dataset and train the model on it with different scales (up to 2B parameters). Experimental results verify the superiority, scalability, and flexibility of GAIA as 1) the resulting model beats previous baseline models in terms of naturalness, diversity, lip-sync quality, and visual quality; 2) the framework is scalable since larger models yield better results; 3) it is general and enables different applications like controllable talking avatar generation and text-instructed avatar generation.
HiFace: High-Fidelity 3D Face Reconstruction by Learning Static and Dynamic Details
Mar 20, 20233D Morphable Models (3DMMs) demonstrate great potential for reconstructing faithful and animatable 3D facial surfaces from a single image. The facial surface is influenced by the coarse shape, as well as the static detail (e,g., person-specific appearance) and dynamic detail (e.g., expression-driven wrinkles). Previous work struggles to decouple the static and dynamic details through image-level supervision, leading to reconstructions that are not realistic. In this paper, we aim at high-fidelity 3D face reconstruction and propose HiFace to explicitly model the static and dynamic details. Specifically, the static detail is modeled as the linear combination of a displacement basis, while the dynamic detail is modeled as the linear interpolation of two displacement maps with polarized expressions. We exploit several loss functions to jointly learn the coarse shape and fine details with both synthetic and real-world datasets, which enable HiFace to reconstruct high-fidelity 3D shapes with animatable details. Extensive quantitative and qualitative experiments demonstrate that HiFace presents state-of-the-art reconstruction quality and faithfully recovers both the static and dynamic details. Our project page can be found at https://project-hiface.github.io
MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation
Dec 17, 2022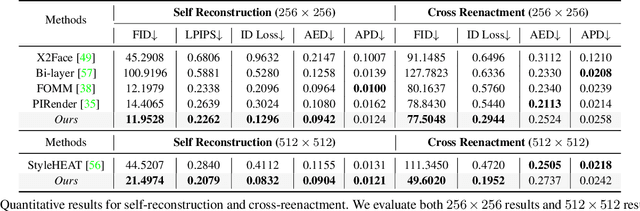
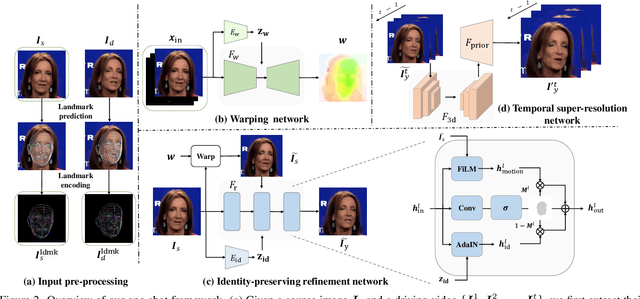
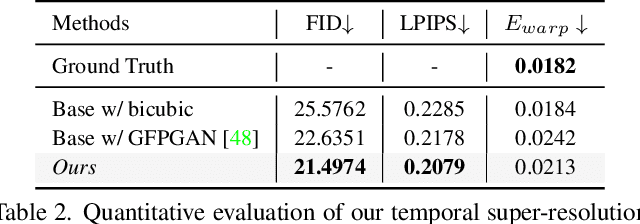
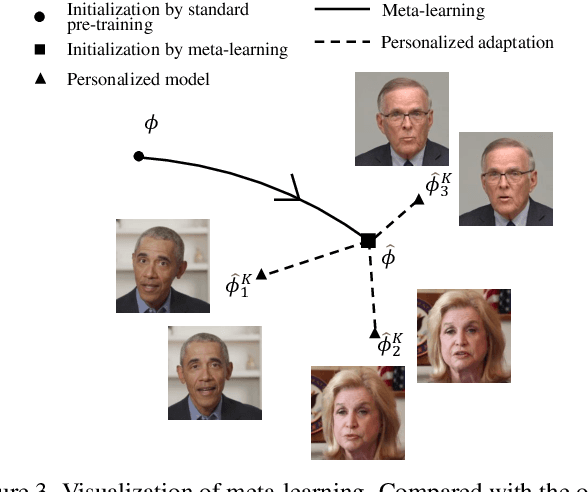
In this work, we propose an ID-preserving talking head generation framework, which advances previous methods in two aspects. First, as opposed to interpolating from sparse flow, we claim that dense landmarks are crucial to achieving accurate geometry-aware flow fields. Second, inspired by face-swapping methods, we adaptively fuse the source identity during synthesis, so that the network better preserves the key characteristics of the image portrait. Although the proposed model surpasses prior generation fidelity on established benchmarks, to further make the talking head generation qualified for real usage, personalized fine-tuning is usually needed. However, this process is rather computationally demanding that is unaffordable to standard users. To solve this, we propose a fast adaptation model using a meta-learning approach. The learned model can be adapted to a high-quality personalized model as fast as 30 seconds. Last but not the least, a spatial-temporal enhancement module is proposed to improve the fine details while ensuring temporal coherency. Extensive experiments prove the significant superiority of our approach over the state of the arts in both one-shot and personalized settings.
NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation
Nov 30, 2022Nerf-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.
JNR: Joint-based Neural Rig Representation for Compact 3D Face Modeling
Jul 17, 2020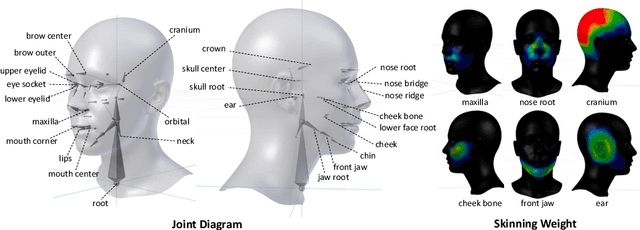


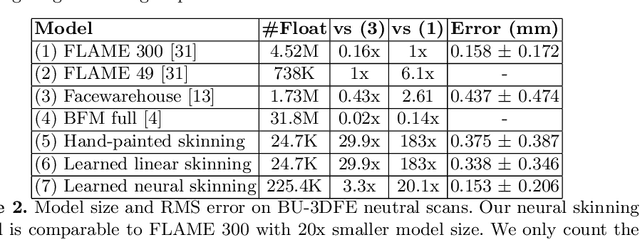
In this paper, we introduce a novel approach to learn a 3D face model using a joint-based face rig and a neural skinning network. Thanks to the joint-based representation, our model enjoys some significant advantages over prior blendshape-based models. First, it is very compact such that we are orders of magnitude smaller while still keeping strong modeling capacity. Second, because each joint has its semantic meaning, interactive facial geometry editing is made easier and more intuitive. Third, through skinning, our model supports adding mouth interior and eyes, as well as accessories (hair, eye glasses, etc.) in a simpler, more accurate and principled way. We argue that because the human face is highly structured and topologically consistent, it does not need to be learned entirely from data. Instead we can leverage prior knowledge in the form of a human-designed 3D face rig to reduce the data dependency, and learn a compact yet strong face model from only a small dataset (less than one hundred 3D scans). To further improve the modeling capacity, we train a skinning weight generator through adversarial learning. Experiments on fitting high-quality 3D scans (both neutral and expressive), noisy depth images, and RGB images demonstrate that its modeling capacity is on-par with state-of-the-art face models, such as FLAME and Facewarehouse, even though the model is 10 to 20 times smaller. This suggests broad value in both graphics and vision applications on mobile and edge devices.