 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJNR: Joint-based Neural Rig Representation for Compact 3D Face Modeling
Paper and Code
Jul 17, 2020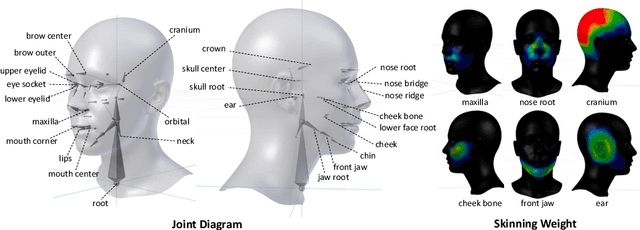


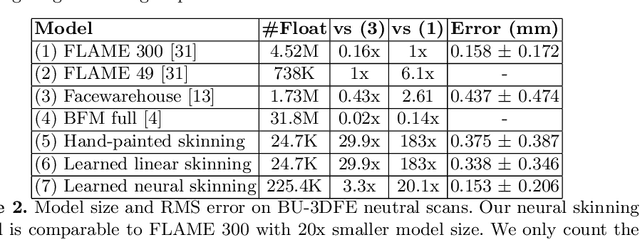
In this paper, we introduce a novel approach to learn a 3D face model using a joint-based face rig and a neural skinning network. Thanks to the joint-based representation, our model enjoys some significant advantages over prior blendshape-based models. First, it is very compact such that we are orders of magnitude smaller while still keeping strong modeling capacity. Second, because each joint has its semantic meaning, interactive facial geometry editing is made easier and more intuitive. Third, through skinning, our model supports adding mouth interior and eyes, as well as accessories (hair, eye glasses, etc.) in a simpler, more accurate and principled way. We argue that because the human face is highly structured and topologically consistent, it does not need to be learned entirely from data. Instead we can leverage prior knowledge in the form of a human-designed 3D face rig to reduce the data dependency, and learn a compact yet strong face model from only a small dataset (less than one hundred 3D scans). To further improve the modeling capacity, we train a skinning weight generator through adversarial learning. Experiments on fitting high-quality 3D scans (both neutral and expressive), noisy depth images, and RGB images demonstrate that its modeling capacity is on-par with state-of-the-art face models, such as FLAME and Facewarehouse, even though the model is 10 to 20 times smaller. This suggests broad value in both graphics and vision applications on mobile and edge devices.