 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTotal-Editing: Head Avatar with Editable Appearance, Motion, and Lighting
May 26, 2025Face reenactment and portrait relighting are essential tasks in portrait editing, yet they are typically addressed independently, without much synergy. Most face reenactment methods prioritize motion control and multiview consistency, while portrait relighting focuses on adjusting shading effects. To take advantage of both geometric consistency and illumination awareness, we introduce Total-Editing, a unified portrait editing framework that enables precise control over appearance, motion, and lighting. Specifically, we design a neural radiance field decoder with intrinsic decomposition capabilities. This allows seamless integration of lighting information from portrait images or HDR environment maps into synthesized portraits. We also incorporate a moving least squares based deformation field to enhance the spatiotemporal coherence of avatar motion and shading effects. With these innovations, our unified framework significantly improves the quality and realism of portrait editing results. Further, the multi-source nature of Total-Editing supports more flexible applications, such as illumination transfer from one portrait to another, or portrait animation with customized backgrounds.
GASP: Gaussian Avatars with Synthetic Priors
Dec 10, 2024



Gaussian Splatting has changed the game for real-time photo-realistic rendering. One of the most popular applications of Gaussian Splatting is to create animatable avatars, known as Gaussian Avatars. Recent works have pushed the boundaries of quality and rendering efficiency but suffer from two main limitations. Either they require expensive multi-camera rigs to produce avatars with free-view rendering, or they can be trained with a single camera but only rendered at high quality from this fixed viewpoint. An ideal model would be trained using a short monocular video or image from available hardware, such as a webcam, and rendered from any view. To this end, we propose GASP: Gaussian Avatars with Synthetic Priors. To overcome the limitations of existing datasets, we exploit the pixel-perfect nature of synthetic data to train a Gaussian Avatar prior. By fitting this prior model to a single photo or video and fine-tuning it, we get a high-quality Gaussian Avatar, which supports 360$^\circ$ rendering. Our prior is only required for fitting, not inference, enabling real-time application. Through our method, we obtain high-quality, animatable Avatars from limited data which can be animated and rendered at 70fps on commercial hardware. See our project page (https://microsoft.github.io/GASP/) for results.
SympCam: Remote Optical Measurement of Sympathetic Arousal
Oct 27, 2024



Recent work has shown that a person's sympathetic arousal can be estimated from facial videos alone using basic signal processing. This opens up new possibilities in the field of telehealth and stress management, providing a non-invasive method to measure stress only using a regular RGB camera. In this paper, we present SympCam, a new 3D convolutional architecture tailored to the task of remote sympathetic arousal prediction. Our model incorporates a temporal attention module (TAM) to enhance the temporal coherence of our sequential data processing capabilities. The predictions from our method improve accuracy metrics of sympathetic arousal in prior work by 48% to a mean correlation of 0.77. We additionally compare our method with common remote photoplethysmography (rPPG) networks and show that they alone cannot accurately predict sympathetic arousal "out-of-the-box". Furthermore, we show that the sympathetic arousal predicted by our method allows detecting physical stress with a balanced accuracy of 90% - an improvement of 61% compared to the rPPG method commonly used in related work, demonstrating the limitations of using rPPG alone. Finally, we contribute a dataset designed explicitly for the task of remote sympathetic arousal prediction. Our dataset contains synchronized face and hand videos of 20 participants from two cameras synchronized with electrodermal activity (EDA) and photoplethysmography (PPG) measurements. We will make this dataset available to the community and use it to evaluate the methods in this paper. To the best of our knowledge, this is the first dataset available to other researchers designed for remote sympathetic arousal prediction.
Look Ma, no markers: holistic performance capture without the hassle
Oct 15, 2024



We tackle the problem of highly-accurate, holistic performance capture for the face, body and hands simultaneously. Motion-capture technologies used in film and game production typically focus only on face, body or hand capture independently, involve complex and expensive hardware and a high degree of manual intervention from skilled operators. While machine-learning-based approaches exist to overcome these problems, they usually only support a single camera, often operate on a single part of the body, do not produce precise world-space results, and rarely generalize outside specific contexts. In this work, we introduce the first technique for marker-free, high-quality reconstruction of the complete human body, including eyes and tongue, without requiring any calibration, manual intervention or custom hardware. Our approach produces stable world-space results from arbitrary camera rigs as well as supporting varied capture environments and clothing. We achieve this through a hybrid approach that leverages machine learning models trained exclusively on synthetic data and powerful parametric models of human shape and motion. We evaluate our method on a number of body, face and hand reconstruction benchmarks and demonstrate state-of-the-art results that generalize on diverse datasets.
Hairmony: Fairness-aware hairstyle classification
Oct 15, 2024



We present a method for prediction of a person's hairstyle from a single image. Despite growing use cases in user digitization and enrollment for virtual experiences, available methods are limited, particularly in the range of hairstyles they can capture. Human hair is extremely diverse and lacks any universally accepted description or categorization, making this a challenging task. Most current methods rely on parametric models of hair at a strand level. These approaches, while very promising, are not yet able to represent short, frizzy, coily hair and gathered hairstyles. We instead choose a classification approach which can represent the diversity of hairstyles required for a truly robust and inclusive system. Previous classification approaches have been restricted by poorly labeled data that lacks diversity, imposing constraints on the usefulness of any resulting enrollment system. We use only synthetic data to train our models. This allows for explicit control of diversity of hairstyle attributes, hair colors, facial appearance, poses, environments and other parameters. It also produces noise-free ground-truth labels. We introduce a novel hairstyle taxonomy developed in collaboration with a diverse group of domain experts which we use to balance our training data, supervise our model, and directly measure fairness. We annotate our synthetic training data and a real evaluation dataset using this taxonomy and release both to enable comparison of future hairstyle prediction approaches. We employ an architecture based on a pre-trained feature extraction network in order to improve generalization of our method to real data and predict taxonomy attributes as an auxiliary task to improve accuracy. Results show our method to be significantly more robust for challenging hairstyles than recent parametric approaches.
Video-based sympathetic arousal assessment via peripheral blood flow estimation
Nov 12, 2023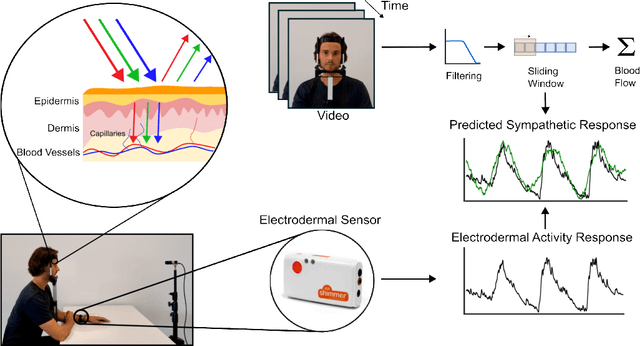



Electrodermal activity (EDA) is considered a standard marker of sympathetic activity. However, traditional EDA measurement requires electrodes in steady contact with the skin. Can sympathetic arousal be measured using only an optical sensor, such as an RGB camera? This paper presents a novel approach to infer sympathetic arousal by measuring the peripheral blood flow on the face or hand optically. We contribute a self-recorded dataset of 21 participants, comprising synchronized videos of participants' faces and palms and gold-standard EDA and photoplethysmography (PPG) signals. Our results show that we can measure peripheral sympathetic responses that closely correlate with the ground truth EDA. We obtain median correlations of 0.57 to 0.63 between our inferred signals and the ground truth EDA using only videos of the participants' palms or foreheads or PPG signals from the foreheads or fingers. We also show that sympathetic arousal is best inferred from the forehead, finger, or palm.
HiFace: High-Fidelity 3D Face Reconstruction by Learning Static and Dynamic Details
Mar 20, 20233D Morphable Models (3DMMs) demonstrate great potential for reconstructing faithful and animatable 3D facial surfaces from a single image. The facial surface is influenced by the coarse shape, as well as the static detail (e,g., person-specific appearance) and dynamic detail (e.g., expression-driven wrinkles). Previous work struggles to decouple the static and dynamic details through image-level supervision, leading to reconstructions that are not realistic. In this paper, we aim at high-fidelity 3D face reconstruction and propose HiFace to explicitly model the static and dynamic details. Specifically, the static detail is modeled as the linear combination of a displacement basis, while the dynamic detail is modeled as the linear interpolation of two displacement maps with polarized expressions. We exploit several loss functions to jointly learn the coarse shape and fine details with both synthetic and real-world datasets, which enable HiFace to reconstruct high-fidelity 3D shapes with animatable details. Extensive quantitative and qualitative experiments demonstrate that HiFace presents state-of-the-art reconstruction quality and faithfully recovers both the static and dynamic details. Our project page can be found at https://project-hiface.github.io
Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
Dec 12, 2022



This paper presents a 3D generative model that uses diffusion models to automatically generate 3D digital avatars represented as neural radiance fields. A significant challenge in generating such avatars is that the memory and processing costs in 3D are prohibitive for producing the rich details required for high-quality avatars. To tackle this problem we propose the roll-out diffusion network (Rodin), which represents a neural radiance field as multiple 2D feature maps and rolls out these maps into a single 2D feature plane within which we perform 3D-aware diffusion. The Rodin model brings the much-needed computational efficiency while preserving the integrity of diffusion in 3D by using 3D-aware convolution that attends to projected features in the 2D feature plane according to their original relationship in 3D. We also use latent conditioning to orchestrate the feature generation for global coherence, leading to high-fidelity avatars and enabling their semantic editing based on text prompts. Finally, we use hierarchical synthesis to further enhance details. The 3D avatars generated by our model compare favorably with those produced by existing generative techniques. We can generate highly detailed avatars with realistic hairstyles and facial hair like beards. We also demonstrate 3D avatar generation from image or text as well as text-guided editability.
Mesh-Tension Driven Expression-Based Wrinkles for Synthetic Faces
Oct 05, 2022
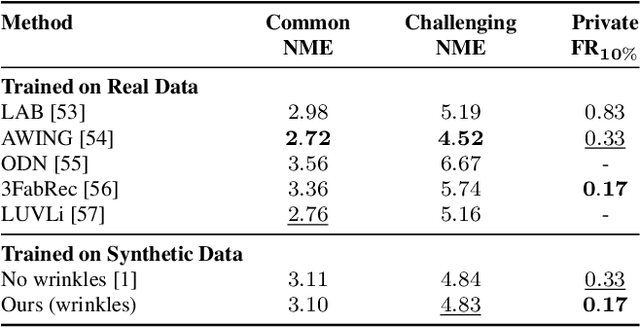

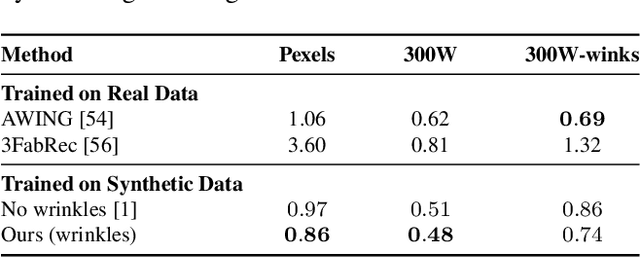
Recent advances in synthesizing realistic faces have shown that synthetic training data can replace real data for various face-related computer vision tasks. A question arises: how important is realism? Is the pursuit of photorealism excessive? In this work, we show otherwise. We boost the realism of our synthetic faces by introducing dynamic skin wrinkles in response to facial expressions and observe significant performance improvements in downstream computer vision tasks. Previous approaches for producing such wrinkles either required prohibitive artist effort to scale across identities and expressions or were not capable of reconstructing high-frequency skin details with sufficient fidelity. Our key contribution is an approach that produces realistic wrinkles across a large and diverse population of digital humans. Concretely, we formalize the concept of mesh-tension and use it to aggregate possible wrinkles from high-quality expression scans into albedo and displacement texture maps. At synthesis, we use these maps to produce wrinkles even for expressions not represented in the source scans. Additionally, to provide a more nuanced indicator of model performance under deformations resulting from compressed expressions, we introduce the 300W-winks evaluation subset and the Pexels dataset of closed eyes and winks.
DigiFace-1M: 1 Million Digital Face Images for Face Recognition
Oct 05, 2022


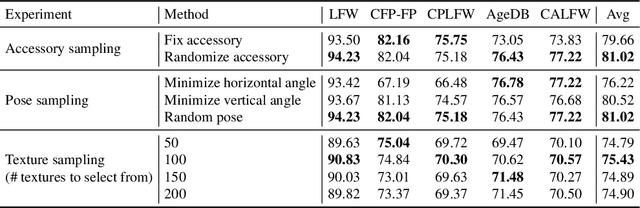
State-of-the-art face recognition models show impressive accuracy, achieving over 99.8% on Labeled Faces in the Wild (LFW) dataset. Such models are trained on large-scale datasets that contain millions of real human face images collected from the internet. Web-crawled face images are severely biased (in terms of race, lighting, make-up, etc) and often contain label noise. More importantly, the face images are collected without explicit consent, raising ethical concerns. To avoid such problems, we introduce a large-scale synthetic dataset for face recognition, obtained by rendering digital faces using a computer graphics pipeline. We first demonstrate that aggressive data augmentation can significantly reduce the synthetic-to-real domain gap. Having full control over the rendering pipeline, we also study how each attribute (e.g., variation in facial pose, accessories and textures) affects the accuracy. Compared to SynFace, a recent method trained on GAN-generated synthetic faces, we reduce the error rate on LFW by 52.5% (accuracy from 91.93% to 96.17%). By fine-tuning the network on a smaller number of real face images that could reasonably be obtained with consent, we achieve accuracy that is comparable to the methods trained on millions of real face images.