 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Ma, no markers: holistic performance capture without the hassle
Oct 15, 2024



We tackle the problem of highly-accurate, holistic performance capture for the face, body and hands simultaneously. Motion-capture technologies used in film and game production typically focus only on face, body or hand capture independently, involve complex and expensive hardware and a high degree of manual intervention from skilled operators. While machine-learning-based approaches exist to overcome these problems, they usually only support a single camera, often operate on a single part of the body, do not produce precise world-space results, and rarely generalize outside specific contexts. In this work, we introduce the first technique for marker-free, high-quality reconstruction of the complete human body, including eyes and tongue, without requiring any calibration, manual intervention or custom hardware. Our approach produces stable world-space results from arbitrary camera rigs as well as supporting varied capture environments and clothing. We achieve this through a hybrid approach that leverages machine learning models trained exclusively on synthetic data and powerful parametric models of human shape and motion. We evaluate our method on a number of body, face and hand reconstruction benchmarks and demonstrate state-of-the-art results that generalize on diverse datasets.
Hairmony: Fairness-aware hairstyle classification
Oct 15, 2024



We present a method for prediction of a person's hairstyle from a single image. Despite growing use cases in user digitization and enrollment for virtual experiences, available methods are limited, particularly in the range of hairstyles they can capture. Human hair is extremely diverse and lacks any universally accepted description or categorization, making this a challenging task. Most current methods rely on parametric models of hair at a strand level. These approaches, while very promising, are not yet able to represent short, frizzy, coily hair and gathered hairstyles. We instead choose a classification approach which can represent the diversity of hairstyles required for a truly robust and inclusive system. Previous classification approaches have been restricted by poorly labeled data that lacks diversity, imposing constraints on the usefulness of any resulting enrollment system. We use only synthetic data to train our models. This allows for explicit control of diversity of hairstyle attributes, hair colors, facial appearance, poses, environments and other parameters. It also produces noise-free ground-truth labels. We introduce a novel hairstyle taxonomy developed in collaboration with a diverse group of domain experts which we use to balance our training data, supervise our model, and directly measure fairness. We annotate our synthetic training data and a real evaluation dataset using this taxonomy and release both to enable comparison of future hairstyle prediction approaches. We employ an architecture based on a pre-trained feature extraction network in order to improve generalization of our method to real data and predict taxonomy attributes as an auxiliary task to improve accuracy. Results show our method to be significantly more robust for challenging hairstyles than recent parametric approaches.
MeerCRAB: MeerLICHT Classification of Real and Bogus Transients using Deep Learning
Apr 28, 2021

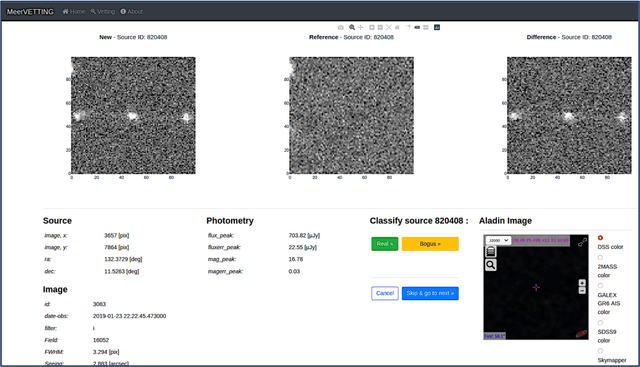
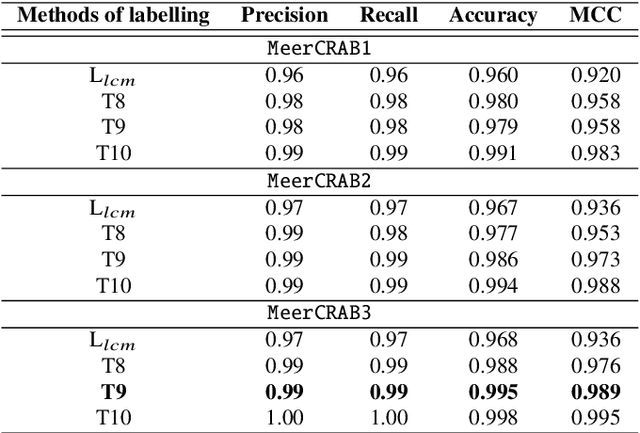
Astronomers require efficient automated detection and classification pipelines when conducting large-scale surveys of the (optical) sky for variable and transient sources. Such pipelines are fundamentally important, as they permit rapid follow-up and analysis of those detections most likely to be of scientific value. We therefore present a deep learning pipeline based on the convolutional neural network architecture called $\texttt{MeerCRAB}$. It is designed to filter out the so called 'bogus' detections from true astrophysical sources in the transient detection pipeline of the MeerLICHT telescope. Optical candidates are described using a variety of 2D images and numerical features extracted from those images. The relationship between the input images and the target classes is unclear, since the ground truth is poorly defined and often the subject of debate. This makes it difficult to determine which source of information should be used to train a classification algorithm. We therefore used two methods for labelling our data (i) thresholding and (ii) latent class model approaches. We deployed variants of $\texttt{MeerCRAB}$ that employed different network architectures trained using different combinations of input images and training set choices, based on classification labels provided by volunteers. The deepest network worked best with an accuracy of 99.5$\%$ and Matthews correlation coefficient (MCC) value of 0.989. The best model was integrated to the MeerLICHT transient vetting pipeline, enabling the accurate and efficient classification of detected transients that allows researchers to select the most promising candidates for their research goals.
Imbalance Learning for Variable Star Classification
Feb 27, 2020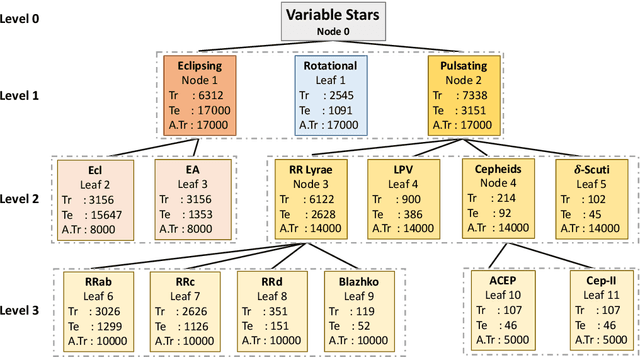

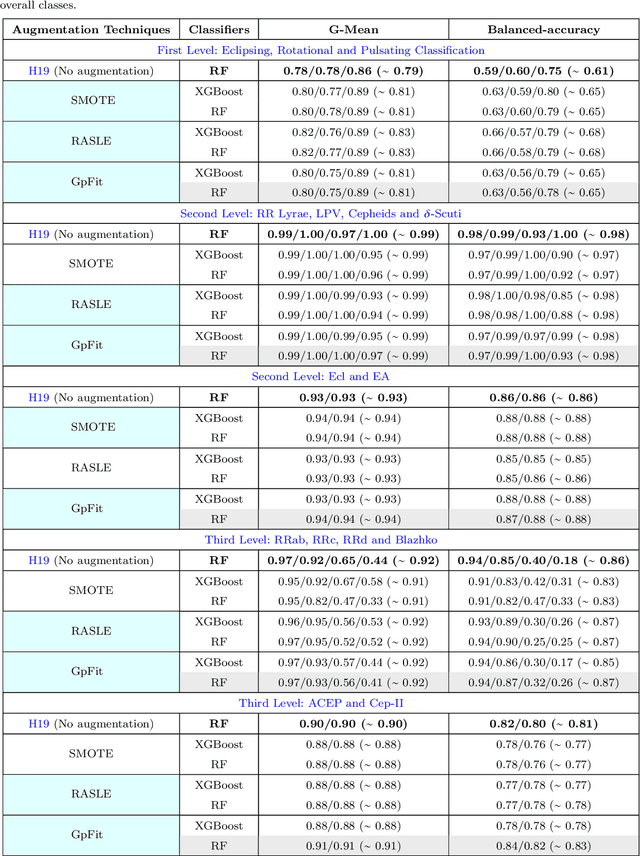
The accurate automated classification of variable stars into their respective sub-types is difficult. Machine learning based solutions often fall foul of the imbalanced learning problem, which causes poor generalisation performance in practice, especially on rare variable star sub-types. In previous work, we attempted to overcome such deficiencies via the development of a hierarchical machine learning classifier. This 'algorithm-level' approach to tackling imbalance, yielded promising results on Catalina Real-Time Survey (CRTS) data, outperforming the binary and multi-class classification schemes previously applied in this area. In this work, we attempt to further improve hierarchical classification performance by applying 'data-level' approaches to directly augment the training data so that they better describe under-represented classes. We apply and report results for three data augmentation methods in particular: $\textit{R}$andomly $\textit{A}$ugmented $\textit{S}$ampled $\textit{L}$ight curves from magnitude $\textit{E}$rror ($\texttt{RASLE}$), augmenting light curves with Gaussian Process modelling ($\texttt{GpFit}$) and the Synthetic Minority Over-sampling Technique ($\texttt{SMOTE}$). When combining the 'algorithm-level' (i.e. the hierarchical scheme) together with the 'data-level' approach, we further improve variable star classification accuracy by 1-4$\%$. We found that a higher classification rate is obtained when using $\texttt{GpFit}$ in the hierarchical model. Further improvement of the metric scores requires a better standard set of correctly identified variable stars and, perhaps enhanced features are needed.
Comparing Multi-class, Binary and Hierarchical Machine Learning Classification schemes for variable stars
Jul 18, 2019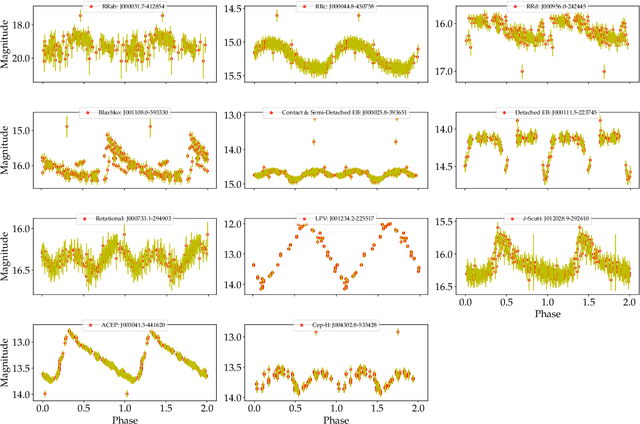

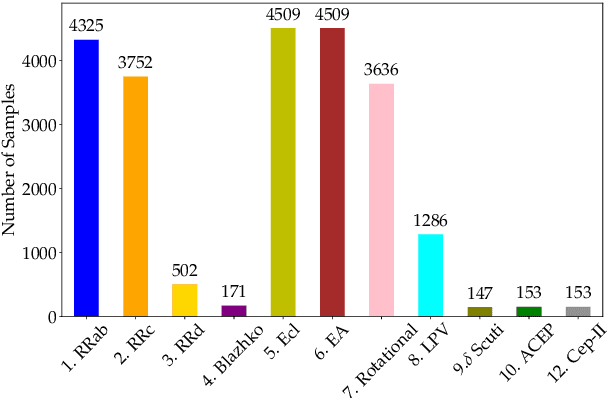
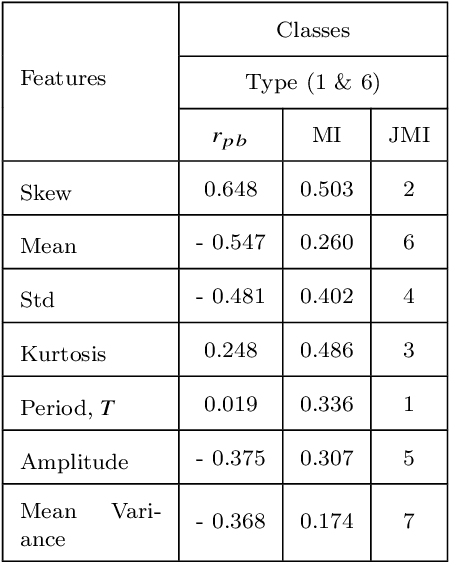
Upcoming synoptic surveys are set to generate an unprecedented amount of data. This requires an automatic framework that can quickly and efficiently provide classification labels for several new object classification challenges. Using data describing 11 types of variable stars from the Catalina Real-Time Transient Surveys (CRTS), we illustrate how to capture the most important information from computed features and describe detailed methods of how to robustly use Information Theory for feature selection and evaluation. We apply three Machine Learning (ML) algorithms and demonstrate how to optimize these classifiers via cross-validation techniques. For the CRTS dataset, we find that the Random Forest (RF) classifier performs best in terms of balanced-accuracy and geometric means. We demonstrate substantially improved classification results by converting the multi-class problem into a binary classification task, achieving a balanced-accuracy rate of $\sim$99 per cent for the classification of ${\delta}$-Scuti and Anomalous Cepheids (ACEP). Additionally, we describe how classification performance can be improved via converting a 'flat-multi-class' problem into a hierarchical taxonomy. We develop a new hierarchical structure and propose a new set of classification features, enabling the accurate identification of subtypes of cepheids, RR Lyrae and eclipsing binary stars in CRTS data.
DeepSource: Point Source Detection using Deep Learning
Jul 07, 2018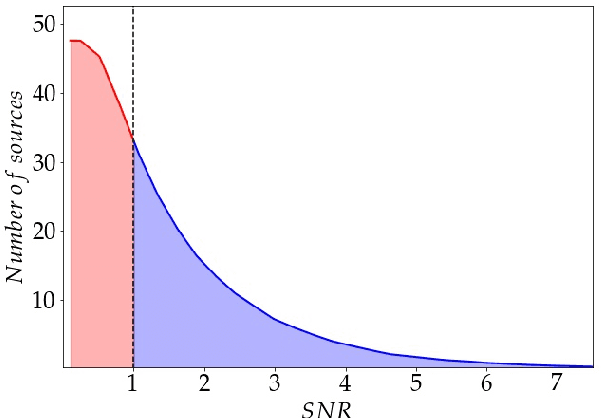


Point source detection at low signal-to-noise is challenging for astronomical surveys, particularly in radio interferometry images where the noise is correlated. Machine learning is a promising solution, allowing the development of algorithms tailored to specific telescope arrays and science cases. We present DeepSource - a deep learning solution - that uses convolutional neural networks to achieve these goals. DeepSource enhances the Signal-to-Noise Ratio (SNR) of the original map and then uses dynamic blob detection to detect sources. Trained and tested on two sets of 500 simulated 1 deg x 1 deg MeerKAT images with a total of 300,000 sources, DeepSource is essentially perfect in both purity and completeness down to SNR = 4 and outperforms PyBDSF in all metrics. For uniformly-weighted images it achieves a Purity x Completeness (PC) score at SNR = 3 of 0.73, compared to 0.31 for the best PyBDSF model. For natural-weighting we find a smaller improvement of ~40% in the PC score at SNR = 3. If instead we ask where either of the purity or completeness first drop to 90%, we find that DeepSource reaches this value at SNR = 3.6 compared to the 4.3 of PyBDSF (natural-weighting). A key advantage of DeepSource is that it can learn to optimally trade off purity and completeness for any science case under consideration. Our results show that deep learning is a promising approach to point source detection in astronomical images.