 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHairmony: Fairness-aware hairstyle classification
Oct 15, 2024



We present a method for prediction of a person's hairstyle from a single image. Despite growing use cases in user digitization and enrollment for virtual experiences, available methods are limited, particularly in the range of hairstyles they can capture. Human hair is extremely diverse and lacks any universally accepted description or categorization, making this a challenging task. Most current methods rely on parametric models of hair at a strand level. These approaches, while very promising, are not yet able to represent short, frizzy, coily hair and gathered hairstyles. We instead choose a classification approach which can represent the diversity of hairstyles required for a truly robust and inclusive system. Previous classification approaches have been restricted by poorly labeled data that lacks diversity, imposing constraints on the usefulness of any resulting enrollment system. We use only synthetic data to train our models. This allows for explicit control of diversity of hairstyle attributes, hair colors, facial appearance, poses, environments and other parameters. It also produces noise-free ground-truth labels. We introduce a novel hairstyle taxonomy developed in collaboration with a diverse group of domain experts which we use to balance our training data, supervise our model, and directly measure fairness. We annotate our synthetic training data and a real evaluation dataset using this taxonomy and release both to enable comparison of future hairstyle prediction approaches. We employ an architecture based on a pre-trained feature extraction network in order to improve generalization of our method to real data and predict taxonomy attributes as an auxiliary task to improve accuracy. Results show our method to be significantly more robust for challenging hairstyles than recent parametric approaches.
Learning to Deblur and Rotate Motion-Blurred Faces
Dec 14, 2021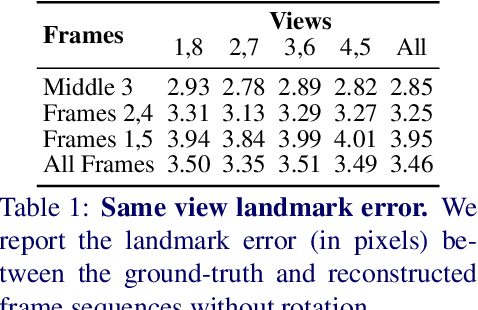
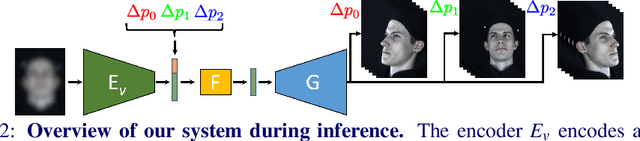
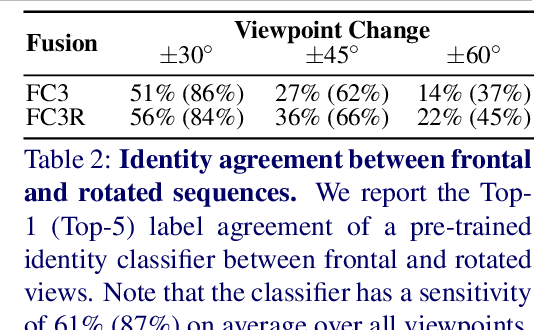
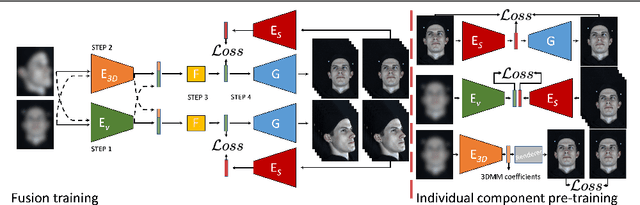
We propose a solution to the novel task of rendering sharp videos from new viewpoints from a single motion-blurred image of a face. Our method handles the complexity of face blur by implicitly learning the geometry and motion of faces through the joint training on three large datasets: FFHQ and 300VW, which are publicly available, and a new Bern Multi-View Face Dataset (BMFD) that we built. The first two datasets provide a large variety of faces and allow our model to generalize better. BMFD instead allows us to introduce multi-view constraints, which are crucial to synthesizing sharp videos from a new camera view. It consists of high frame rate synchronized videos from multiple views of several subjects displaying a wide range of facial expressions. We use the high frame rate videos to simulate realistic motion blur through averaging. Thanks to this dataset, we train a neural network to reconstruct a 3D video representation from a single image and the corresponding face gaze. We then provide a camera viewpoint relative to the estimated gaze and the blurry image as input to an encoder-decoder network to generate a video of sharp frames with a novel camera viewpoint. We demonstrate our approach on test subjects of our multi-view dataset and VIDTIMIT.
Video Representation Learning by Recognizing Temporal Transformations
Jul 21, 2020

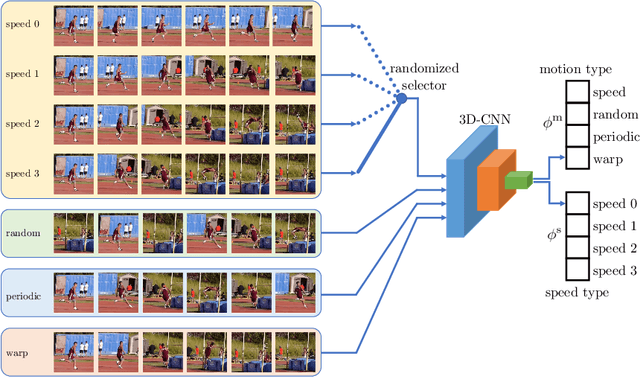
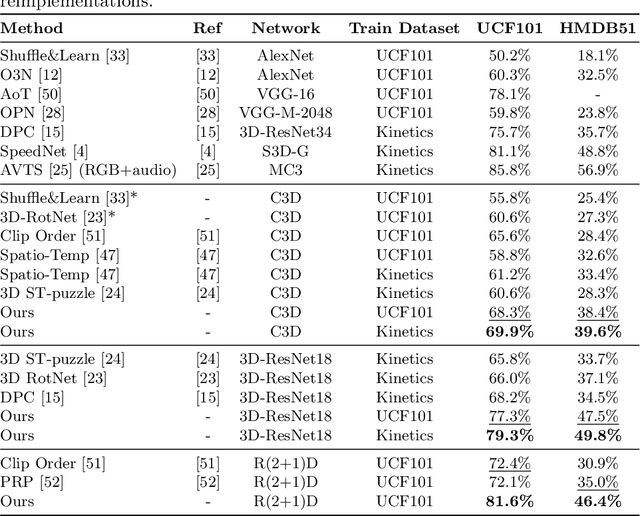
We introduce a novel self-supervised learning approach to learn representations of videos that are responsive to changes in the motion dynamics. Our representations can be learned from data without human annotation and provide a substantial boost to the training of neural networks on small labeled data sets for tasks such as action recognition, which require to accurately distinguish the motion of objects. We promote an accurate learning of motion without human annotation by training a neural network to discriminate a video sequence from its temporally transformed versions. To learn to distinguish non-trivial motions, the design of the transformations is based on two principles: 1) To define clusters of motions based on time warps of different magnitude; 2) To ensure that the discrimination is feasible only by observing and analyzing as many image frames as possible. Thus, we introduce the following transformations: forward-backward playback, random frame skipping, and uniform frame skipping. Our experiments show that networks trained with the proposed method yield representations with improved transfer performance for action recognition on UCF101 and HMDB51.
Unsupervised Generative 3D Shape Learning from Natural Images
Oct 01, 2019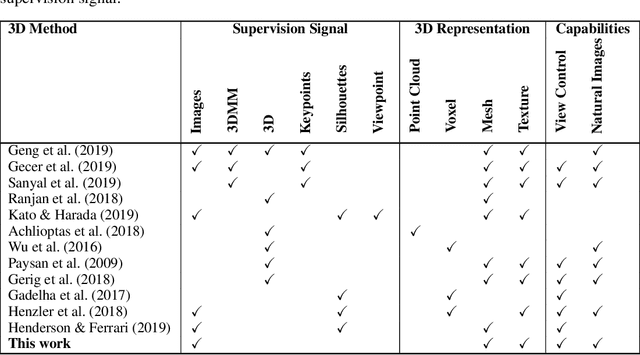
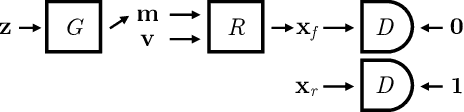


In this paper we present, to the best of our knowledge, the first method to learn a generative model of 3D shapes from natural images in a fully unsupervised way. For example, we do not use any ground truth 3D or 2D annotations, stereo video, and ego-motion during the training. Our approach follows the general strategy of Generative Adversarial Networks, where an image generator network learns to create image samples that are realistic enough to fool a discriminator network into believing that they are natural images. In contrast, in our approach the image generation is split into 2 stages. In the first stage a generator network outputs 3D objects. In the second, a differentiable renderer produces an image of the 3D objects from random viewpoints. The key observation is that a realistic 3D object should yield a realistic rendering from any plausible viewpoint. Thus, by randomizing the choice of the viewpoint our proposed training forces the generator network to learn an interpretable 3D representation disentangled from the viewpoint. In this work, a 3D representation consists of a triangle mesh and a texture map that is used to color the triangle surface by using the UV-mapping technique. We provide analysis of our learning approach, expose its ambiguities and show how to overcome them. Experimentally, we demonstrate that our method can learn realistic 3D shapes of faces by using only the natural images of the FFHQ dataset.
Learning to Have an Ear for Face Super-Resolution
Sep 27, 2019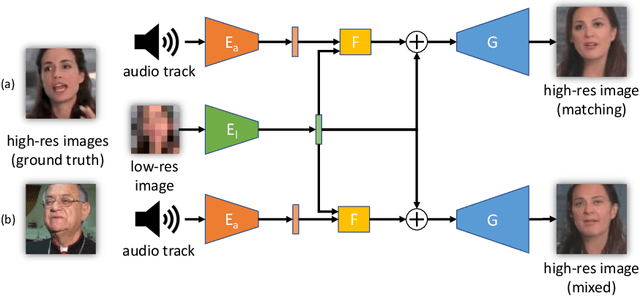
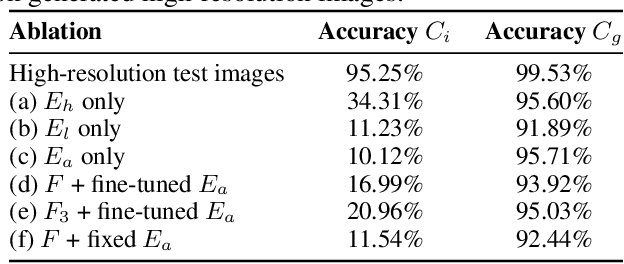
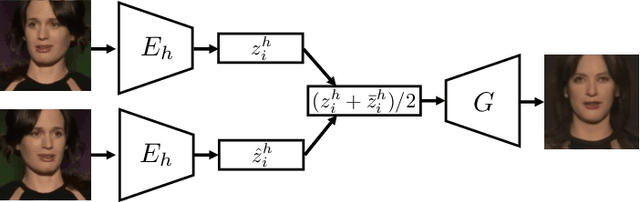
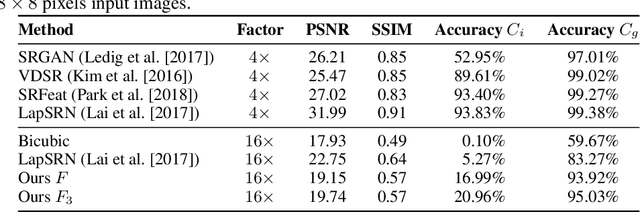
We propose a novel method to perform extreme (16x) face super-resolution by exploiting audio. Super-resolution is the task of recovering a high-resolution image from a low-resolution one. When the resolution of the input image is too low (e.g., 8x8 pixels), the loss of information is so dire that the details of the original identity have been lost. However, when the low-resolution image is extracted from a video, the audio track is also available. Because the audio carries information about the face identity, we propose to exploit it in the face reconstruction process. Towards this goal, we propose a model and a training procedure to extract information about the identity of a person from her audio track and to combine it with the information extracted from the low-resolution input image, which relates more to pose and colors of the face. We demonstrate that the combination of these two inputs yields high-resolution images that better capture the correct identity of the face. In particular, we show that audio can assist in recovering attributes such as the gender and the identity, and thus improve the correctness of the image reconstruction process. Our procedure does not make use of human annotation and thus can be easily trained with existing video datasets. Moreover, we show that our model allows one to mix low-resolution images and audio from different videos and to generate realistic faces with semantically meaningful combinations.
Learning to Extract a Video Sequence from a Single Motion-Blurred Image
Apr 11, 2018


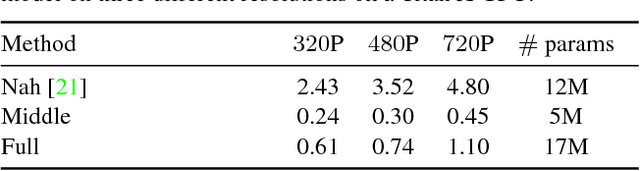
We present a method to extract a video sequence from a single motion-blurred image. Motion-blurred images are the result of an averaging process, where instant frames are accumulated over time during the exposure of the sensor. Unfortunately, reversing this process is nontrivial. Firstly, averaging destroys the temporal ordering of the frames. Secondly, the recovery of a single frame is a blind deconvolution task, which is highly ill-posed. We present a deep learning scheme that gradually reconstructs a temporal ordering by sequentially extracting pairs of frames. Our main contribution is to introduce loss functions invariant to the temporal order. This lets a neural network choose during training what frame to output among the possible combinations. We also address the ill-posedness of deblurring by designing a network with a large receptive field and implemented via resampling to achieve a higher computational efficiency. Our proposed method can successfully retrieve sharp image sequences from a single motion blurred image and can generalize well on synthetic and real datasets captured with different cameras.