 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Have an Ear for Face Super-Resolution
Paper and Code
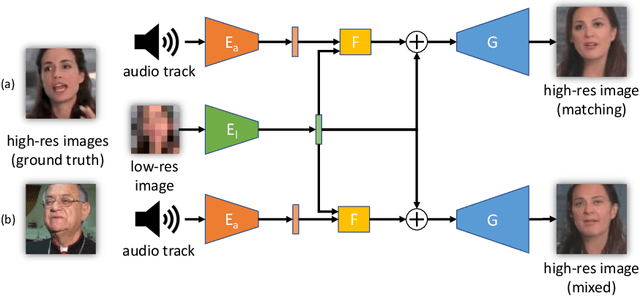
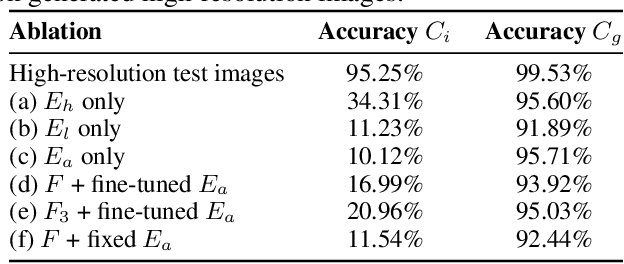
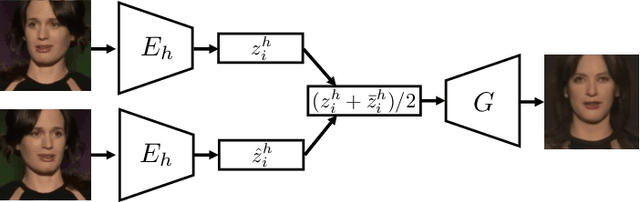
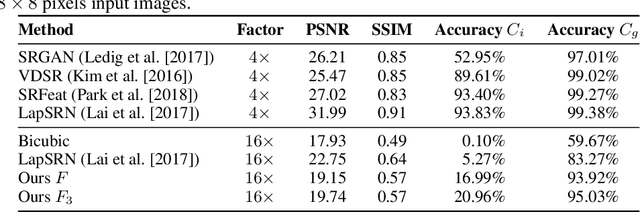
We propose a novel method to perform extreme (16x) face super-resolution by exploiting audio. Super-resolution is the task of recovering a high-resolution image from a low-resolution one. When the resolution of the input image is too low (e.g., 8x8 pixels), the loss of information is so dire that the details of the original identity have been lost. However, when the low-resolution image is extracted from a video, the audio track is also available. Because the audio carries information about the face identity, we propose to exploit it in the face reconstruction process. Towards this goal, we propose a model and a training procedure to extract information about the identity of a person from her audio track and to combine it with the information extracted from the low-resolution input image, which relates more to pose and colors of the face. We demonstrate that the combination of these two inputs yields high-resolution images that better capture the correct identity of the face. In particular, we show that audio can assist in recovering attributes such as the gender and the identity, and thus improve the correctness of the image reconstruction process. Our procedure does not make use of human annotation and thus can be easily trained with existing video datasets. Moreover, we show that our model allows one to mix low-resolution images and audio from different videos and to generate realistic faces with semantically meaningful combinations.