 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHairmony: Fairness-aware hairstyle classification
Oct 15, 2024



We present a method for prediction of a person's hairstyle from a single image. Despite growing use cases in user digitization and enrollment for virtual experiences, available methods are limited, particularly in the range of hairstyles they can capture. Human hair is extremely diverse and lacks any universally accepted description or categorization, making this a challenging task. Most current methods rely on parametric models of hair at a strand level. These approaches, while very promising, are not yet able to represent short, frizzy, coily hair and gathered hairstyles. We instead choose a classification approach which can represent the diversity of hairstyles required for a truly robust and inclusive system. Previous classification approaches have been restricted by poorly labeled data that lacks diversity, imposing constraints on the usefulness of any resulting enrollment system. We use only synthetic data to train our models. This allows for explicit control of diversity of hairstyle attributes, hair colors, facial appearance, poses, environments and other parameters. It also produces noise-free ground-truth labels. We introduce a novel hairstyle taxonomy developed in collaboration with a diverse group of domain experts which we use to balance our training data, supervise our model, and directly measure fairness. We annotate our synthetic training data and a real evaluation dataset using this taxonomy and release both to enable comparison of future hairstyle prediction approaches. We employ an architecture based on a pre-trained feature extraction network in order to improve generalization of our method to real data and predict taxonomy attributes as an auxiliary task to improve accuracy. Results show our method to be significantly more robust for challenging hairstyles than recent parametric approaches.
DigiFace-1M: 1 Million Digital Face Images for Face Recognition
Oct 05, 2022


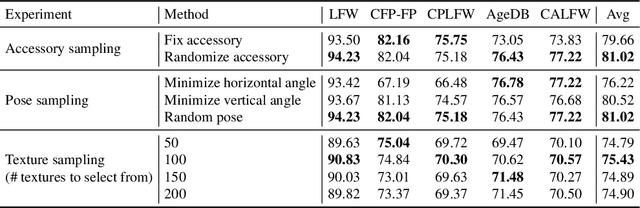
State-of-the-art face recognition models show impressive accuracy, achieving over 99.8% on Labeled Faces in the Wild (LFW) dataset. Such models are trained on large-scale datasets that contain millions of real human face images collected from the internet. Web-crawled face images are severely biased (in terms of race, lighting, make-up, etc) and often contain label noise. More importantly, the face images are collected without explicit consent, raising ethical concerns. To avoid such problems, we introduce a large-scale synthetic dataset for face recognition, obtained by rendering digital faces using a computer graphics pipeline. We first demonstrate that aggressive data augmentation can significantly reduce the synthetic-to-real domain gap. Having full control over the rendering pipeline, we also study how each attribute (e.g., variation in facial pose, accessories and textures) affects the accuracy. Compared to SynFace, a recent method trained on GAN-generated synthetic faces, we reduce the error rate on LFW by 52.5% (accuracy from 91.93% to 96.17%). By fine-tuning the network on a smaller number of real face images that could reasonably be obtained with consent, we achieve accuracy that is comparable to the methods trained on millions of real face images.