 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DTAM: Non-Rigid Tracking and Mapping via Dynamic Surface Gaussians
May 28, 2025We propose the first 4D tracking and mapping method that jointly performs camera localization and non-rigid surface reconstruction via differentiable rendering. Our approach captures 4D scenes from an online stream of color images with depth measurements or predictions by jointly optimizing scene geometry, appearance, dynamics, and camera ego-motion. Although natural environments exhibit complex non-rigid motions, 4D-SLAM remains relatively underexplored due to its inherent challenges; even with 2.5D signals, the problem is ill-posed because of the high dimensionality of the optimization space. To overcome these challenges, we first introduce a SLAM method based on Gaussian surface primitives that leverages depth signals more effectively than 3D Gaussians, thereby achieving accurate surface reconstruction. To further model non-rigid deformations, we employ a warp-field represented by a multi-layer perceptron (MLP) and introduce a novel camera pose estimation technique along with surface regularization terms that facilitate spatio-temporal reconstruction. In addition to these algorithmic challenges, a significant hurdle in 4D SLAM research is the lack of reliable ground truth and evaluation protocols, primarily due to the difficulty of 4D capture using commodity sensors. To address this, we present a novel open synthetic dataset of everyday objects with diverse motions, leveraging large-scale object models and animation modeling. In summary, we open up the modern 4D-SLAM research by introducing a novel method and evaluation protocols grounded in modern vision and rendering techniques.
U-ARE-ME: Uncertainty-Aware Rotation Estimation in Manhattan Environments
Mar 22, 2024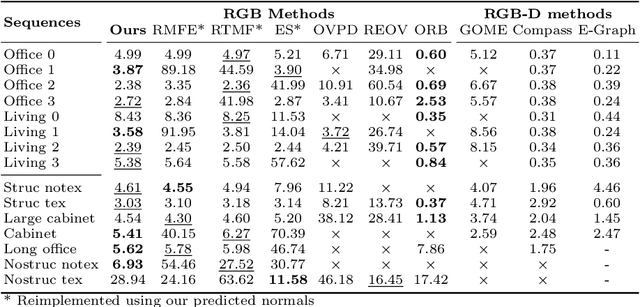


Camera rotation estimation from a single image is a challenging task, often requiring depth data and/or camera intrinsics, which are generally not available for in-the-wild videos. Although external sensors such as inertial measurement units (IMUs) can help, they often suffer from drift and are not applicable in non-inertial reference frames. We present U-ARE-ME, an algorithm that estimates camera rotation along with uncertainty from uncalibrated RGB images. Using a Manhattan World assumption, our method leverages the per-pixel geometric priors encoded in single-image surface normal predictions and performs optimisation over the SO(3) manifold. Given a sequence of images, we can use the per-frame rotation estimates and their uncertainty to perform multi-frame optimisation, achieving robustness and temporal consistency. Our experiments demonstrate that U-ARE-ME performs comparably to RGB-D methods and is more robust than sparse feature-based SLAM methods. We encourage the reader to view the accompanying video at https://callum-rhodes.github.io/U-ARE-ME for a visual overview of our method.
Rethinking Inductive Biases for Surface Normal Estimation
Mar 01, 2024
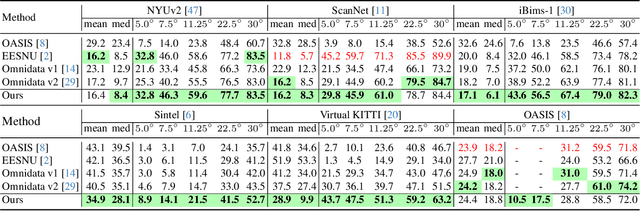

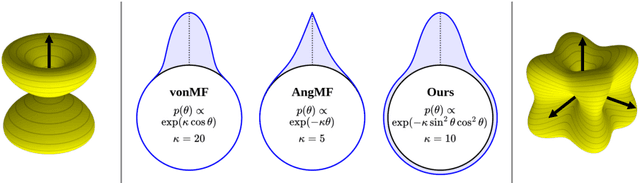
Despite the growing demand for accurate surface normal estimation models, existing methods use general-purpose dense prediction models, adopting the same inductive biases as other tasks. In this paper, we discuss the inductive biases needed for surface normal estimation and propose to (1) utilize the per-pixel ray direction and (2) encode the relationship between neighboring surface normals by learning their relative rotation. The proposed method can generate crisp - yet, piecewise smooth - predictions for challenging in-the-wild images of arbitrary resolution and aspect ratio. Compared to a recent ViT-based state-of-the-art model, our method shows a stronger generalization ability, despite being trained on an orders of magnitude smaller dataset. The code is available at https://github.com/baegwangbin/DSINE.
SuperPrimitive: Scene Reconstruction at a Primitive Level
Dec 10, 2023
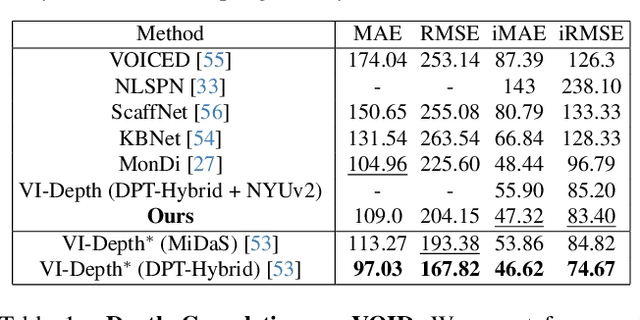
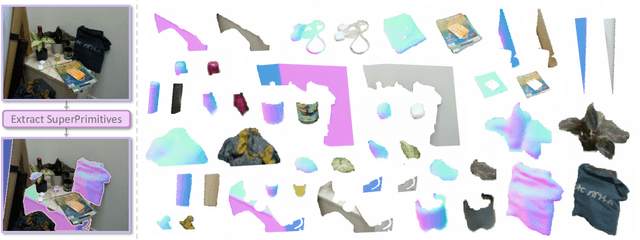
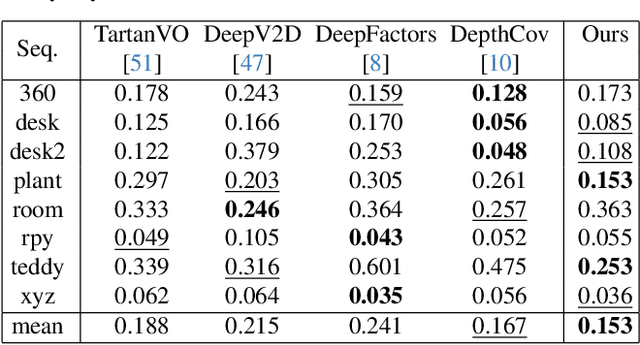
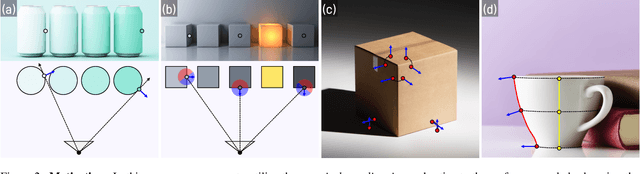
Joint camera pose and dense geometry estimation from a set of images or a monocular video remains a challenging problem due to its computational complexity and inherent visual ambiguities. Most dense incremental reconstruction systems operate directly on image pixels and solve for their 3D positions using multi-view geometry cues. Such pixel-level approaches suffer from ambiguities or violations of multi-view consistency (e.g. caused by textureless or specular surfaces). We address this issue with a new image representation which we call a SuperPrimitive. SuperPrimitives are obtained by splitting images into semantically correlated local regions and enhancing them with estimated surface normal directions, both of which are predicted by state-of-the-art single image neural networks. This provides a local geometry estimate per SuperPrimitive, while their relative positions are adjusted based on multi-view observations. We demonstrate the versatility of our new representation by addressing three 3D reconstruction tasks: depth completion, few-view structure from motion, and monocular dense visual odometry.
FOUND: Foot Optimization with Uncertain Normals for Surface Deformation Using Synthetic Data
Oct 27, 2023



Surface reconstruction from multi-view images is a challenging task, with solutions often requiring a large number of sampled images with high overlap. We seek to develop a method for few-view reconstruction, for the case of the human foot. To solve this task, we must extract rich geometric cues from RGB images, before carefully fusing them into a final 3D object. Our FOUND approach tackles this, with 4 main contributions: (i) SynFoot, a synthetic dataset of 50,000 photorealistic foot images, paired with ground truth surface normals and keypoints; (ii) an uncertainty-aware surface normal predictor trained on our synthetic dataset; (iii) an optimization scheme for fitting a generative foot model to a series of images; and (iv) a benchmark dataset of calibrated images and high resolution ground truth geometry. We show that our normal predictor outperforms all off-the-shelf equivalents significantly on real images, and our optimization scheme outperforms state-of-the-art photogrammetry pipelines, especially for a few-view setting. We release our synthetic dataset and baseline 3D scans to the research community.
IronDepth: Iterative Refinement of Single-View Depth using Surface Normal and its Uncertainty
Oct 07, 2022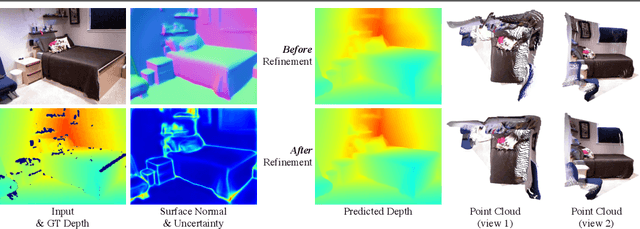
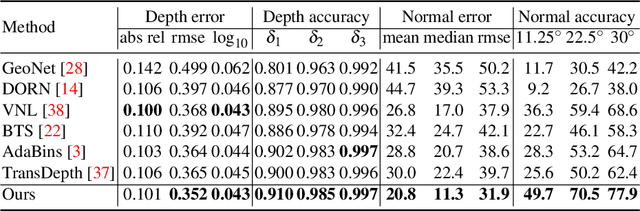
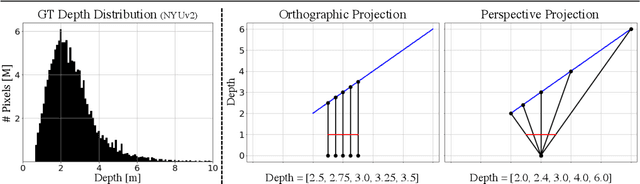
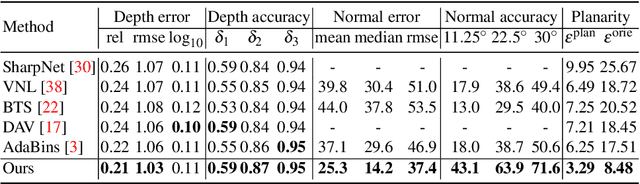
Single image surface normal estimation and depth estimation are closely related problems as the former can be calculated from the latter. However, the surface normals computed from the output of depth estimation methods are significantly less accurate than the surface normals directly estimated by networks. To reduce such discrepancy, we introduce a novel framework that uses surface normal and its uncertainty to recurrently refine the predicted depth-map. The depth of each pixel can be propagated to a query pixel, using the predicted surface normal as guidance. We thus formulate depth refinement as a classification of choosing the neighboring pixel to propagate from. Then, by propagating to sub-pixel points, we upsample the refined, low-resolution output. The proposed method shows state-of-the-art performance on NYUv2 and iBims-1 - both in terms of depth and normal. Our refinement module can also be attached to the existing depth estimation methods to improve their accuracy. We also show that our framework, only trained for depth estimation, can also be used for depth completion. The code is available at https://github.com/baegwangbin/IronDepth.
DigiFace-1M: 1 Million Digital Face Images for Face Recognition
Oct 05, 2022


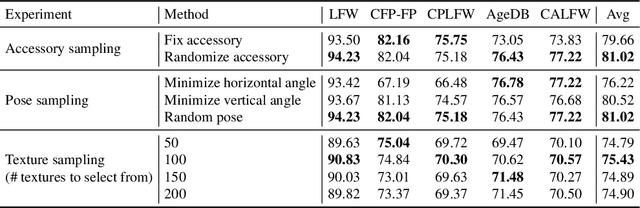
State-of-the-art face recognition models show impressive accuracy, achieving over 99.8% on Labeled Faces in the Wild (LFW) dataset. Such models are trained on large-scale datasets that contain millions of real human face images collected from the internet. Web-crawled face images are severely biased (in terms of race, lighting, make-up, etc) and often contain label noise. More importantly, the face images are collected without explicit consent, raising ethical concerns. To avoid such problems, we introduce a large-scale synthetic dataset for face recognition, obtained by rendering digital faces using a computer graphics pipeline. We first demonstrate that aggressive data augmentation can significantly reduce the synthetic-to-real domain gap. Having full control over the rendering pipeline, we also study how each attribute (e.g., variation in facial pose, accessories and textures) affects the accuracy. Compared to SynFace, a recent method trained on GAN-generated synthetic faces, we reduce the error rate on LFW by 52.5% (accuracy from 91.93% to 96.17%). By fine-tuning the network on a smaller number of real face images that could reasonably be obtained with consent, we achieve accuracy that is comparable to the methods trained on millions of real face images.
SPARC: Sparse Render-and-Compare for CAD model alignment in a single RGB image
Oct 03, 2022



Estimating 3D shapes and poses of static objects from a single image has important applications for robotics, augmented reality and digital content creation. Often this is done through direct mesh predictions which produces unrealistic, overly tessellated shapes or by formulating shape prediction as a retrieval task followed by CAD model alignment. Directly predicting CAD model poses from 2D image features is difficult and inaccurate. Some works, such as ROCA, regress normalised object coordinates and use those for computing poses. While this can produce more accurate pose estimates, predicting normalised object coordinates is susceptible to systematic failure. Leveraging efficient transformer architectures we demonstrate that a sparse, iterative, render-and-compare approach is more accurate and robust than relying on normalised object coordinates. For this we combine 2D image information including sparse depth and surface normal values which we estimate directly from the image with 3D CAD model information in early fusion. In particular, we reproject points sampled from the CAD model in an initial, random pose and compute their depth and surface normal values. This combined information is the input to a pose prediction network, SPARC-Net which we train to predict a 9 DoF CAD model pose update. The CAD model is reprojected again and the next pose update is predicted. Our alignment procedure converges after just 3 iterations, improving the state-of-the-art performance on the challenging real-world dataset ScanNet from 25.0% to 31.8% instance alignment accuracy. Code will be released at https://github.com/florianlanger/SPARC .
Multi-View Depth Estimation by Fusing Single-View Depth Probability with Multi-View Geometry
Dec 15, 2021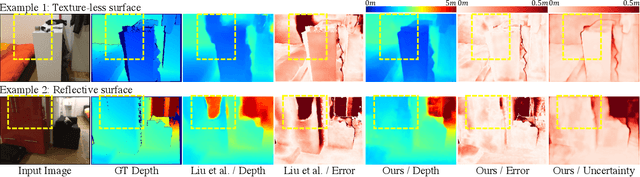

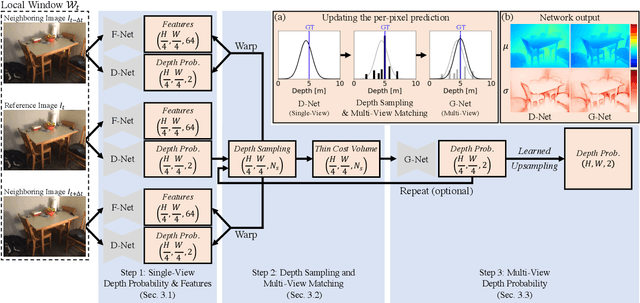
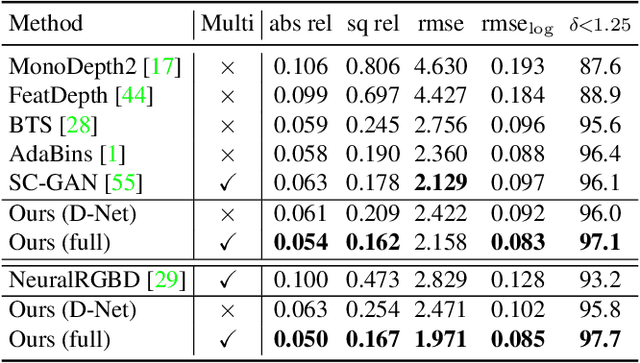
Multi-view depth estimation methods typically require the computation of a multi-view cost-volume, which leads to huge memory consumption and slow inference. Furthermore, multi-view matching can fail for texture-less surfaces, reflective surfaces and moving objects. For such failure modes, single-view depth estimation methods are often more reliable. To this end, we propose MaGNet, a novel framework for fusing single-view depth probability with multi-view geometry, to improve the accuracy, robustness and efficiency of multi-view depth estimation. For each frame, MaGNet estimates a single-view depth probability distribution, parameterized as a pixel-wise Gaussian. The distribution estimated for the reference frame is then used to sample per-pixel depth candidates. Such probabilistic sampling enables the network to achieve higher accuracy while evaluating fewer depth candidates. We also propose depth consistency weighting for the multi-view matching score, to ensure that the multi-view depth is consistent with the single-view predictions. The proposed method achieves state-of-the-art performance on ScanNet, 7-Scenes and KITTI. Qualitative evaluation demonstrates that our method is more robust against challenging artifacts such as texture-less/reflective surfaces and moving objects.
Estimating and Exploiting the Aleatoric Uncertainty in Surface Normal Estimation
Sep 20, 2021
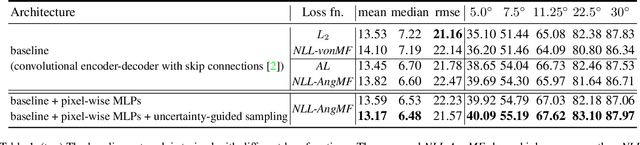

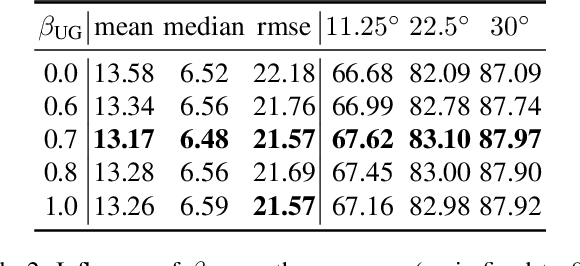
Surface normal estimation from a single image is an important task in 3D scene understanding. In this paper, we address two limitations shared by the existing methods: the inability to estimate the aleatoric uncertainty and lack of detail in the prediction. The proposed network estimates the per-pixel surface normal probability distribution. We introduce a new parameterization for the distribution, such that its negative log-likelihood is the angular loss with learned attenuation. The expected value of the angular error is then used as a measure of the aleatoric uncertainty. We also present a novel decoder framework where pixel-wise multi-layer perceptrons are trained on a subset of pixels sampled based on the estimated uncertainty. The proposed uncertainty-guided sampling prevents the bias in training towards large planar surfaces and improves the quality of prediction, especially near object boundaries and on small structures. Experimental results show that the proposed method outperforms the state-of-the-art in ScanNet and NYUv2, and that the estimated uncertainty correlates well with the prediction error. Code is available at https://github.com/baegwangbin/surface_normal_uncertainty.