 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCUS - Multi-View Foot Reconstruction From Synthetically Trained Dense Correspondences
Feb 10, 2025



Surface reconstruction from multiple, calibrated images is a challenging task - often requiring a large number of collected images with significant overlap. We look at the specific case of human foot reconstruction. As with previous successful foot reconstruction work, we seek to extract rich per-pixel geometry cues from multi-view RGB images, and fuse these into a final 3D object. Our method, FOCUS, tackles this problem with 3 main contributions: (i) SynFoot2, an extension of an existing synthetic foot dataset to include a new data type: dense correspondence with the parameterized foot model FIND; (ii) an uncertainty-aware dense correspondence predictor trained on our synthetic dataset; (iii) two methods for reconstructing a 3D surface from dense correspondence predictions: one inspired by Structure-from-Motion, and one optimization-based using the FIND model. We show that our reconstruction achieves state-of-the-art reconstruction quality in a few-view setting, performing comparably to state-of-the-art when many views are available, and runs substantially faster. We release our synthetic dataset to the research community. Code is available at: https://github.com/OllieBoyne/FOCUS
FOUND: Foot Optimization with Uncertain Normals for Surface Deformation Using Synthetic Data
Oct 27, 2023



Surface reconstruction from multi-view images is a challenging task, with solutions often requiring a large number of sampled images with high overlap. We seek to develop a method for few-view reconstruction, for the case of the human foot. To solve this task, we must extract rich geometric cues from RGB images, before carefully fusing them into a final 3D object. Our FOUND approach tackles this, with 4 main contributions: (i) SynFoot, a synthetic dataset of 50,000 photorealistic foot images, paired with ground truth surface normals and keypoints; (ii) an uncertainty-aware surface normal predictor trained on our synthetic dataset; (iii) an optimization scheme for fitting a generative foot model to a series of images; and (iv) a benchmark dataset of calibrated images and high resolution ground truth geometry. We show that our normal predictor outperforms all off-the-shelf equivalents significantly on real images, and our optimization scheme outperforms state-of-the-art photogrammetry pipelines, especially for a few-view setting. We release our synthetic dataset and baseline 3D scans to the research community.
Who Left the Dogs Out? 3D Animal Reconstruction with Expectation Maximization in the Loop
Jul 21, 2020
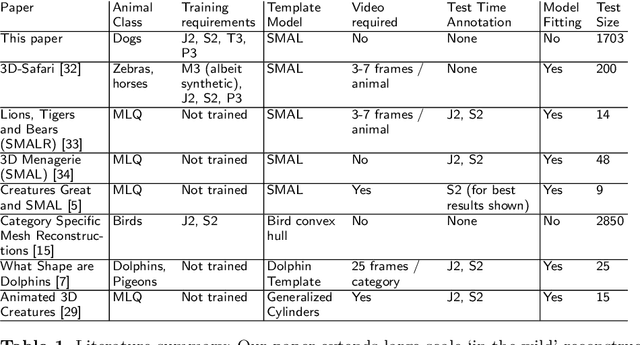
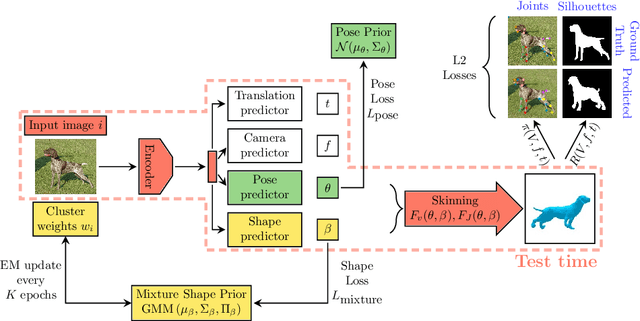
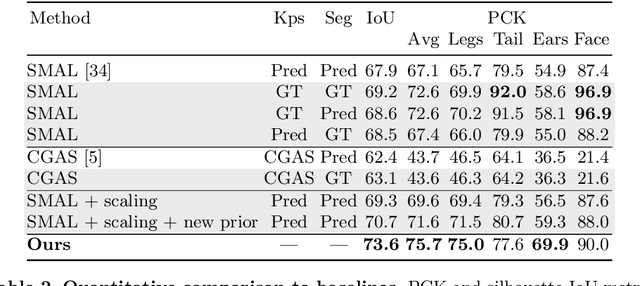
We introduce an automatic, end-to-end method for recovering the 3D pose and shape of dogs from monocular internet images. The large variation in shape between dog breeds, significant occlusion and low quality of internet images makes this a challenging problem. We learn a richer prior over shapes than previous work, which helps regularize parameter estimation. We demonstrate results on the Stanford Dog dataset, an 'in the wild' dataset of 20,580 dog images for which we have collected 2D joint and silhouette annotations to split for training and evaluation. In order to capture the large shape variety of dogs, we show that the natural variation in the 2D dataset is enough to learn a detailed 3D prior through expectation maximization (EM). As a by-product of training, we generate a new parameterized model (including limb scaling) SMBLD which we release alongside our new annotation dataset StanfordExtra to the research community.