 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOUND: Foot Optimization with Uncertain Normals for Surface Deformation Using Synthetic Data
Oct 27, 2023



Surface reconstruction from multi-view images is a challenging task, with solutions often requiring a large number of sampled images with high overlap. We seek to develop a method for few-view reconstruction, for the case of the human foot. To solve this task, we must extract rich geometric cues from RGB images, before carefully fusing them into a final 3D object. Our FOUND approach tackles this, with 4 main contributions: (i) SynFoot, a synthetic dataset of 50,000 photorealistic foot images, paired with ground truth surface normals and keypoints; (ii) an uncertainty-aware surface normal predictor trained on our synthetic dataset; (iii) an optimization scheme for fitting a generative foot model to a series of images; and (iv) a benchmark dataset of calibrated images and high resolution ground truth geometry. We show that our normal predictor outperforms all off-the-shelf equivalents significantly on real images, and our optimization scheme outperforms state-of-the-art photogrammetry pipelines, especially for a few-view setting. We release our synthetic dataset and baseline 3D scans to the research community.
Discrete neural representations for explainable anomaly detection
Dec 10, 2021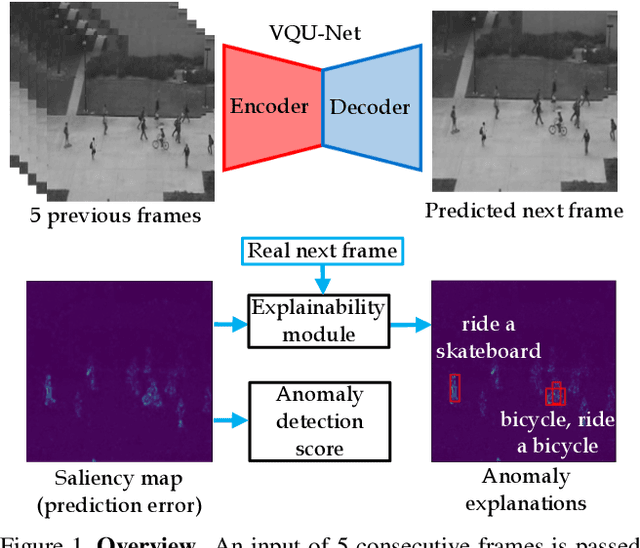
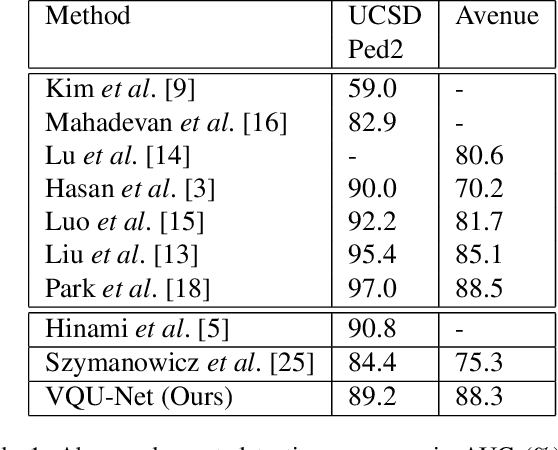
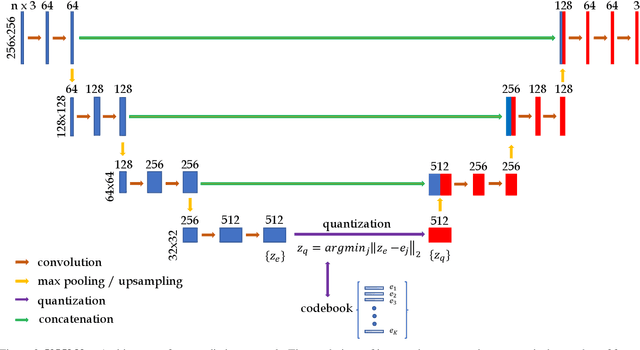
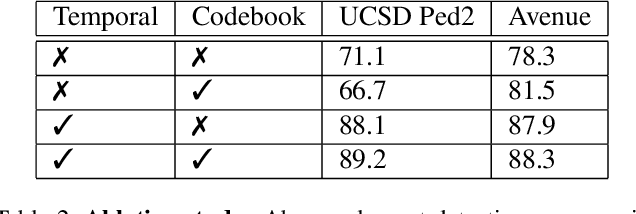
The aim of this work is to detect and automatically generate high-level explanations of anomalous events in video. Understanding the cause of an anomalous event is crucial as the required response is dependant on its nature and severity. Recent works typically use object or action classifier to detect and provide labels for anomalous events. However, this constrains detection systems to a finite set of known classes and prevents generalisation to unknown objects or behaviours. Here we show how to robustly detect anomalies without the use of object or action classifiers yet still recover the high level reason behind the event. We make the following contributions: (1) a method using saliency maps to decouple the explanation of anomalous events from object and action classifiers, (2) show how to improve the quality of saliency maps using a novel neural architecture for learning discrete representations of video by predicting future frames and (3) beat the state-of-the-art anomaly explanation methods by 60\% on a subset of the public benchmark X-MAN dataset.
X-MAN: Explaining multiple sources of anomalies in video
Jun 16, 2021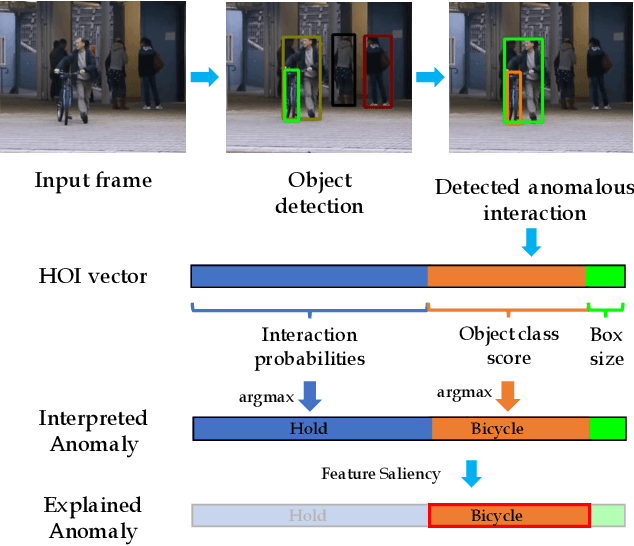
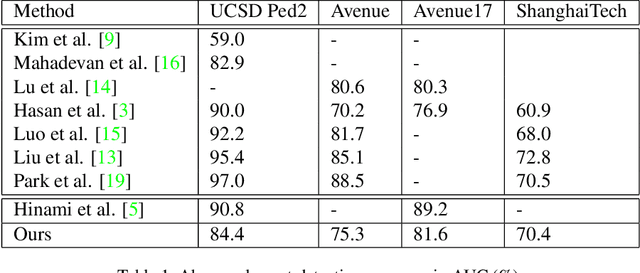
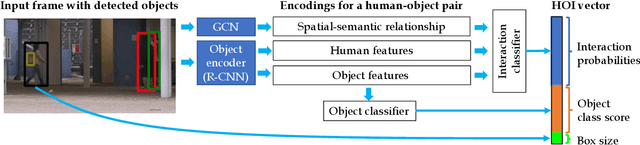
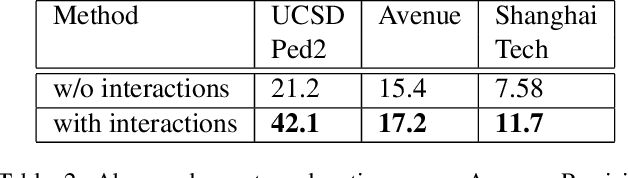
Our objective is to detect anomalies in video while also automatically explaining the reason behind the detector's response. In a practical sense, explainability is crucial for this task as the required response to an anomaly depends on its nature and severity. However, most leading methods (based on deep neural networks) are not interpretable and hide the decision making process in uninterpretable feature representations. In an effort to tackle this problem we make the following contributions: (1) we show how to build interpretable feature representations suitable for detecting anomalies with state of the art performance, (2) we propose an interpretable probabilistic anomaly detector which can describe the reason behind it's response using high level concepts, (3) we are the first to directly consider object interactions for anomaly detection and (4) we propose a new task of explaining anomalies and release a large dataset for evaluating methods on this task. Our method competes well with the state of the art on public datasets while also providing anomaly explanation based on objects and their interactions.
Who Left the Dogs Out? 3D Animal Reconstruction with Expectation Maximization in the Loop
Jul 21, 2020
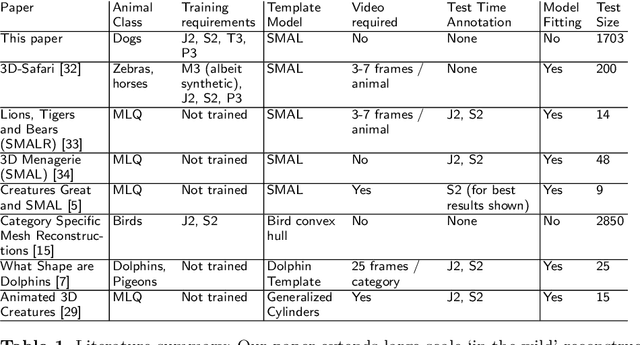
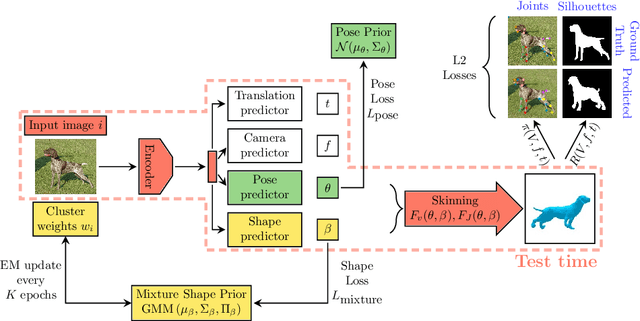
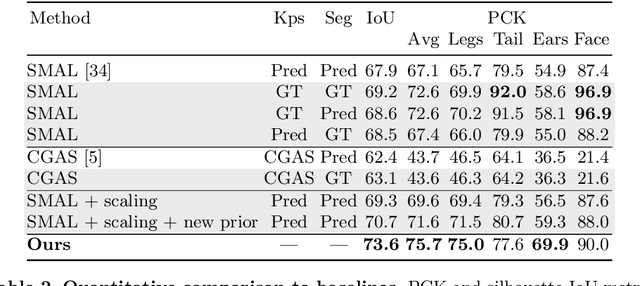
We introduce an automatic, end-to-end method for recovering the 3D pose and shape of dogs from monocular internet images. The large variation in shape between dog breeds, significant occlusion and low quality of internet images makes this a challenging problem. We learn a richer prior over shapes than previous work, which helps regularize parameter estimation. We demonstrate results on the Stanford Dog dataset, an 'in the wild' dataset of 20,580 dog images for which we have collected 2D joint and silhouette annotations to split for training and evaluation. In order to capture the large shape variety of dogs, we show that the natural variation in the 2D dataset is enough to learn a detailed 3D prior through expectation maximization (EM). As a by-product of training, we generate a new parameterized model (including limb scaling) SMBLD which we release alongside our new annotation dataset StanfordExtra to the research community.
Personalizing Human Video Pose Estimation
Jun 15, 2016
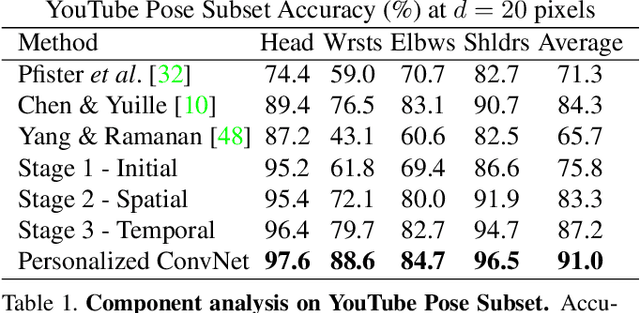

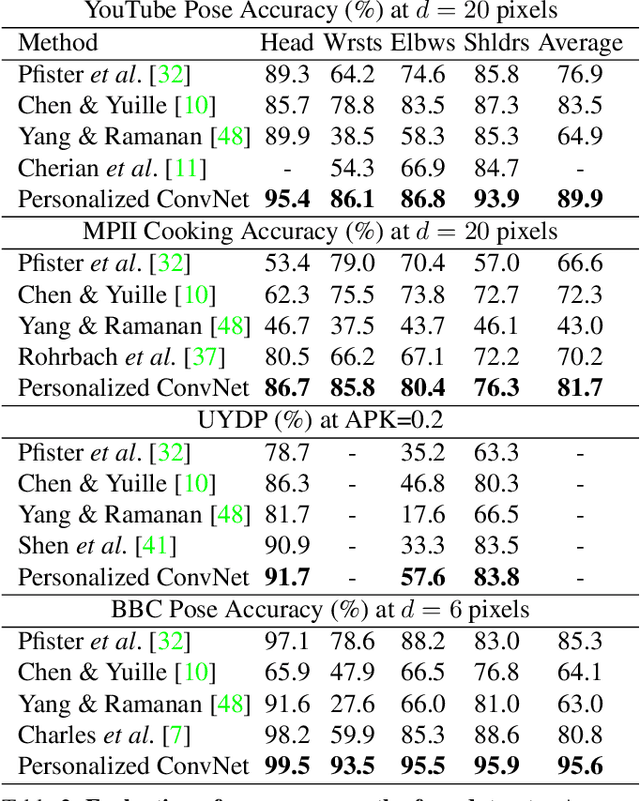
We propose a personalized ConvNet pose estimator that automatically adapts itself to the uniqueness of a person's appearance to improve pose estimation in long videos. We make the following contributions: (i) we show that given a few high-precision pose annotations, e.g. from a generic ConvNet pose estimator, additional annotations can be generated throughout the video using a combination of image-based matching for temporally distant frames, and dense optical flow for temporally local frames; (ii) we develop an occlusion aware self-evaluation model that is able to automatically select the high-quality and reject the erroneous additional annotations; and (iii) we demonstrate that these high-quality annotations can be used to fine-tune a ConvNet pose estimator and thereby personalize it to lock on to key discriminative features of the person's appearance. The outcome is a substantial improvement in the pose estimates for the target video using the personalized ConvNet compared to the original generic ConvNet. Our method outperforms the state of the art (including top ConvNet methods) by a large margin on two standard benchmarks, as well as on a new challenging YouTube video dataset. Furthermore, we show that training from the automatically generated annotations can be used to improve the performance of a generic ConvNet on other benchmarks.
Flowing ConvNets for Human Pose Estimation in Videos
Nov 08, 2015


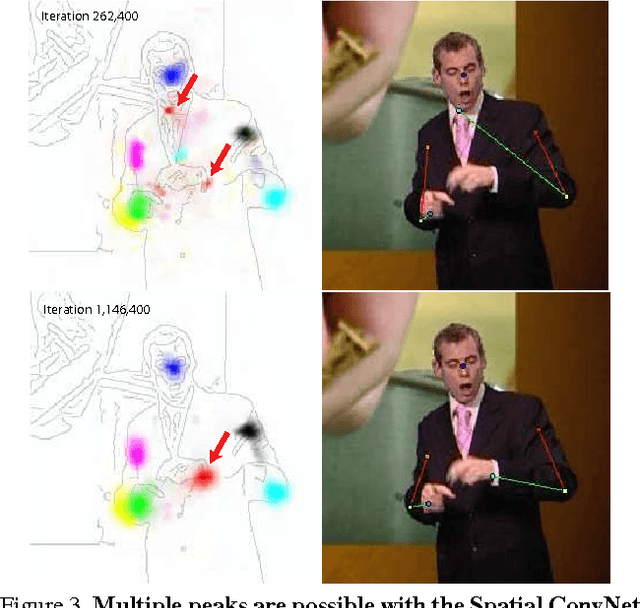
The objective of this work is human pose estimation in videos, where multiple frames are available. We investigate a ConvNet architecture that is able to benefit from temporal context by combining information across the multiple frames using optical flow. To this end we propose a network architecture with the following novelties: (i) a deeper network than previously investigated for regressing heatmaps; (ii) spatial fusion layers that learn an implicit spatial model; (iii) optical flow is used to align heatmap predictions from neighbouring frames; and (iv) a final parametric pooling layer which learns to combine the aligned heatmaps into a pooled confidence map. We show that this architecture outperforms a number of others, including one that uses optical flow solely at the input layers, one that regresses joint coordinates directly, and one that predicts heatmaps without spatial fusion. The new architecture outperforms the state of the art by a large margin on three video pose estimation datasets, including the very challenging Poses in the Wild dataset, and outperforms other deep methods that don't use a graphical model on the single-image FLIC benchmark (and also Chen & Yuille and Tompson et al. in the high precision region).