 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBolt3D: Generating 3D Scenes in Seconds
Mar 18, 2025We present a latent diffusion model for fast feed-forward 3D scene generation. Given one or more images, our model Bolt3D directly samples a 3D scene representation in less than seven seconds on a single GPU. We achieve this by leveraging powerful and scalable existing 2D diffusion network architectures to produce consistent high-fidelity 3D scene representations. To train this model, we create a large-scale multiview-consistent dataset of 3D geometry and appearance by applying state-of-the-art dense 3D reconstruction techniques to existing multiview image datasets. Compared to prior multiview generative models that require per-scene optimization for 3D reconstruction, Bolt3D reduces the inference cost by a factor of up to 300 times.
Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image
Jun 06, 2024In this paper, we propose Flash3D, a method for scene reconstruction and novel view synthesis from a single image which is both very generalisable and efficient. For generalisability, we start from a "foundation" model for monocular depth estimation and extend it to a full 3D shape and appearance reconstructor. For efficiency, we base this extension on feed-forward Gaussian Splatting. Specifically, we predict a first layer of 3D Gaussians at the predicted depth, and then add additional layers of Gaussians that are offset in space, allowing the model to complete the reconstruction behind occlusions and truncations. Flash3D is very efficient, trainable on a single GPU in a day, and thus accessible to most researchers. It achieves state-of-the-art results when trained and tested on RealEstate10k. When transferred to unseen datasets like NYU it outperforms competitors by a large margin. More impressively, when transferred to KITTI, Flash3D achieves better PSNR than methods trained specifically on that dataset. In some instances, it even outperforms recent methods that use multiple views as input. Code, models, demo, and more results are available at https://www.robots.ox.ac.uk/~vgg/research/flash3d/.
Splatter Image: Ultra-Fast Single-View 3D Reconstruction
Dec 20, 2023



We introduce the Splatter Image, an ultra-fast approach for monocular 3D object reconstruction which operates at 38 FPS. Splatter Image is based on Gaussian Splatting, which has recently brought real-time rendering, fast training, and excellent scaling to multi-view reconstruction. For the first time, we apply Gaussian Splatting in a monocular reconstruction setting. Our approach is learning-based, and, at test time, reconstruction only requires the feed-forward evaluation of a neural network. The main innovation of Splatter Image is the surprisingly straightforward design: it uses a 2D image-to-image network to map the input image to one 3D Gaussian per pixel. The resulting Gaussians thus have the form of an image, the Splatter Image. We further extend the method to incorporate more than one image as input, which we do by adding cross-view attention. Owning to the speed of the renderer (588 FPS), we can use a single GPU for training while generating entire images at each iteration in order to optimize perceptual metrics like LPIPS. On standard benchmarks, we demonstrate not only fast reconstruction but also better results than recent and much more expensive baselines in terms of PSNR, LPIPS, and other metrics.
Viewset Diffusion: (0-)Image-Conditioned 3D Generative Models from 2D Data
Jun 13, 2023

We present Viewset Diffusion: a framework for training image-conditioned 3D generative models from 2D data. Image-conditioned 3D generative models allow us to address the inherent ambiguity in single-view 3D reconstruction. Given one image of an object, there is often more than one possible 3D volume that matches the input image, because a single image never captures all sides of an object. Deterministic models are inherently limited to producing one possible reconstruction and therefore make mistakes in ambiguous settings. Modelling distributions of 3D shapes is challenging because 3D ground truth data is often not available. We propose to solve the issue of data availability by training a diffusion model which jointly denoises a multi-view image set.We constrain the output of Viewset Diffusion models to a single 3D volume per image set, guaranteeing consistent geometry. Training is done through reconstruction losses on renderings, allowing training with only three images per object. Our design of architecture and training scheme allows our model to perform 3D generation and generative, ambiguity-aware single-view reconstruction in a feed-forward manner. Project page: szymanowiczs.github.io/viewset-diffusion.
VolTeMorph: Realtime, Controllable and Generalisable Animation of Volumetric Representations
Aug 01, 2022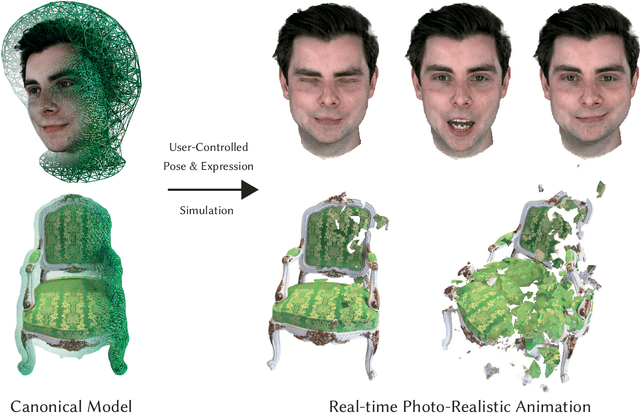
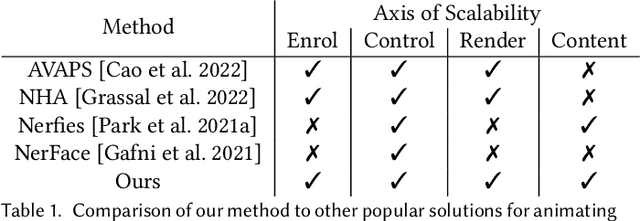
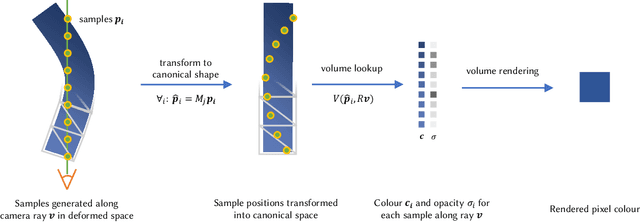
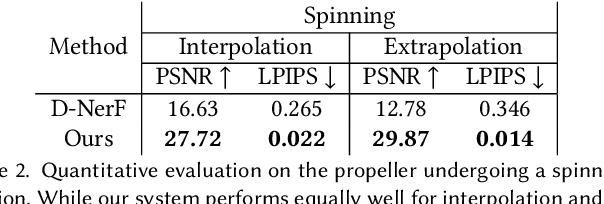
The recent increase in popularity of volumetric representations for scene reconstruction and novel view synthesis has put renewed focus on animating volumetric content at high visual quality and in real-time. While implicit deformation methods based on learned functions can produce impressive results, they are `black boxes' to artists and content creators, they require large amounts of training data to generalise meaningfully, and they do not produce realistic extrapolations outside the training data. In this work we solve these issues by introducing a volume deformation method which is real-time, easy to edit with off-the-shelf software and can extrapolate convincingly. To demonstrate the versatility of our method, we apply it in two scenarios: physics-based object deformation and telepresence where avatars are controlled using blendshapes. We also perform thorough experiments showing that our method compares favourably to both volumetric approaches combined with implicit deformation and methods based on mesh deformation.
Discrete neural representations for explainable anomaly detection
Dec 10, 2021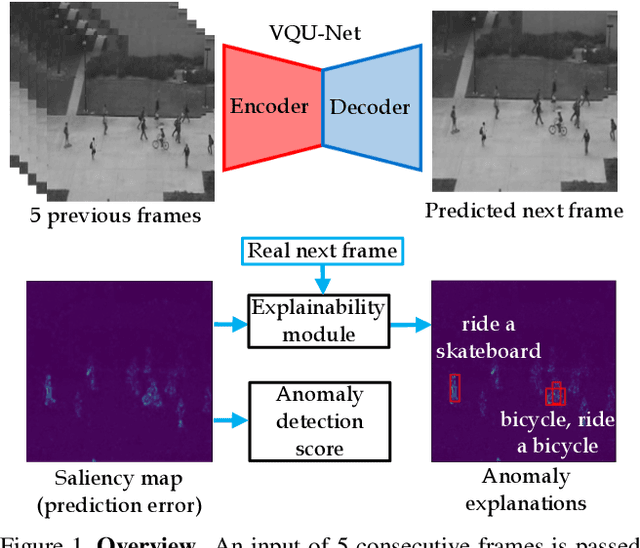
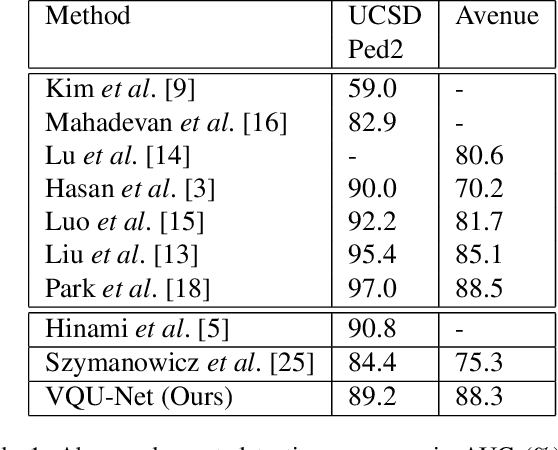
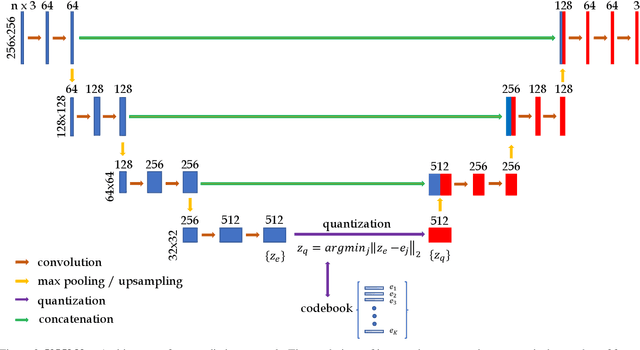
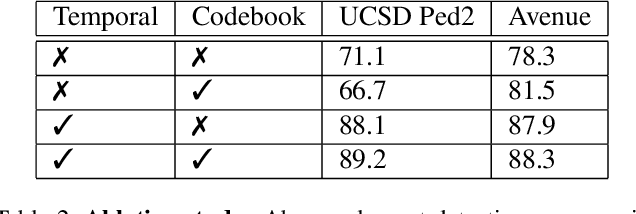
The aim of this work is to detect and automatically generate high-level explanations of anomalous events in video. Understanding the cause of an anomalous event is crucial as the required response is dependant on its nature and severity. Recent works typically use object or action classifier to detect and provide labels for anomalous events. However, this constrains detection systems to a finite set of known classes and prevents generalisation to unknown objects or behaviours. Here we show how to robustly detect anomalies without the use of object or action classifiers yet still recover the high level reason behind the event. We make the following contributions: (1) a method using saliency maps to decouple the explanation of anomalous events from object and action classifiers, (2) show how to improve the quality of saliency maps using a novel neural architecture for learning discrete representations of video by predicting future frames and (3) beat the state-of-the-art anomaly explanation methods by 60\% on a subset of the public benchmark X-MAN dataset.
X-MAN: Explaining multiple sources of anomalies in video
Jun 16, 2021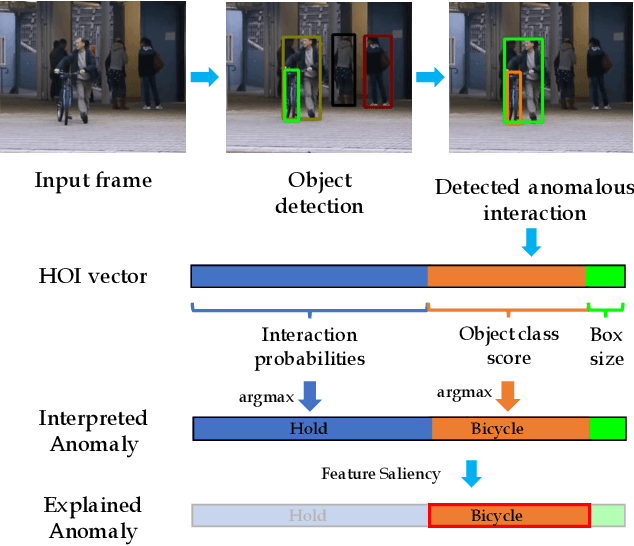
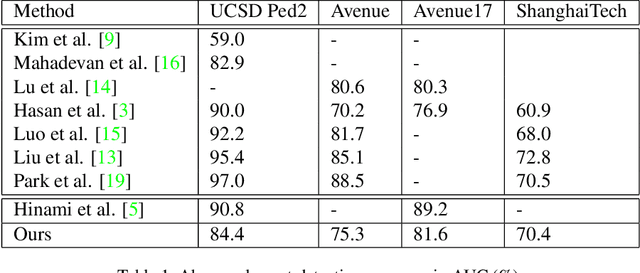
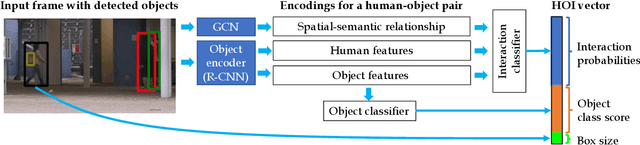
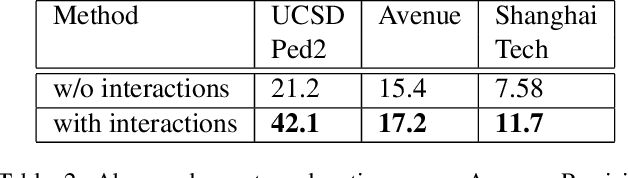
Our objective is to detect anomalies in video while also automatically explaining the reason behind the detector's response. In a practical sense, explainability is crucial for this task as the required response to an anomaly depends on its nature and severity. However, most leading methods (based on deep neural networks) are not interpretable and hide the decision making process in uninterpretable feature representations. In an effort to tackle this problem we make the following contributions: (1) we show how to build interpretable feature representations suitable for detecting anomalies with state of the art performance, (2) we propose an interpretable probabilistic anomaly detector which can describe the reason behind it's response using high level concepts, (3) we are the first to directly consider object interactions for anomaly detection and (4) we propose a new task of explaining anomalies and release a large dataset for evaluating methods on this task. Our method competes well with the state of the art on public datasets while also providing anomaly explanation based on objects and their interactions.