 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionSfM: Predicting Structure and Motion via Ray Origin and Endpoint Diffusion
May 08, 2025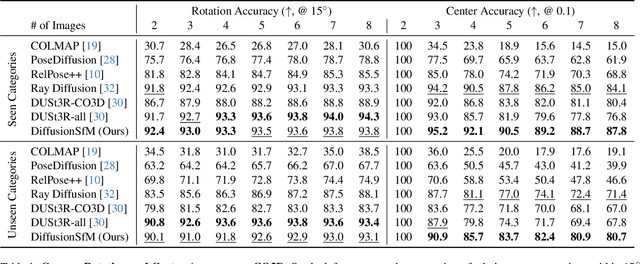
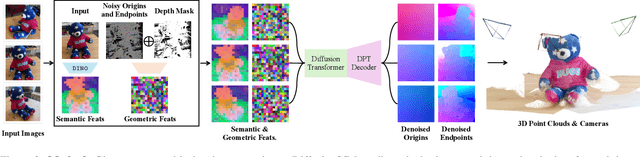

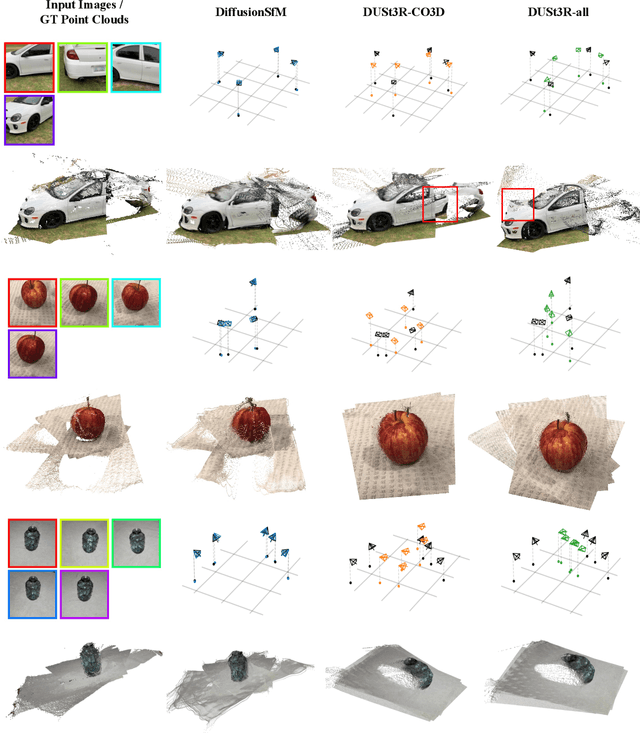
Current Structure-from-Motion (SfM) methods typically follow a two-stage pipeline, combining learned or geometric pairwise reasoning with a subsequent global optimization step. In contrast, we propose a data-driven multi-view reasoning approach that directly infers 3D scene geometry and camera poses from multi-view images. Our framework, DiffusionSfM, parameterizes scene geometry and cameras as pixel-wise ray origins and endpoints in a global frame and employs a transformer-based denoising diffusion model to predict them from multi-view inputs. To address practical challenges in training diffusion models with missing data and unbounded scene coordinates, we introduce specialized mechanisms that ensure robust learning. We empirically validate DiffusionSfM on both synthetic and real datasets, demonstrating that it outperforms classical and learning-based approaches while naturally modeling uncertainty.
Bolt3D: Generating 3D Scenes in Seconds
Mar 18, 2025We present a latent diffusion model for fast feed-forward 3D scene generation. Given one or more images, our model Bolt3D directly samples a 3D scene representation in less than seven seconds on a single GPU. We achieve this by leveraging powerful and scalable existing 2D diffusion network architectures to produce consistent high-fidelity 3D scene representations. To train this model, we create a large-scale multiview-consistent dataset of 3D geometry and appearance by applying state-of-the-art dense 3D reconstruction techniques to existing multiview image datasets. Compared to prior multiview generative models that require per-scene optimization for 3D reconstruction, Bolt3D reduces the inference cost by a factor of up to 300 times.
UnCommon Objects in 3D
Jan 13, 2025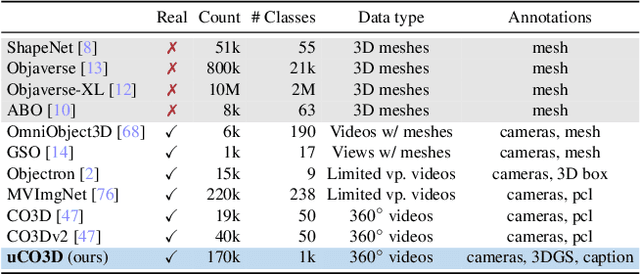
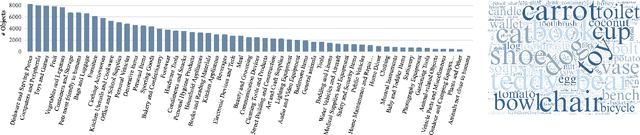


We introduce Uncommon Objects in 3D (uCO3D), a new object-centric dataset for 3D deep learning and 3D generative AI. uCO3D is the largest publicly-available collection of high-resolution videos of objects with 3D annotations that ensures full-360$^{\circ}$ coverage. uCO3D is significantly more diverse than MVImgNet and CO3Dv2, covering more than 1,000 object categories. It is also of higher quality, due to extensive quality checks of both the collected videos and the 3D annotations. Similar to analogous datasets, uCO3D contains annotations for 3D camera poses, depth maps and sparse point clouds. In addition, each object is equipped with a caption and a 3D Gaussian Splat reconstruction. We train several large 3D models on MVImgNet, CO3Dv2, and uCO3D and obtain superior results using the latter, showing that uCO3D is better for learning applications.
Can Generative Video Models Help Pose Estimation?
Dec 20, 2024Pairwise pose estimation from images with little or no overlap is an open challenge in computer vision. Existing methods, even those trained on large-scale datasets, struggle in these scenarios due to the lack of identifiable correspondences or visual overlap. Inspired by the human ability to infer spatial relationships from diverse scenes, we propose a novel approach, InterPose, that leverages the rich priors encoded within pre-trained generative video models. We propose to use a video model to hallucinate intermediate frames between two input images, effectively creating a dense, visual transition, which significantly simplifies the problem of pose estimation. Since current video models can still produce implausible motion or inconsistent geometry, we introduce a self-consistency score that evaluates the consistency of pose predictions from sampled videos. We demonstrate that our approach generalizes among three state-of-the-art video models and show consistent improvements over the state-of-the-art DUSt3R on four diverse datasets encompassing indoor, outdoor, and object-centric scenes. Our findings suggest a promising avenue for improving pose estimation models by leveraging large generative models trained on vast amounts of video data, which is more readily available than 3D data. See our project page for results: https://inter-pose.github.io/.
Cameras as Rays: Pose Estimation via Ray Diffusion
Feb 22, 2024



Estimating camera poses is a fundamental task for 3D reconstruction and remains challenging given sparse views (<10). In contrast to existing approaches that pursue top-down prediction of global parametrizations of camera extrinsics, we propose a distributed representation of camera pose that treats a camera as a bundle of rays. This representation allows for a tight coupling with spatial image features improving pose precision. We observe that this representation is naturally suited for set-level level transformers and develop a regression-based approach that maps image patches to corresponding rays. To capture the inherent uncertainties in sparse-view pose inference, we adapt this approach to learn a denoising diffusion model which allows us to sample plausible modes while improving performance. Our proposed methods, both regression- and diffusion-based, demonstrate state-of-the-art performance on camera pose estimation on CO3D while generalizing to unseen object categories and in-the-wild captures.
RelPose++: Recovering 6D Poses from Sparse-view Observations
May 08, 2023We address the task of estimating 6D camera poses from sparse-view image sets (2-8 images). This task is a vital pre-processing stage for nearly all contemporary (neural) reconstruction algorithms but remains challenging given sparse views, especially for objects with visual symmetries and texture-less surfaces. We build on the recent RelPose framework which learns a network that infers distributions over relative rotations over image pairs. We extend this approach in two key ways; first, we use attentional transformer layers to process multiple images jointly, since additional views of an object may resolve ambiguous symmetries in any given image pair (such as the handle of a mug that becomes visible in a third view). Second, we augment this network to also report camera translations by defining an appropriate coordinate system that decouples the ambiguity in rotation estimation from translation prediction. Our final system results in large improvements in 6D pose prediction over prior art on both seen and unseen object categories and also enables pose estimation and 3D reconstruction for in-the-wild objects.
SUDS: Scalable Urban Dynamic Scenes
Mar 25, 2023We extend neural radiance fields (NeRFs) to dynamic large-scale urban scenes. Prior work tends to reconstruct single video clips of short durations (up to 10 seconds). Two reasons are that such methods (a) tend to scale linearly with the number of moving objects and input videos because a separate model is built for each and (b) tend to require supervision via 3D bounding boxes and panoptic labels, obtained manually or via category-specific models. As a step towards truly open-world reconstructions of dynamic cities, we introduce two key innovations: (a) we factorize the scene into three separate hash table data structures to efficiently encode static, dynamic, and far-field radiance fields, and (b) we make use of unlabeled target signals consisting of RGB images, sparse LiDAR, off-the-shelf self-supervised 2D descriptors, and most importantly, 2D optical flow. Operationalizing such inputs via photometric, geometric, and feature-metric reconstruction losses enables SUDS to decompose dynamic scenes into the static background, individual objects, and their motions. When combined with our multi-branch table representation, such reconstructions can be scaled to tens of thousands of objects across 1.2 million frames from 1700 videos spanning geospatial footprints of hundreds of kilometers, (to our knowledge) the largest dynamic NeRF built to date. We present qualitative initial results on a variety of tasks enabled by our representations, including novel-view synthesis of dynamic urban scenes, unsupervised 3D instance segmentation, and unsupervised 3D cuboid detection. To compare to prior work, we also evaluate on KITTI and Virtual KITTI 2, surpassing state-of-the-art methods that rely on ground truth 3D bounding box annotations while being 10x quicker to train.
SparsePose: Sparse-View Camera Pose Regression and Refinement
Nov 29, 2022Camera pose estimation is a key step in standard 3D reconstruction pipelines that operate on a dense set of images of a single object or scene. However, methods for pose estimation often fail when only a few images are available because they rely on the ability to robustly identify and match visual features between image pairs. While these methods can work robustly with dense camera views, capturing a large set of images can be time-consuming or impractical. We propose SparsePose for recovering accurate camera poses given a sparse set of wide-baseline images (fewer than 10). The method learns to regress initial camera poses and then iteratively refine them after training on a large-scale dataset of objects (Co3D: Common Objects in 3D). SparsePose significantly outperforms conventional and learning-based baselines in recovering accurate camera rotations and translations. We also demonstrate our pipeline for high-fidelity 3D reconstruction using only 5-9 images of an object.
RelPose: Predicting Probabilistic Relative Rotation for Single Objects in the Wild
Aug 11, 2022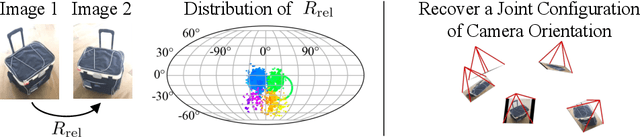
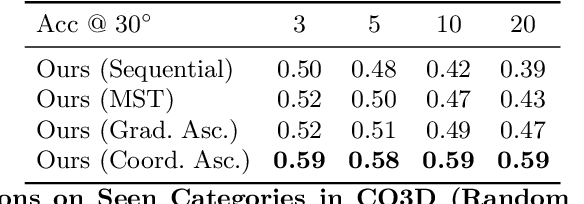

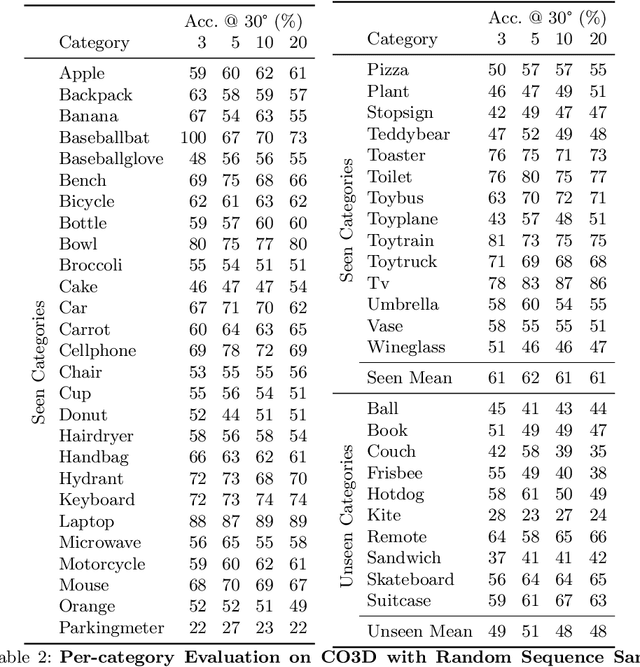
We describe a data-driven method for inferring the camera viewpoints given multiple images of an arbitrary object. This task is a core component of classic geometric pipelines such as SfM and SLAM, and also serves as a vital pre-processing requirement for contemporary neural approaches (e.g. NeRF) to object reconstruction and view synthesis. In contrast to existing correspondence-driven methods that do not perform well given sparse views, we propose a top-down prediction based approach for estimating camera viewpoints. Our key technical insight is the use of an energy-based formulation for representing distributions over relative camera rotations, thus allowing us to explicitly represent multiple camera modes arising from object symmetries or views. Leveraging these relative predictions, we jointly estimate a consistent set of camera rotations from multiple images. We show that our approach outperforms state-of-the-art SfM and SLAM methods given sparse images on both seen and unseen categories. Further, our probabilistic approach significantly outperforms directly regressing relative poses, suggesting that modeling multimodality is important for coherent joint reconstruction. We demonstrate that our system can be a stepping stone toward in-the-wild reconstruction from multi-view datasets. The project page with code and videos can be found at https://jasonyzhang.com/relpose.
NeRS: Neural Reflectance Surfaces for Sparse-view 3D Reconstruction in the Wild
Oct 18, 2021
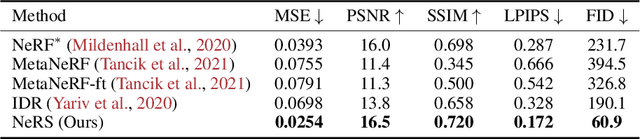
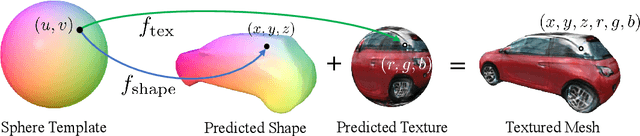

Recent history has seen a tremendous growth of work exploring implicit representations of geometry and radiance, popularized through Neural Radiance Fields (NeRF). Such works are fundamentally based on a (implicit) volumetric representation of occupancy, allowing them to model diverse scene structure including translucent objects and atmospheric obscurants. But because the vast majority of real-world scenes are composed of well-defined surfaces, we introduce a surface analog of such implicit models called Neural Reflectance Surfaces (NeRS). NeRS learns a neural shape representation of a closed surface that is diffeomorphic to a sphere, guaranteeing water-tight reconstructions. Even more importantly, surface parameterizations allow NeRS to learn (neural) bidirectional surface reflectance functions (BRDFs) that factorize view-dependent appearance into environmental illumination, diffuse color (albedo), and specular "shininess." Finally, rather than illustrating our results on synthetic scenes or controlled in-the-lab capture, we assemble a novel dataset of multi-view images from online marketplaces for selling goods. Such "in-the-wild" multi-view image sets pose a number of challenges, including a small number of views with unknown/rough camera estimates. We demonstrate that surface-based neural reconstructions enable learning from such data, outperforming volumetric neural rendering-based reconstructions. We hope that NeRS serves as a first step toward building scalable, high-quality libraries of real-world shape, materials, and illumination. The project page with code and video visualizations can be found at https://jasonyzhang.com/ners.