 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionHarmonizer: Bridging Neural Reconstruction and Photorealistic Simulation with Online Diffusion Enhancer
Mar 05, 2026Simulation is essential to the development and evaluation of autonomous robots such as self-driving vehicles. Neural reconstruction is emerging as a promising solution as it enables simulating a wide variety of scenarios from real-world data alone in an automated and scalable way. However, while methods such as NeRF and 3D Gaussian Splatting can produce visually compelling results, they often exhibit artifacts particularly when rendering novel views, and fail to realistically integrate inserted dynamic objects, especially when they were captured from different scenes. To overcome these limitations, we introduce DiffusionHarmonizer, an online generative enhancement framework that transforms renderings from such imperfect scenes into temporally consistent outputs while improving their realism. At its core is a single-step temporally-conditioned enhancer that is converted from a pretrained multi-step image diffusion model, capable of running in online simulators on a single GPU. The key to training it effectively is a custom data curation pipeline that constructs synthetic-real pairs emphasizing appearance harmonization, artifact correction, and lighting realism. The result is a scalable system that significantly elevates simulation fidelity in both research and production environments.
ArtiFixer: Enhancing and Extending 3D Reconstruction with Auto-Regressive Diffusion Models
Feb 28, 2026Per-scene optimization methods such as 3D Gaussian Splatting provide state-of-the-art novel view synthesis quality but extrapolate poorly to under-observed areas. Methods that leverage generative priors to correct artifacts in these areas hold promise but currently suffer from two shortcomings. The first is scalability, as existing methods use image diffusion models or bidirectional video models that are limited in the number of views they can generate in a single pass (and thus require a costly iterative distillation process for consistency). The second is quality itself, as generators used in prior work tend to produce outputs that are inconsistent with existing scene content and fail entirely in completely unobserved regions. To solve these, we propose a two-stage pipeline that leverages two key insights. First, we train a powerful bidirectional generative model with a novel opacity mixing strategy that encourages consistency with existing observations while retaining the model's ability to extrapolate novel content in unseen areas. Second, we distill it into a causal auto-regressive model that generates hundreds of frames in a single pass. This model can directly produce novel views or serve as pseudo-supervision to improve the underlying 3D representation in a simple and highly efficient manner. We evaluate our method extensively and demonstrate that it can generate plausible reconstructions in scenarios where existing approaches fail completely. When measured on commonly benchmarked datasets, we outperform existing all existing baselines by a wide margin, exceeding prior state-of-the-art methods by 1-3 dB PSNR.
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
Mar 03, 2025Neural Radiance Fields and 3D Gaussian Splatting have revolutionized 3D reconstruction and novel-view synthesis task. However, achieving photorealistic rendering from extreme novel viewpoints remains challenging, as artifacts persist across representations. In this work, we introduce Difix3D+, a novel pipeline designed to enhance 3D reconstruction and novel-view synthesis through single-step diffusion models. At the core of our approach is Difix, a single-step image diffusion model trained to enhance and remove artifacts in rendered novel views caused by underconstrained regions of the 3D representation. Difix serves two critical roles in our pipeline. First, it is used during the reconstruction phase to clean up pseudo-training views that are rendered from the reconstruction and then distilled back into 3D. This greatly enhances underconstrained regions and improves the overall 3D representation quality. More importantly, Difix also acts as a neural enhancer during inference, effectively removing residual artifacts arising from imperfect 3D supervision and the limited capacity of current reconstruction models. Difix3D+ is a general solution, a single model compatible with both NeRF and 3DGS representations, and it achieves an average 2$\times$ improvement in FID score over baselines while maintaining 3D consistency.
SpecNeRF: Gaussian Directional Encoding for Specular Reflections
Dec 20, 2023



Neural radiance fields have achieved remarkable performance in modeling the appearance of 3D scenes. However, existing approaches still struggle with the view-dependent appearance of glossy surfaces, especially under complex lighting of indoor environments. Unlike existing methods, which typically assume distant lighting like an environment map, we propose a learnable Gaussian directional encoding to better model the view-dependent effects under near-field lighting conditions. Importantly, our new directional encoding captures the spatially-varying nature of near-field lighting and emulates the behavior of prefiltered environment maps. As a result, it enables the efficient evaluation of preconvolved specular color at any 3D location with varying roughness coefficients. We further introduce a data-driven geometry prior that helps alleviate the shape radiance ambiguity in reflection modeling. We show that our Gaussian directional encoding and geometry prior significantly improve the modeling of challenging specular reflections in neural radiance fields, which helps decompose appearance into more physically meaningful components.
HybridNeRF: Efficient Neural Rendering via Adaptive Volumetric Surfaces
Dec 05, 2023Neural radiance fields provide state-of-the-art view synthesis quality but tend to be slow to render. One reason is that they make use of volume rendering, thus requiring many samples (and model queries) per ray at render time. Although this representation is flexible and easy to optimize, most real-world objects can be modeled more efficiently with surfaces instead of volumes, requiring far fewer samples per ray. This observation has spurred considerable progress in surface representations such as signed distance functions, but these may struggle to model semi-opaque and thin structures. We propose a method, HybridNeRF, that leverages the strengths of both representations by rendering most objects as surfaces while modeling the (typically) small fraction of challenging regions volumetrically. We evaluate HybridNeRF against the challenging Eyeful Tower dataset along with other commonly used view synthesis datasets. When comparing to state-of-the-art baselines, including recent rasterization-based approaches, we improve error rates by 15-30% while achieving real-time framerates (at least 36 FPS) for virtual-reality resolutions (2Kx2K).
PyNeRF: Pyramidal Neural Radiance Fields
Nov 30, 2023Neural Radiance Fields (NeRFs) can be dramatically accelerated by spatial grid representations. However, they do not explicitly reason about scale and so introduce aliasing artifacts when reconstructing scenes captured at different camera distances. Mip-NeRF and its extensions propose scale-aware renderers that project volumetric frustums rather than point samples but such approaches rely on positional encodings that are not readily compatible with grid methods. We propose a simple modification to grid-based models by training model heads at different spatial grid resolutions. At render time, we simply use coarser grids to render samples that cover larger volumes. Our method can be easily applied to existing accelerated NeRF methods and significantly improves rendering quality (reducing error rates by 20-90% across synthetic and unbounded real-world scenes) while incurring minimal performance overhead (as each model head is quick to evaluate). Compared to Mip-NeRF, we reduce error rates by 20% while training over 60x faster.
SUDS: Scalable Urban Dynamic Scenes
Mar 25, 2023We extend neural radiance fields (NeRFs) to dynamic large-scale urban scenes. Prior work tends to reconstruct single video clips of short durations (up to 10 seconds). Two reasons are that such methods (a) tend to scale linearly with the number of moving objects and input videos because a separate model is built for each and (b) tend to require supervision via 3D bounding boxes and panoptic labels, obtained manually or via category-specific models. As a step towards truly open-world reconstructions of dynamic cities, we introduce two key innovations: (a) we factorize the scene into three separate hash table data structures to efficiently encode static, dynamic, and far-field radiance fields, and (b) we make use of unlabeled target signals consisting of RGB images, sparse LiDAR, off-the-shelf self-supervised 2D descriptors, and most importantly, 2D optical flow. Operationalizing such inputs via photometric, geometric, and feature-metric reconstruction losses enables SUDS to decompose dynamic scenes into the static background, individual objects, and their motions. When combined with our multi-branch table representation, such reconstructions can be scaled to tens of thousands of objects across 1.2 million frames from 1700 videos spanning geospatial footprints of hundreds of kilometers, (to our knowledge) the largest dynamic NeRF built to date. We present qualitative initial results on a variety of tasks enabled by our representations, including novel-view synthesis of dynamic urban scenes, unsupervised 3D instance segmentation, and unsupervised 3D cuboid detection. To compare to prior work, we also evaluate on KITTI and Virtual KITTI 2, surpassing state-of-the-art methods that rely on ground truth 3D bounding box annotations while being 10x quicker to train.
Mega-NeRF: Scalable Construction of Large-Scale NeRFs for Virtual Fly-Throughs
Dec 20, 2021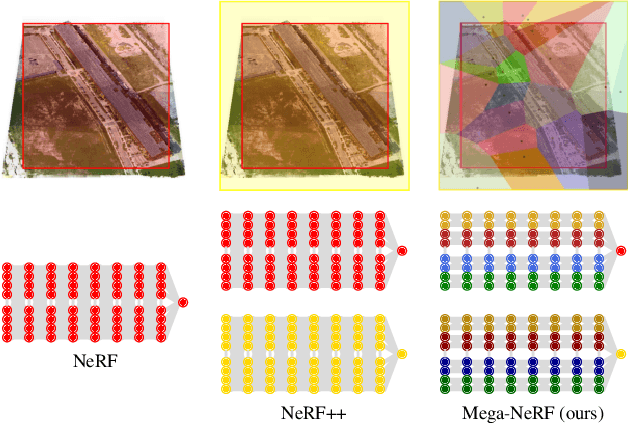
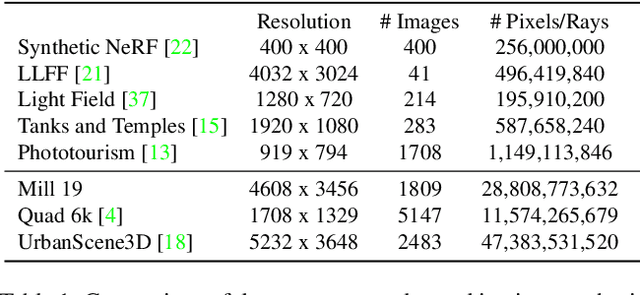
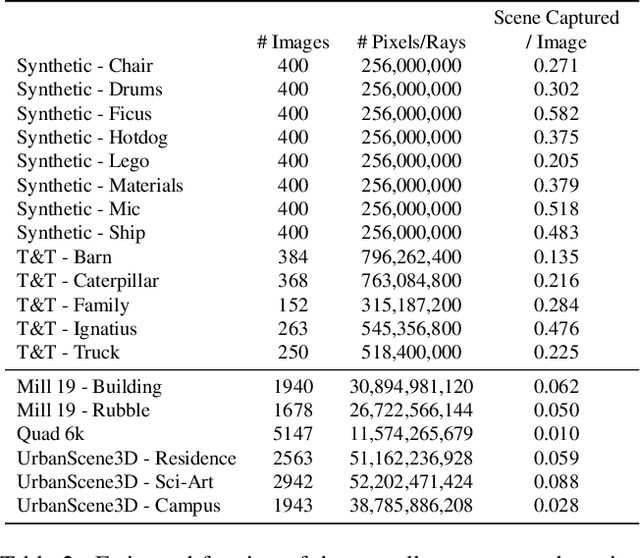

We explore how to leverage neural radiance fields (NeRFs) to build interactive 3D environments from large-scale visual captures spanning buildings or even multiple city blocks collected primarily from drone data. In contrast to the single object scenes against which NeRFs have been traditionally evaluated, this setting poses multiple challenges including (1) the need to incorporate thousands of images with varying lighting conditions, all of which capture only a small subset of the scene, (2) prohibitively high model capacity and ray sampling requirements beyond what can be naively trained on a single GPU, and (3) an arbitrarily large number of possible viewpoints that make it unfeasible to precompute all relevant information beforehand (as real-time NeRF renderers typically do). To address these challenges, we begin by analyzing visibility statistics for large-scale scenes, motivating a sparse network structure where parameters are specialized to different regions of the scene. We introduce a simple geometric clustering algorithm that partitions training images (or rather pixels) into different NeRF submodules that can be trained in parallel. We evaluate our approach across scenes taken from the Quad 6k and UrbanScene3D datasets as well as against our own drone footage and show a 3x training speedup while improving PSNR by over 11% on average. We subsequently perform an empirical evaluation of recent NeRF fast renderers on top of Mega-NeRF and introduce a novel method that exploits temporal coherence. Our technique achieves a 40x speedup over conventional NeRF rendering while remaining within 0.5 db in PSNR quality, exceeding the fidelity of existing fast renderers.