 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMega-NeRF: Scalable Construction of Large-Scale NeRFs for Virtual Fly-Throughs
Paper and Code
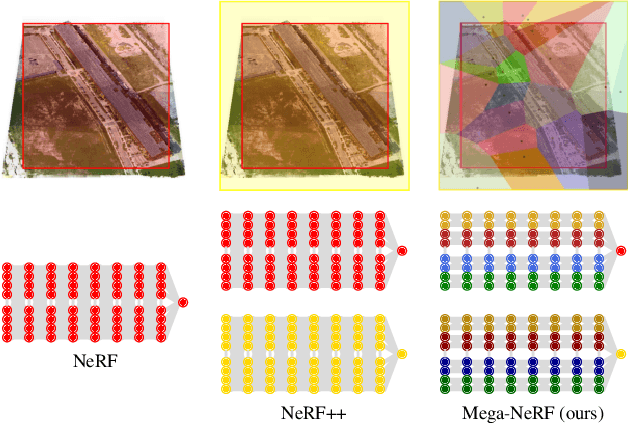
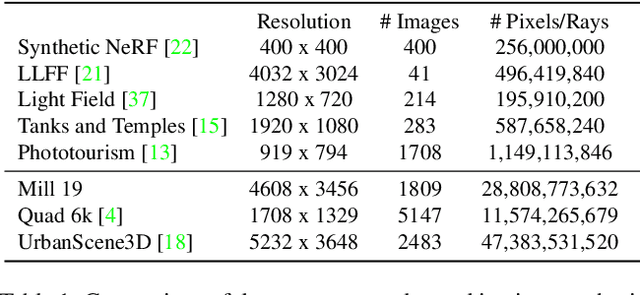
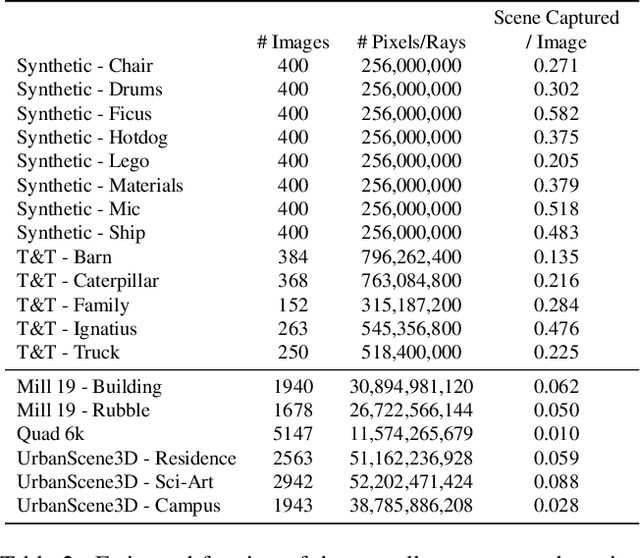

We explore how to leverage neural radiance fields (NeRFs) to build interactive 3D environments from large-scale visual captures spanning buildings or even multiple city blocks collected primarily from drone data. In contrast to the single object scenes against which NeRFs have been traditionally evaluated, this setting poses multiple challenges including (1) the need to incorporate thousands of images with varying lighting conditions, all of which capture only a small subset of the scene, (2) prohibitively high model capacity and ray sampling requirements beyond what can be naively trained on a single GPU, and (3) an arbitrarily large number of possible viewpoints that make it unfeasible to precompute all relevant information beforehand (as real-time NeRF renderers typically do). To address these challenges, we begin by analyzing visibility statistics for large-scale scenes, motivating a sparse network structure where parameters are specialized to different regions of the scene. We introduce a simple geometric clustering algorithm that partitions training images (or rather pixels) into different NeRF submodules that can be trained in parallel. We evaluate our approach across scenes taken from the Quad 6k and UrbanScene3D datasets as well as against our own drone footage and show a 3x training speedup while improving PSNR by over 11% on average. We subsequently perform an empirical evaluation of recent NeRF fast renderers on top of Mega-NeRF and introduce a novel method that exploits temporal coherence. Our technique achieves a 40x speedup over conventional NeRF rendering while remaining within 0.5 db in PSNR quality, exceeding the fidelity of existing fast renderers.